Wat is een bimodale verdeling?
Een bimodale verdeling is een kansverdeling met twee modi.
We gebruiken de term ‚modus‘ vaak in beschrijvende statistieken om te verwijzen naar de meest voorkomende waarde in een dataset, maar in dit geval verwijst de term ‚modus‘ naar een lokaal maximum in een grafiek.
Wanneer u een bimodale verdeling bekijkt, zult u twee verschillende „pieken“ opmerken die deze twee modi vertegenwoordigen.
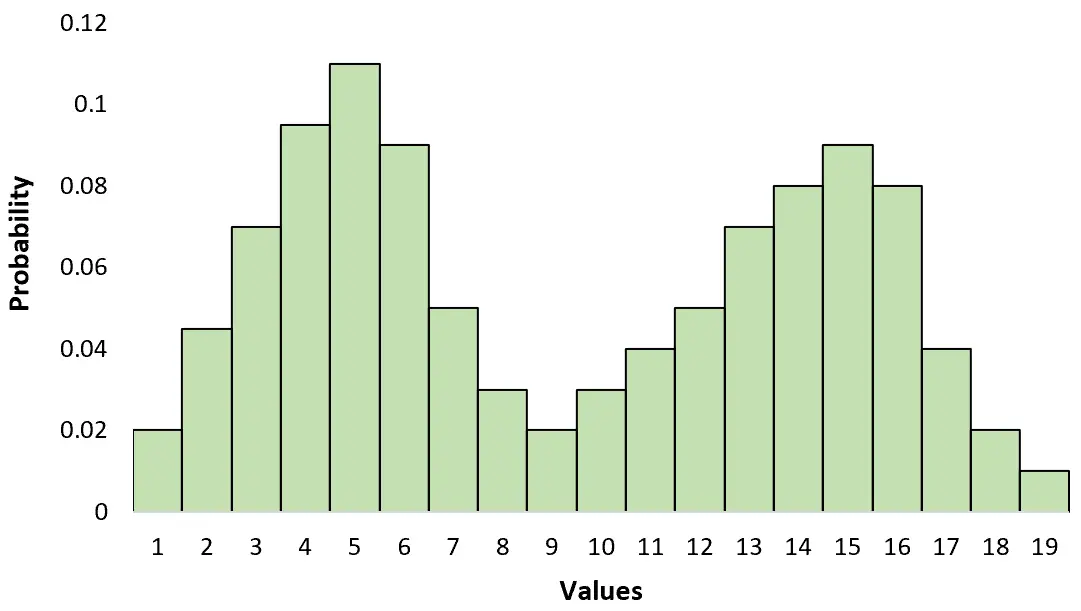
Dit verschilt van een unimodale verdeling die slechts één piek heeft:
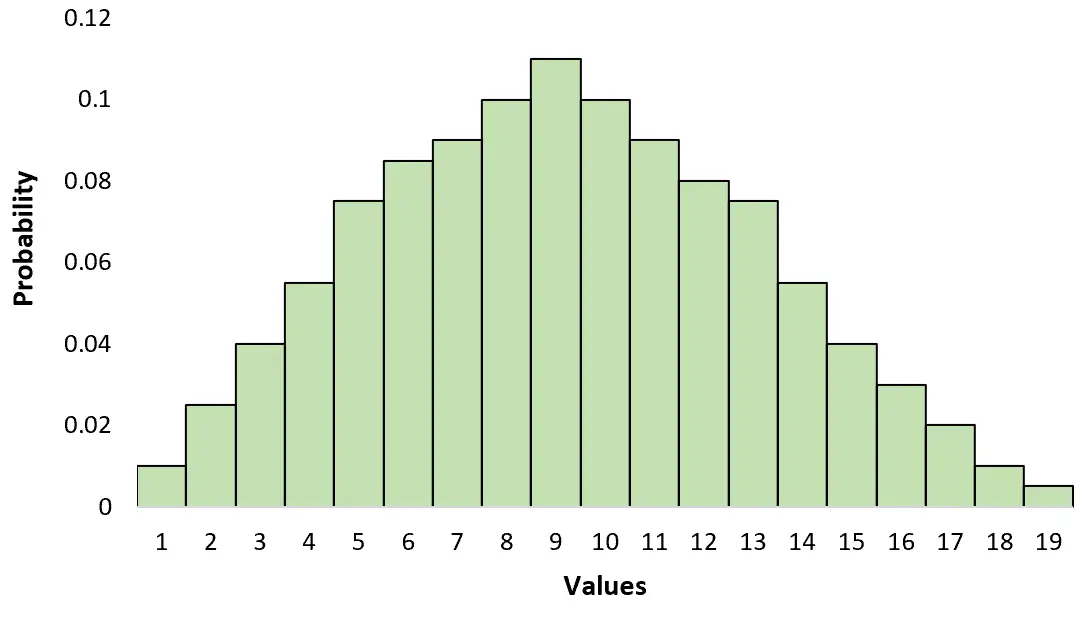
Je kunt het verschil tussen de twee onthouden door te onthouden:
- “bi” = twee
- “verenigd” = één
Hoewel de meeste statistische cursussen unimodale verdelingen zoals de normale verdeling gebruiken om verschillende onderwerpen uit te leggen, komen bimodale verdelingen in de praktijk vrij vaak voor, dus het is nuttig om te weten hoe u ze kunt herkennen en interpreteren.
Opmerking: Een bimodale distributie is een specifiek type multimodale distributie .
Voorbeelden van bimodale distributies
Hier zijn enkele voorbeelden van bimodale distributies:
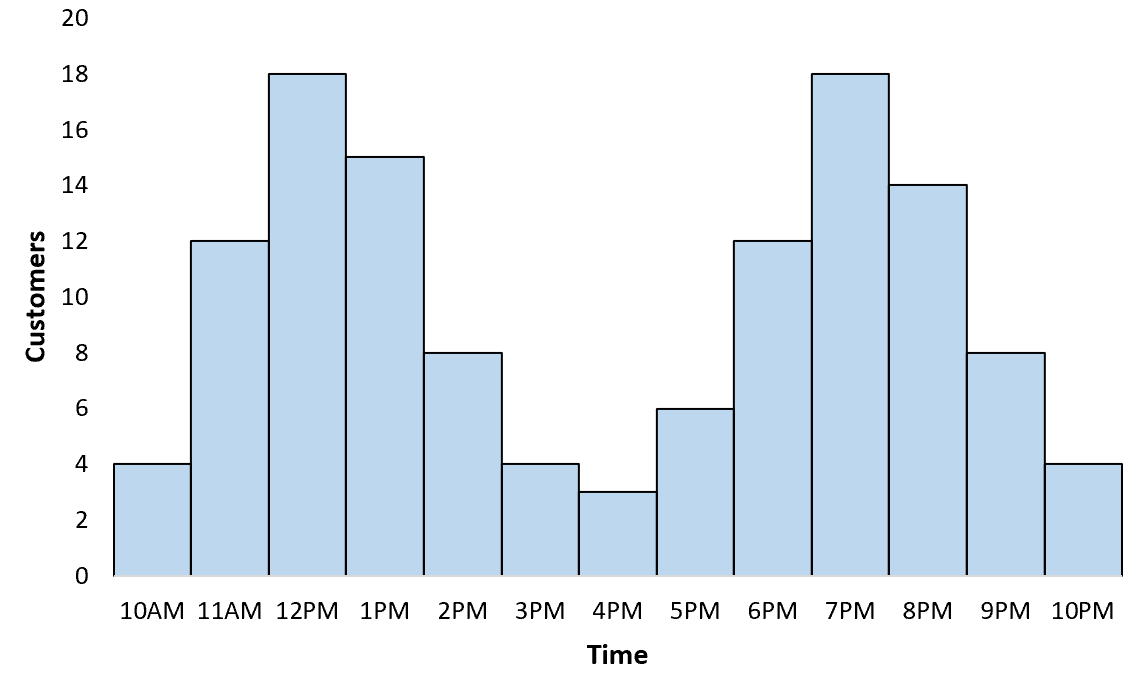
Voorbeeld #1: Piekuren van restaurants
Als u een grafiek zou maken om de uurverdeling van klanten in een bepaald restaurant te visualiseren, zou u waarschijnlijk merken dat deze een bimodale verdeling volgt met een piek tijdens de lunch en een andere piek tijdens de dineruren:
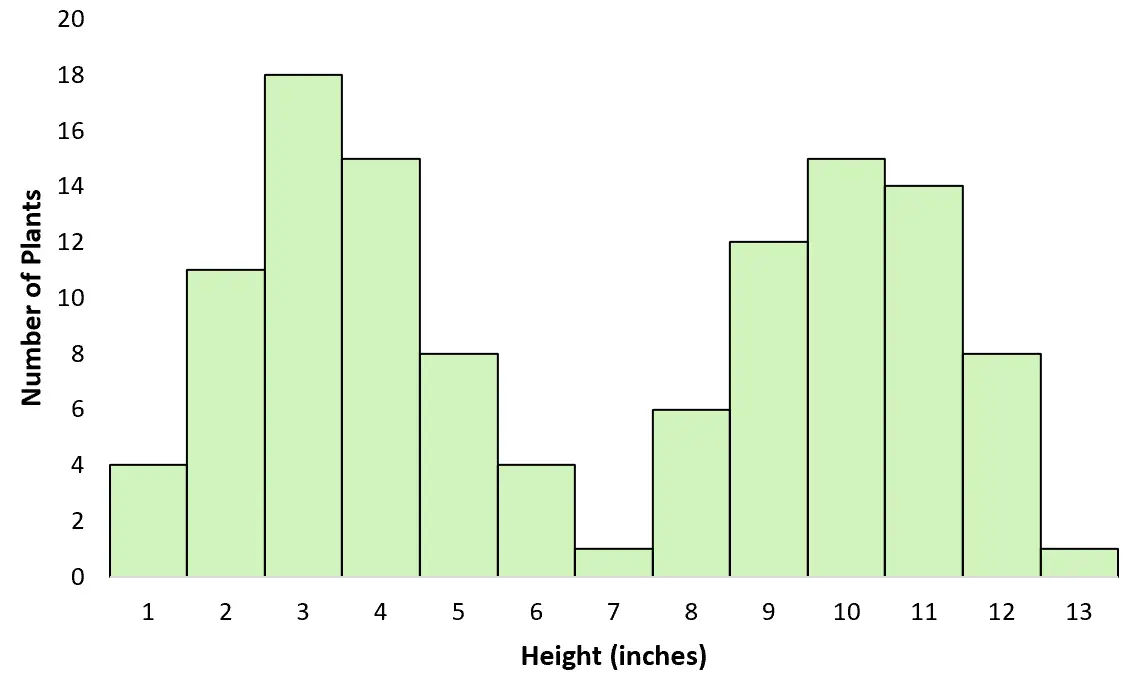
Voorbeeld nr. 2: Gemiddelde hoogte van twee plantensoorten
Stel dat je door een veld loopt en de hoogte van verschillende planten meet. Zonder het te beseffen meet je de grootte van twee verschillende soorten: de ene vrij groot en de andere vrij klein. Als u een grafiek zou maken om de hoogteverdeling te visualiseren, zou deze een bimodale verdeling volgen:
Voorbeeld #3: examenresultaten
Stel dat een leraar een examen aflegt aan zijn klas leerlingen. Sommige studenten studeerden voor het examen, anderen niet. Wanneer de docent een grafiek met examenresultaten maakt, volgt deze een bimodale verdeling met een piek rond lage scores voor studenten die niet hebben gestudeerd en een andere piek rond hoge scores voor studenten die wel hebben gestudeerd:
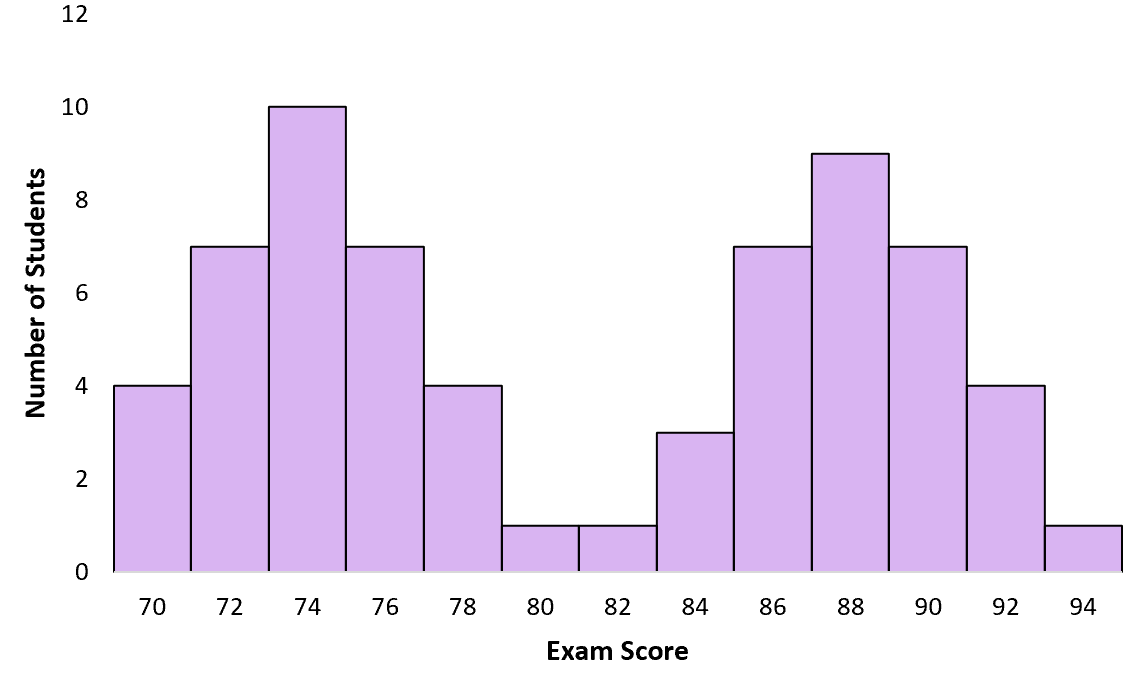
Wat veroorzaakt bimodale distributies?
Er zijn over het algemeen twee dingen die bimodale distributies veroorzaken:
1. Enkele onderliggende verschijnselen.
Bimodale distributies komen vaak voor als gevolg van bepaalde onderliggende verschijnselen.
Het aantal klanten dat elk uur een restaurant bezoekt, volgt bijvoorbeeld een bimodale verdeling, aangezien mensen de neiging hebben om op twee verschillende tijdstippen in restaurants te eten: lunch en diner. Dit onderliggende menselijke gedrag is de oorsprong van de bimodale distributie.
2. Twee verschillende groepen bij elkaar gegroepeerd.
Bimodale verdelingen kunnen ook optreden als je eenvoudigweg twee verschillende groepen dingen analyseert zonder het te beseffen.
Als u bijvoorbeeld de hoogte van planten in een bepaald veld meet zonder te beseffen dat er twee verschillende soorten in hetzelfde veld groeien, ziet u een bimodale verdeling wanneer u een grafiek maakt.
Hoe bimodale distributies te analyseren
We beschrijven verdelingen vaak met behulp van het gemiddelde of de mediaan , omdat dit ons een idee geeft van waar het ‘centrum’ van de verdeling zich bevindt.
Helaas zijn het gemiddelde en de mediaan niet nuttig om te weten voor een bimodale verdeling. De gemiddelde examenscore van de studenten in bovenstaand voorbeeld is bijvoorbeeld 81:
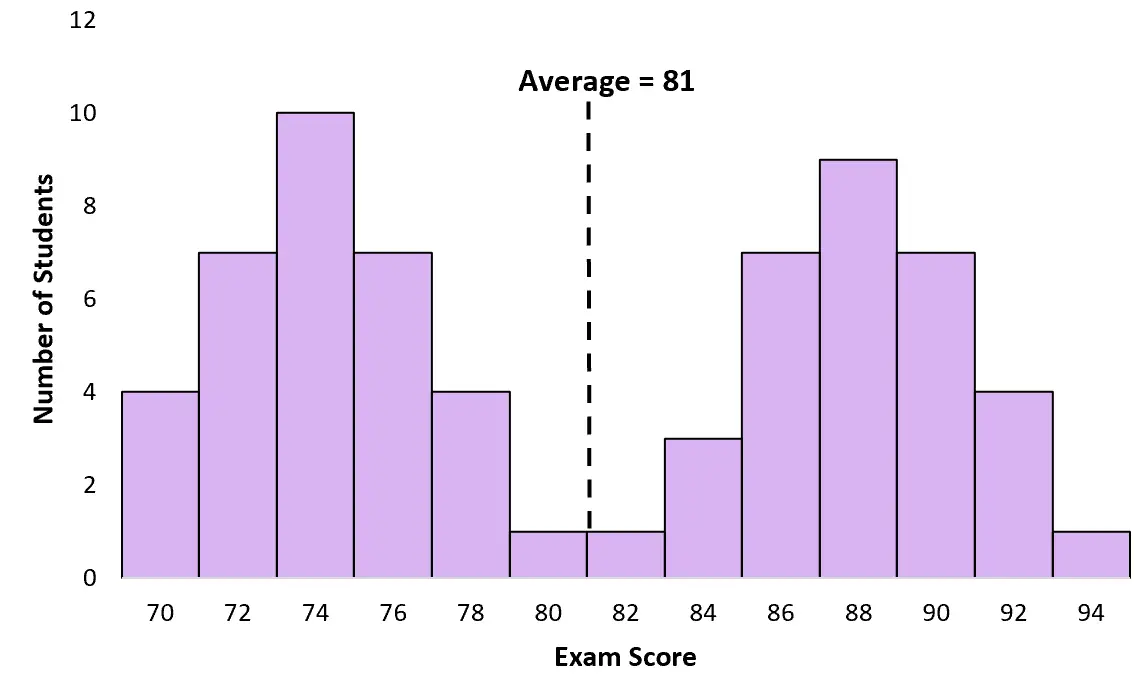
Er zijn echter maar heel weinig studenten die in de buurt van de 81 scoren. In dit geval is het gemiddelde misleidend. De meeste studenten scoorden feitelijk rond de 74 of 88.
Een betere manier om bimodale verdelingen te analyseren en interpreteren is door de gegevens simpelweg in twee afzonderlijke groepen te verdelen en vervolgens het centrum en de verdeling voor elke groep te analyseren.
We kunnen examenresultaten bijvoorbeeld verdelen in ‚lage scores‘ en ‚hoge scores‘ en vervolgens voor elke groep het gemiddelde en de standaarddeviatie vinden.
Als u de resultaten van een analyse deelt en uw gegevens een bimodale verdeling volgen, is het handig om een histogram te maken zoals hierboven weergegeven, zodat uw publiek duidelijk kan zien dat de verdeling twee verschillende ‘pieken’ heeft en dat deze slechts Het is logisch om elke piek afzonderlijk te analyseren in plaats van als één grote dataset.
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder