Waarom is het gemiddelde belangrijk in statistieken?
Het gemiddelde van een dataset vertegenwoordigt de gemiddelde waarde van de dataset. Het wordt als volgt berekend:
Gemiddeld = Σx i / n
Goud:
- Σ: Een symbool dat “som” betekent
- x i : De i- de waarneming in een dataset
- n: het totale aantal waarnemingen in de dataset
Stel dat we bijvoorbeeld de volgende dataset hebben met 11 observaties:
Gegevensset: 3, 4, 4, 6, 7, 8, 12, 13, 15, 16, 17
Het gemiddelde van de dataset wordt als volgt berekend:
Gemiddeld = (3+4+4+6+7+8+12+13+15+16+17) / 11 = 9,54
In statistieken is het gemiddelde om de volgende redenen belangrijk:
1. Het gemiddelde geeft ons een idee van waar het ‘centrum’ van een dataset zich bevindt.
2. Vanwege de manier waarop het wordt berekend, bevat het gemiddelde informatie van elke waarneming in een dataset.
Het volgende voorbeeld illustreert deze twee redenen.
Voorbeeld: Bereken het gemiddelde van een reeks gegevens
Laten we zeggen dat we een dataset hebben met de verkoopprijzen van 10.000 verschillende huizen in een bepaalde stad.
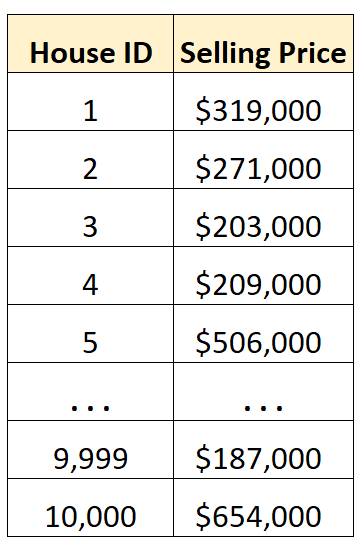
In plaats van naar duizenden rijen met onbewerkte gegevens te kijken, kunnen we de gemiddelde waarde berekenen om snel inzicht te krijgen in de gemiddelde verkoopprijs van woningen in die stad.
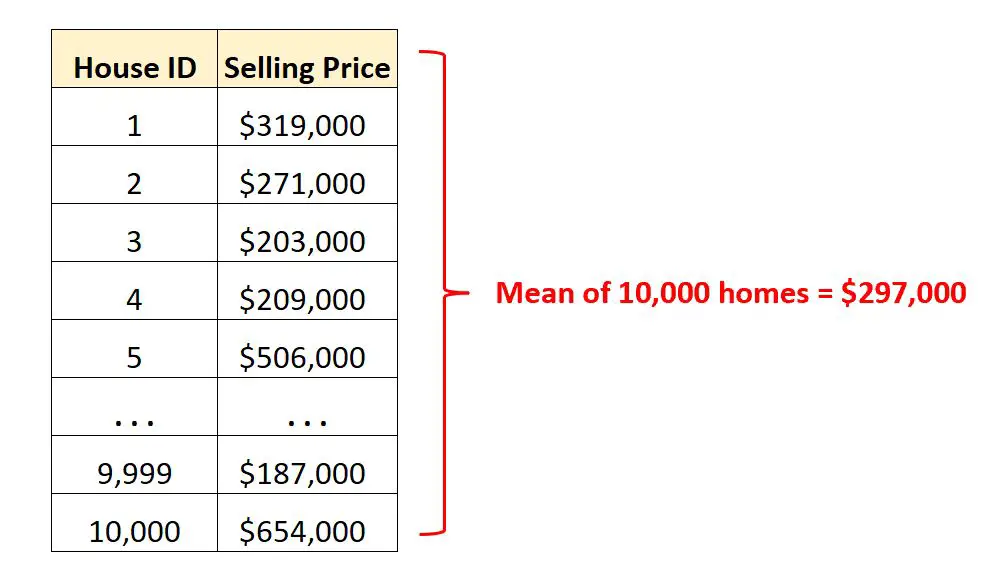
Wetende dat de gemiddelde verkoopprijs $ 297.000 bedraagt, geeft ons een idee van wat een ‘typisch’ huis in deze stad oplevert.
Deze enkele waarde van het gemiddelde is veel gemakkelijker te interpreteren dan naar alle rijen met onbewerkte gegevens te kijken.
En aangezien elke verkoopprijs van een huis werd gebruikt om het gemiddelde te berekenen, konden we de gemiddelde verkoopprijs vermenigvuldigen met het totale aantal woningen om de totale verkoopprijs van alle woningen in die stad te vinden:
- Totale verkoopprijs van alle woningen = Gemiddelde verkoopprijs * Aantal woningen
- Totale verkoopprijs van alle woningen = $ 297.000 * 10.000
- Totale verkoopprijs van alle woningen = $ 2.970.000.000
We kunnen zien dat de totale verkoopprijs van alle huizen in deze stad $2,97 miljard bedraagt.
Wanneer gebruik je het gemiddelde?
Bij het analyseren van datasets willen we vaak begrijpen waar de centrale waarde ligt.
In de statistiek zijn er twee veelgebruikte maatstaven die we gebruiken om het middelpunt van een dataset te meten:
- Gemiddelde : de gemiddelde waarde in een reeks gegevens
- Mediaan : de mediaanwaarde in een gegevensset
Het gemiddelde is de meest gebruikelijke manier om het middelpunt van een dataset te meten, maar kan in de volgende situaties misleidend zijn:
- Wanneer de verdelingasymmetrisch is.
- Wanneer de verdeling uitschieters bevat.
Om dit te illustreren, bekijken we de volgende twee voorbeelden.
Voorbeeld 1: Berekening van het gemiddelde van een scheve verdeling
Beschouw de volgende loonverdeling voor inwoners van een bepaalde stad:
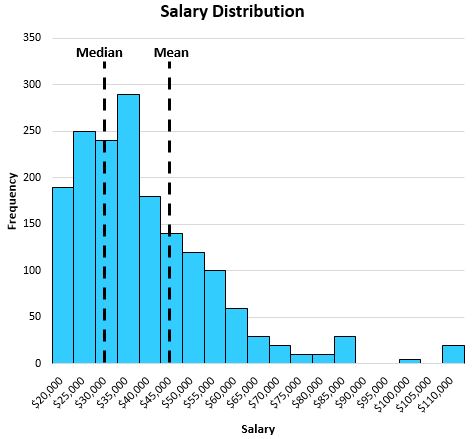
Hoge lonen aan de rechterkant van de verdeling duwen het gemiddelde weg van het centrum van de verdeling.
De mediaan weerspiegelt dus beter het “typische” salaris van een inwoner dan het gemiddelde, omdat de verdeling naar rechts scheef is.
In dit specifieke voorbeeld is het gemiddelde salaris $47.000, terwijl het gemiddelde salaris $32.000 is.
De mediaan is dus veel representatiever voor het typische salaris in die stad.
Voorbeeld 2: Berekening van het gemiddelde in aanwezigheid van uitbijters
Bekijk de volgende grafiek die het aantal vierkante meters huizen in een bepaalde straat laat zien:
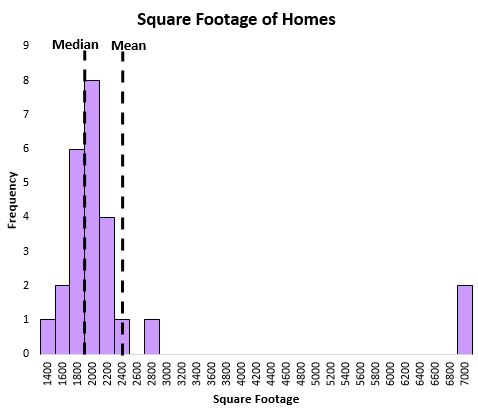
Het gemiddelde wordt sterk beïnvloed door enkele extreem grote huizen, terwijl de mediaan dat niet is.
We kunnen zien dat de mediaan de ‘typische’ vierkante meters van een huis in die straat beter weergeeft dan het gemiddelde, omdat deze niet wordt beïnvloed door uitschieters.
Samenvatting
Hier is een korte samenvatting van de belangrijkste conclusies uit dit artikel:
- Het gemiddelde vertegenwoordigt de gemiddelde waarde in een reeks gegevens.
- Het gemiddelde is belangrijk omdat het ons een idee geeft van waar de centrale waarde in een dataset ligt.
- Het gemiddelde is ook belangrijk omdat het informatie bevat van elke waarneming in een dataset.
- Het gemiddelde kan misleidend zijn als een dataset scheef is of uitschieters bevat. In deze scenario’s geeft de mediaan een nauwkeuriger idee van waar het “centrum” van een dataset zich bevindt.
Aanvullende bronnen
De volgende tutorials bieden aanvullende informatie over andere beschrijvende statistieken:
Waarom is de mediaan belangrijk in statistieken?
Waarom is standaarddeviatie belangrijk in statistieken?
Wanneer moet u het gemiddelde versus de mediaan gebruiken?
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder