Hoe beschrijvende statistieken voor variabelen in spss te berekenen
De beste manier om een dataset te begrijpen is door beschrijvende statistieken te berekenen voor de variabelen in de dataset. Er zijn drie veel voorkomende vormen van beschrijvende statistiek:
1. Samenvattende statistieken – Getallen die een variabele samenvatten met behulp van één enkel getal. Voorbeelden zijn onder meer gemiddelde, mediaan, standaarddeviatie en bereik.
2. Tabellen – Tabellen kunnen ons helpen begrijpen hoe gegevens worden gedistribueerd. Een voorbeeld is een frequentietabel, die ons vertelt hoeveel datawaarden binnen bepaalde bereiken vallen.
3. Grafieken – Deze helpen ons gegevens te visualiseren. Een voorbeeld zou een histogram zijn.
In deze tutorial wordt uitgelegd hoe u beschrijvende statistieken voor variabelen in SPSS kunt berekenen.
Voorbeeld: beschrijvende statistiek in SPSS
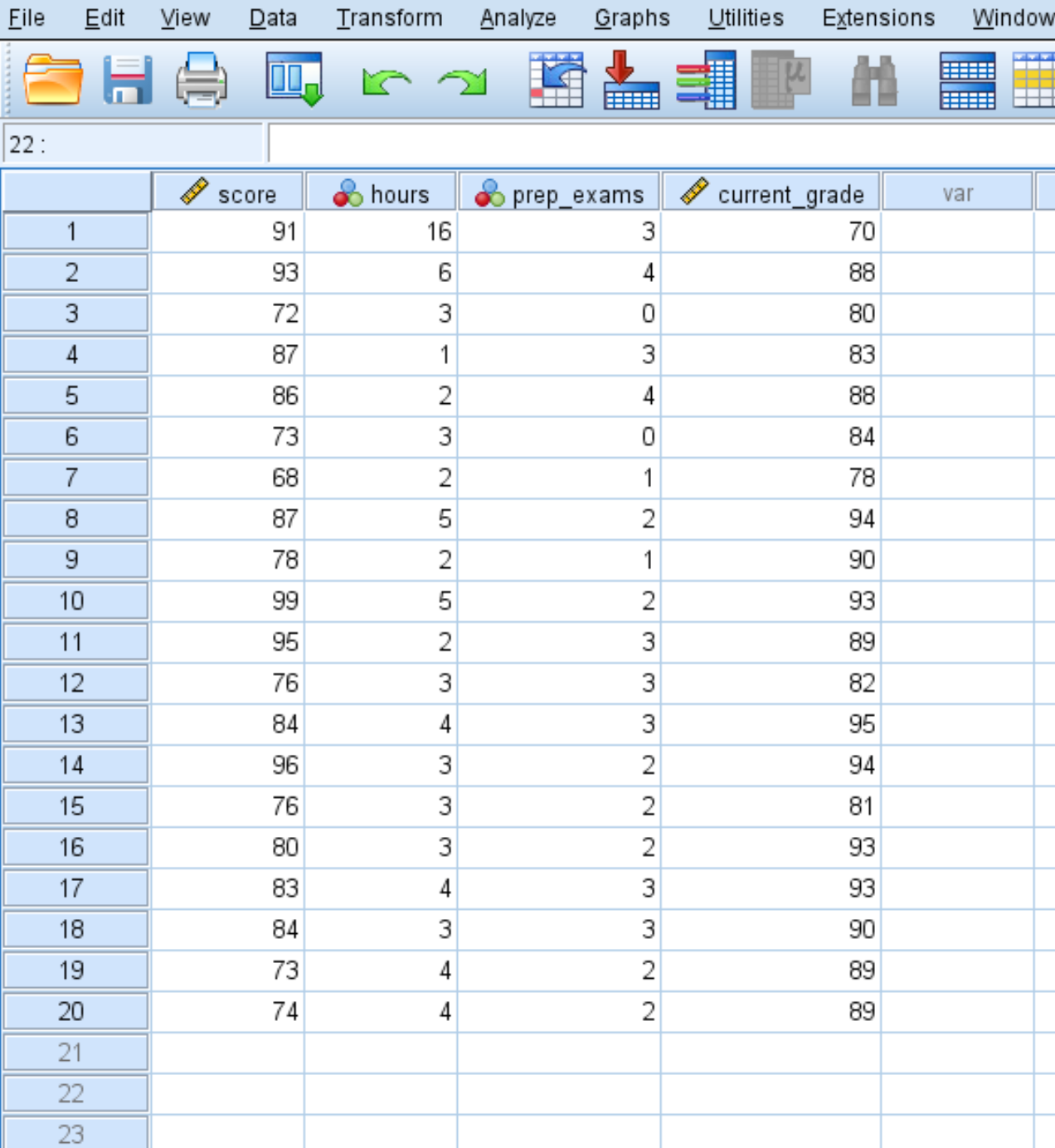
Stel dat we de volgende dataset hebben met vier variabelen voor 20 leerlingen in een bepaalde klas:
- Examenresultaat
- Uren besteed aan studeren
- Voorbereidende examens geslaagd
- Huidig cijfer in de klas
Hier leest u hoe u beschrijvende statistieken voor elk van deze vier variabelen berekent:
Samenvattende statistieken
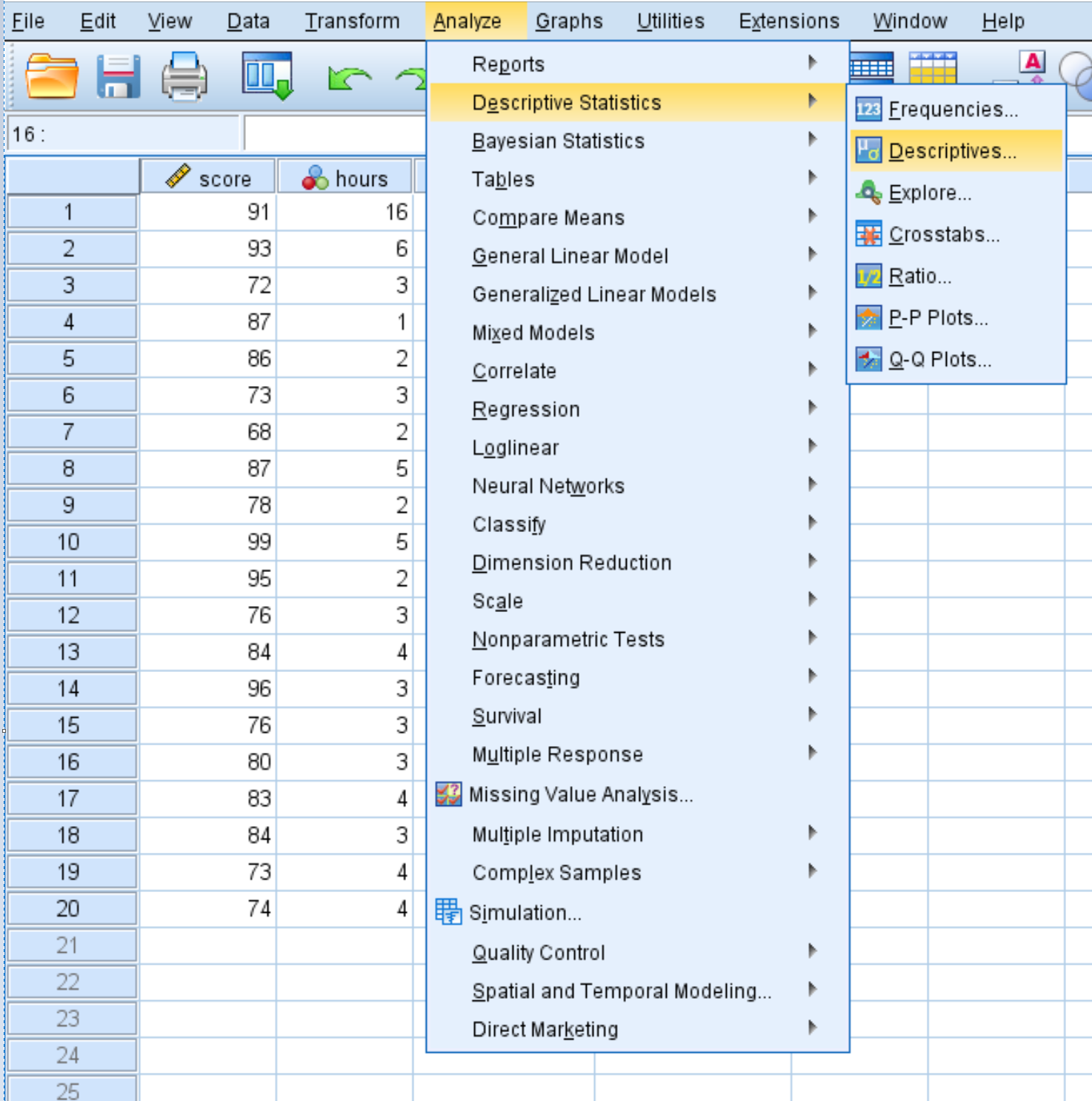
Om samenvattende statistieken voor elke variabele te berekenen, klikt u op het tabblad Analyseren , vervolgens op Beschrijvende statistieken en vervolgens op Beschrijvende gegevens :
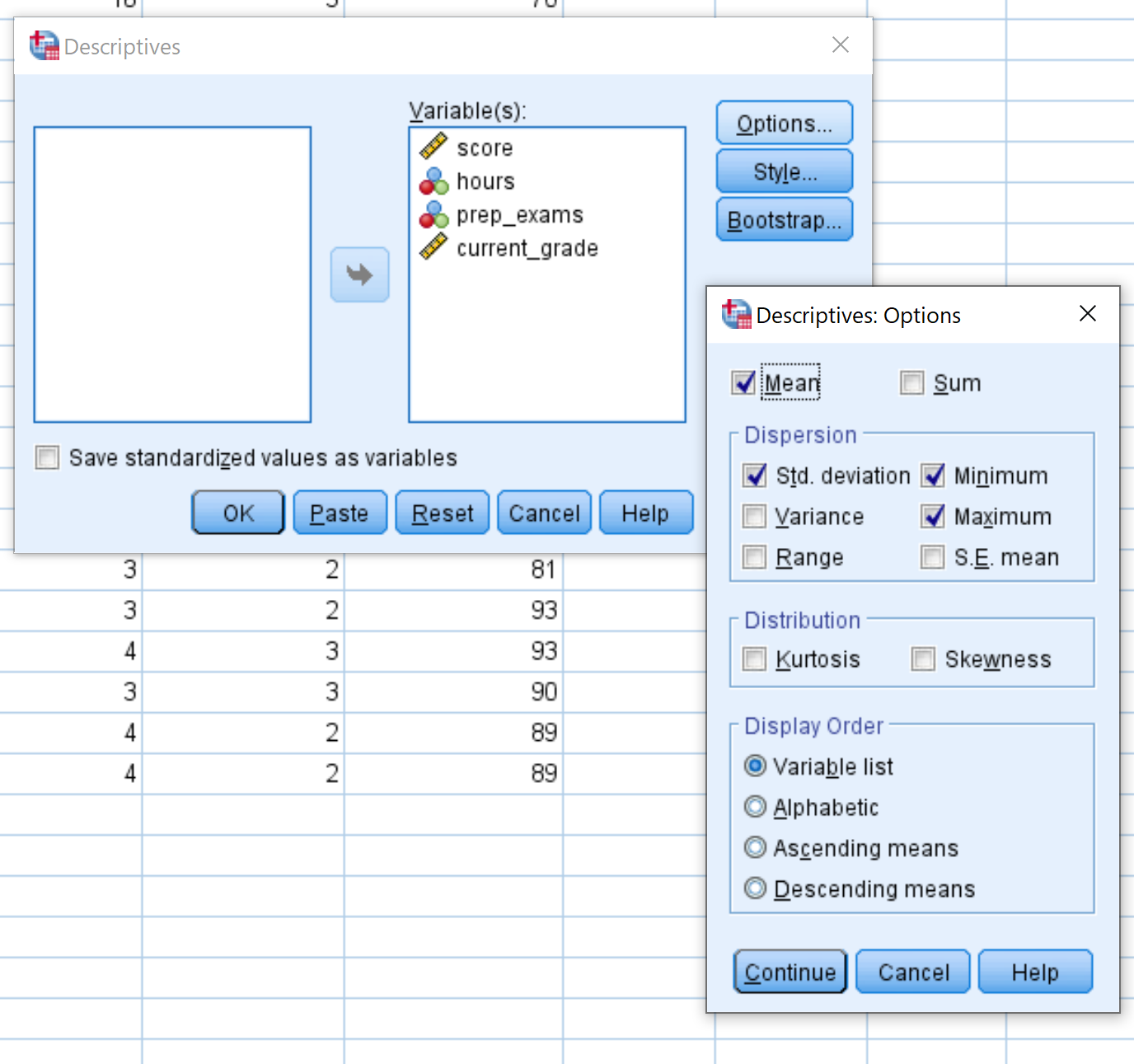
In het nieuwe venster dat verschijnt, sleept u elk van de vier variabelen naar het gebied met de naam Variabele(n). Als u wilt, kunt u op de knop Opties klikken en de specifieke beschrijvende statistieken selecteren die u door SPSS wilt laten berekenen. Klik vervolgens op Doorgaan . Klik vervolgens op OK .
Zodra u op OK klikt, verschijnt er een tabel met de volgende beschrijvende statistieken voor elke variabele:
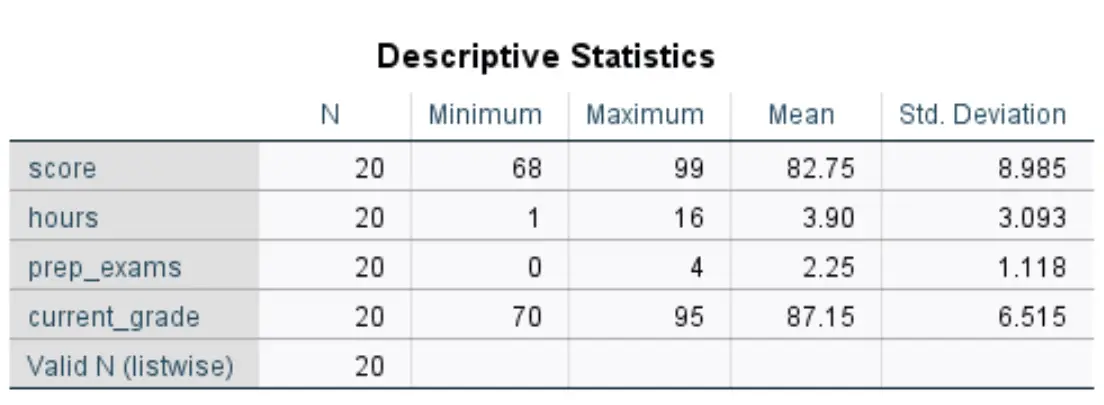
Zo interpreteert u de cijfers in deze tabel voor de scorevariabele :
- N: Het totale aantal waarnemingen. In dit geval zijn het er twintig.
- Minimum: Minimumwaarde voor de examenscore. In dit geval is dat 68.
- Maximaal: Maximale waarde voor de examenscore. In dit geval is dat 99.
- Gemiddeld: de gemiddelde score op het examen. In dit geval is het 82,75.
- Standaard. Afwijking: De standaardafwijking van examenscores. In dit geval is dat 8.985.
Met deze tabel kunnen we snel het bereik van elke variabele begrijpen (met behulp van het minimum en het maximum), de centrale locatie van elke variabele (met behulp van het gemiddelde) en de verdeling van waarden voor elke variabele (met behulp van de standaarddeviatie).
de tafels
Om voor elke variabele een frequentietabel te maken, klikt u op het tabblad Analyseren , vervolgens op Beschrijvende Statistieken en vervolgens op Frequenties .
In het nieuwe venster dat verschijnt, sleept u elke variabele naar het vak met de naam Variabele(n). Klik vervolgens op OK .
Voor elke variabele verschijnt een frequentietabel. Hier is bijvoorbeeld die voor variabele uren :
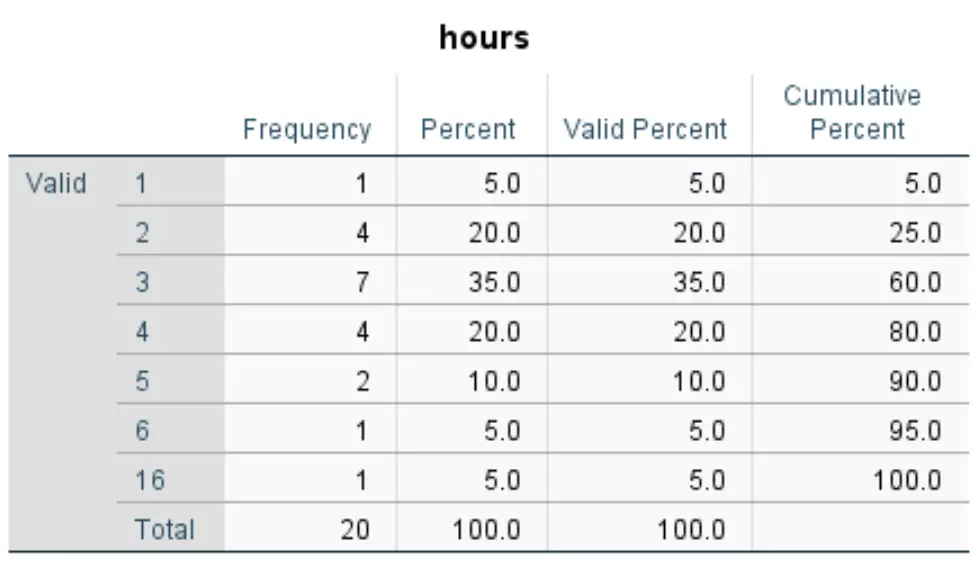
De manier om de tabel te interpreteren is als volgt:
- In de eerste kolom wordt elke unieke waarde voor de urenvariabele weergegeven. In dit geval zijn de unieke waarden 1, 2, 3, 4, 5, 6 en 16.
- In de tweede kolom wordt de frequentie van elke waarde weergegeven. De waarde 1 verschijnt bijvoorbeeld één keer, de waarde 2 verschijnt vier keer, enzovoort.
- In de derde kolom wordt het percentage voor elke waarde weergegeven. De waarde 1 vertegenwoordigt bijvoorbeeld 5% van alle waarden in de dataset. De waarde 2 vertegenwoordigt 20% van alle waarden in de dataset, enzovoort.
- In de laatste kolom wordt het cumulatieve percentage weergegeven. Waarden 1 en 2 vertegenwoordigen bijvoorbeeld samen 25% van de totale dataset. Waarden 1, 2 en 3 vertegenwoordigen in totaal 60% van de dataset, enzovoort.
Deze tabel geeft ons een goed beeld van de verdeling van de gegevenswaarden voor elke variabele.
Grafisch
Grafieken helpen ons ook de verdeling van gegevenswaarden voor elke variabele in een dataset te begrijpen. Een van de meest populaire grafieken om dit te doen is een histogram.
Als u een histogram voor een bepaalde variabele in een gegevensset wilt maken, klikt u op het tabblad Diagrammen en vervolgens op Chart Builder .
In het nieuwe venster dat verschijnt, kiest u Histogram in het paneel ‚Kiezen uit‘. Sleep vervolgens de eerste histogramoptie naar het hoofdbewerkingsvenster. Sleep vervolgens de gewenste variabele naar de x-as. Voor dit voorbeeld gebruiken we score . Klik vervolgens op OK .
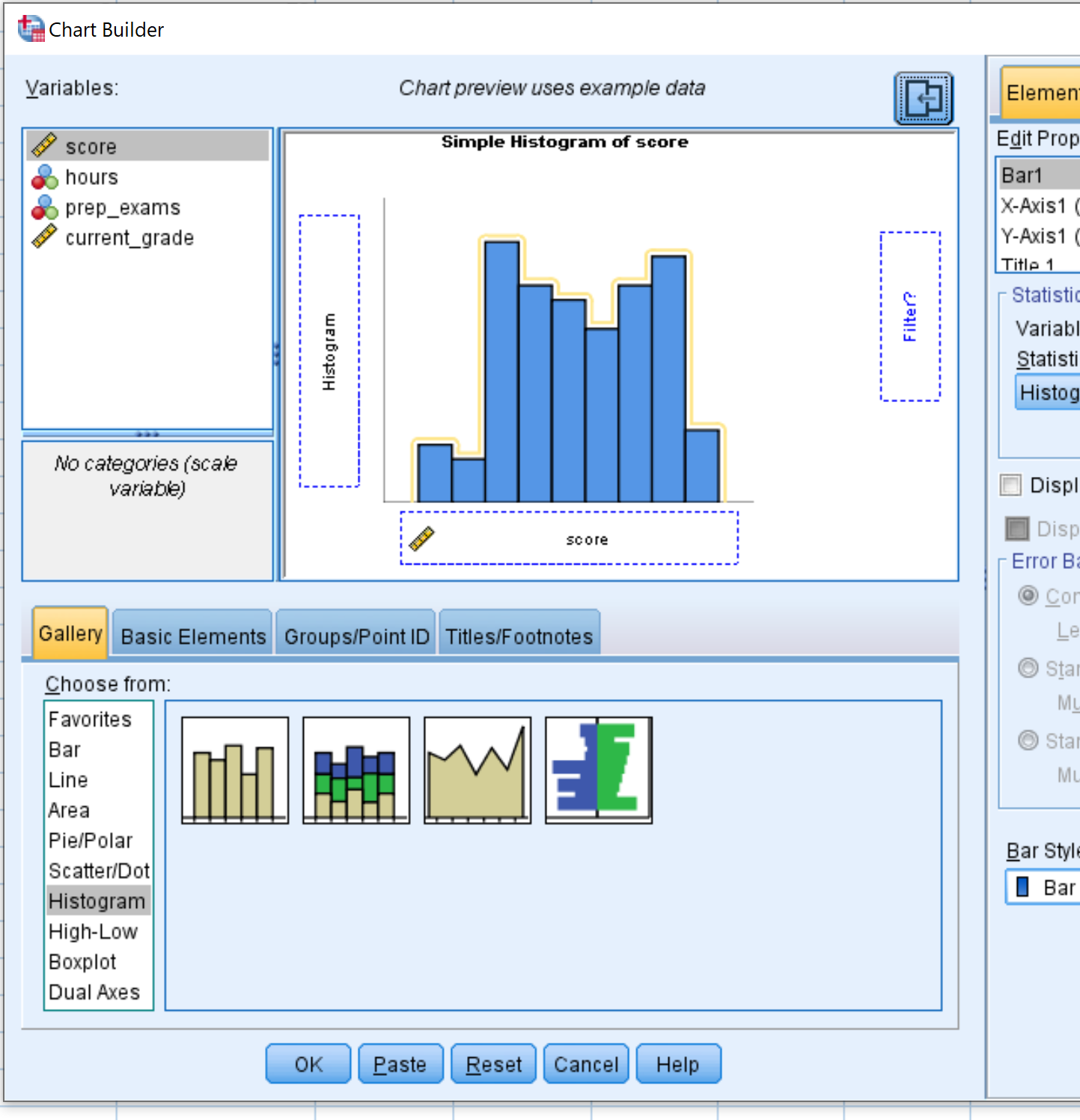
Zodra u op OK klikt, verschijnt er een histogram dat de verdeling van de waarden voor de variabele score weergeeft:
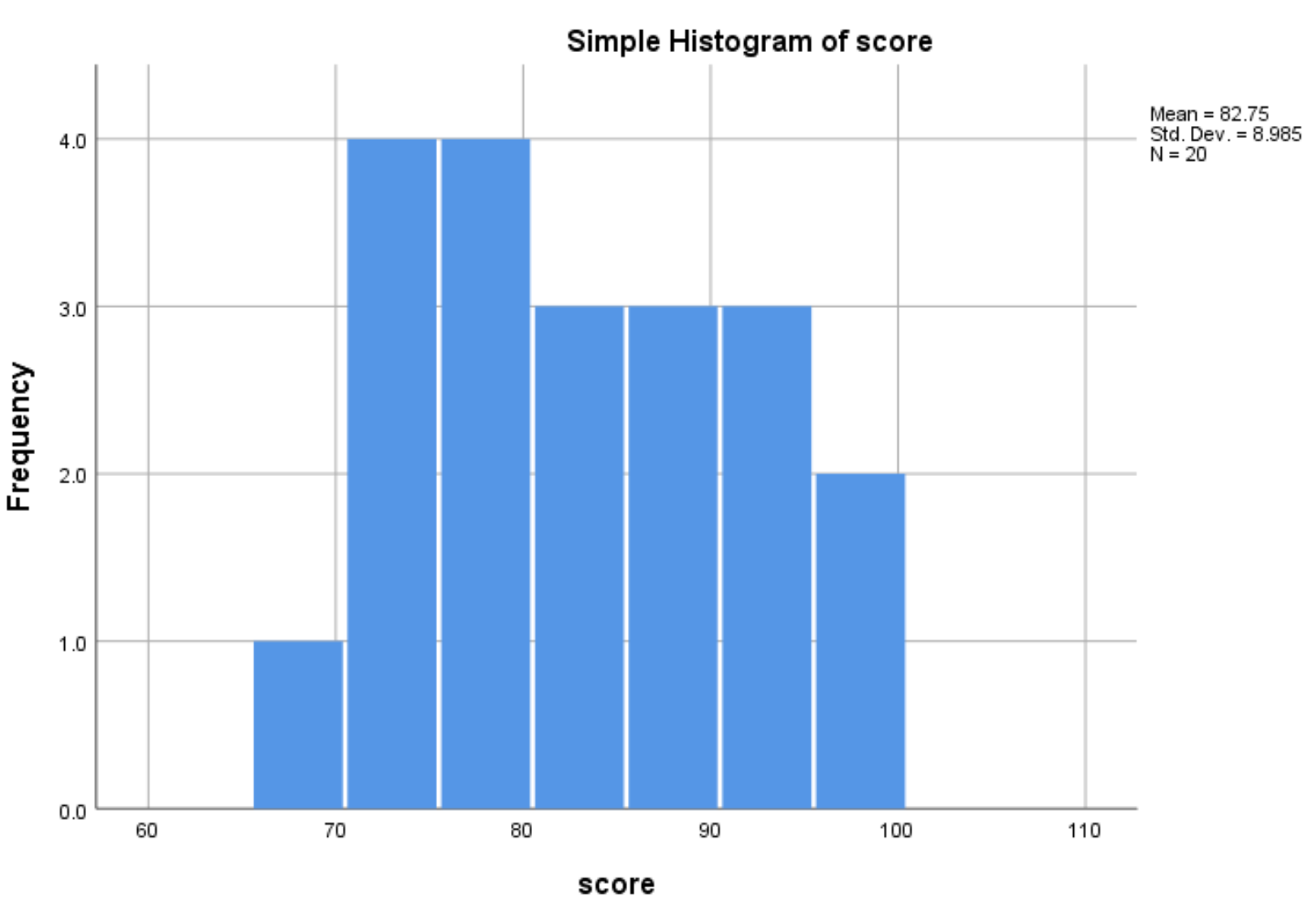
Uit het histogram blijkt dat het bereik van de examenscores varieert tussen 65 en 100, waarbij de meeste scores tussen 70 en 90 liggen.
We kunnen dit proces ook herhalen om een histogram te maken voor elk van de andere variabelen in de dataset.
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder