Hoe significante variabelen in regressiemodellen te bepalen
Een van de belangrijkste vragen die u zichzelf zult stellen nadat u een meervoudig lineair regressiemodel heeft aangepast, is: welke variabelen zijn significant?
Er zijn twee methoden die u niet moet gebruiken om de betekenis van een variabele te bepalen:
1. De waarde van de regressiecoëfficiënten
Een regressiecoëfficiënt voor een bepaalde voorspellende variabele vertelt u de gemiddelde verandering in de responsvariabele die gepaard gaat met een toename van één eenheid in die voorspellende variabele.
Elke voorspellende variabele in een model wordt echter doorgaans op een andere schaal gemeten. Het heeft daarom geen zin om de absolute waarden van de regressiecoëfficiënten te vergelijken om te bepalen welke variabelen het belangrijkst zijn.
2. De p-waarden van de regressiecoëfficiënten
De p-waarden van regressiecoëfficiënten kunnen u vertellen of een bepaalde voorspellende variabele een statistisch significant verband heeft met de responsvariabele, maar ze kunnen u niet vertellen of een bepaalde voorspellende variabele praktisch significant is in de echte wereld.
P-waarden kunnen ook laag zijn vanwege een grote steekproefomvang of een lage variabiliteit, wat ons eigenlijk niet vertelt of een bepaalde voorspellende variabele in de praktijk betekenisvol is.
Er zijn echter twee methoden die u moet gebruiken om de betekenis van variabelen te bepalen:
1. Gestandaardiseerde regressiecoëfficiënten
Wanneer we meerdere lineaire regressies uitvoeren, zijn de resulterende regressiecoëfficiënten in de modeluitvoer doorgaans niet gestandaardiseerd , wat betekent dat ze de onbewerkte gegevens gebruiken om de best passende lijn te vinden.
Het is echter mogelijk om elke voorspellende variabele en de responsvariabele te standaardiseren (door de gemiddelde waarde van elke variabele af te trekken van de oorspronkelijke waarden en deze vervolgens te delen door de standaardafwijking van de variabelen) en vervolgens een regressie uit te voeren, wat resulteert in gestandaardiseerde regressiecoëfficiënten .
Door elke variabele in het model te standaardiseren, wordt elke variabele op dezelfde schaal gemeten. Het is daarom zinvol om de absolute waarden van de regressiecoëfficiënten in de resultaten te vergelijken om te begrijpen welke variabelen het grootste effect hebben op de responsvariabele.
2. Vakdeskundigheid
Hoewel p-waarden je kunnen vertellen of er een statistisch significant effect is tussen een bepaalde voorspellende variabele en de responsvariabele, is vakkennis nodig om te bevestigen of een voorspellende variabele daadwerkelijk relevant is en daadwerkelijk in een model moet worden opgenomen.
Het volgende voorbeeld laat zien hoe u in de praktijk significante variabelen in een regressiemodel kunt bepalen.
Voorbeeld: hoe u significante variabelen in een regressiemodel kunt bepalen
Stel dat we de volgende dataset hebben met informatie over de leeftijd, vierkante meters en verkoopprijs van 12 woningen:
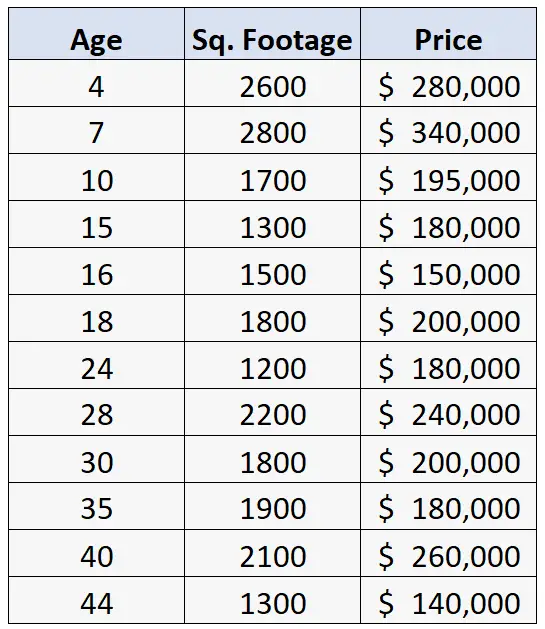
Stel dat we vervolgens een meervoudige lineaire regressie uitvoeren, waarbij we leeftijd en vierkante meters gebruiken als voorspellende variabelen en prijs als responsvariabele.
We krijgen het volgende resultaat:

De regressiecoëfficiënten in deze tabel zijn niet gestandaardiseerd , wat betekent dat ze de ruwe gegevens hebben gebruikt om in dit regressiemodel te passen.
Op het eerste gezicht lijkt het erop dat leeftijd een veel groter effect heeft op de vastgoedprijs, aangezien de coëfficiënt in de regressietabel -409.833 bedraagt, vergeleken met slechts 100.866 voor de voorspellende variabele vierkante meters .
De standaardfout is echter veel groter voor leeftijd dan voor vierkante meters. Daarom is de overeenkomstige p-waarde feitelijk groot voor leeftijd (p = 0,520) en klein voor vierkante meters (p = 0,000).
De reden voor de extreme verschillen in de regressiecoëfficiënten is te wijten aan de extreme verschillen in de schalen voor de twee variabelen:
- Waarden voor de leeftijd variëren van 4 tot 44 jaar.
- Vierkante lengtewaarden variëren van 1.200 tot 2.800.
Stel dat we in plaats daarvan de onbewerkte gegevens normaliseren :
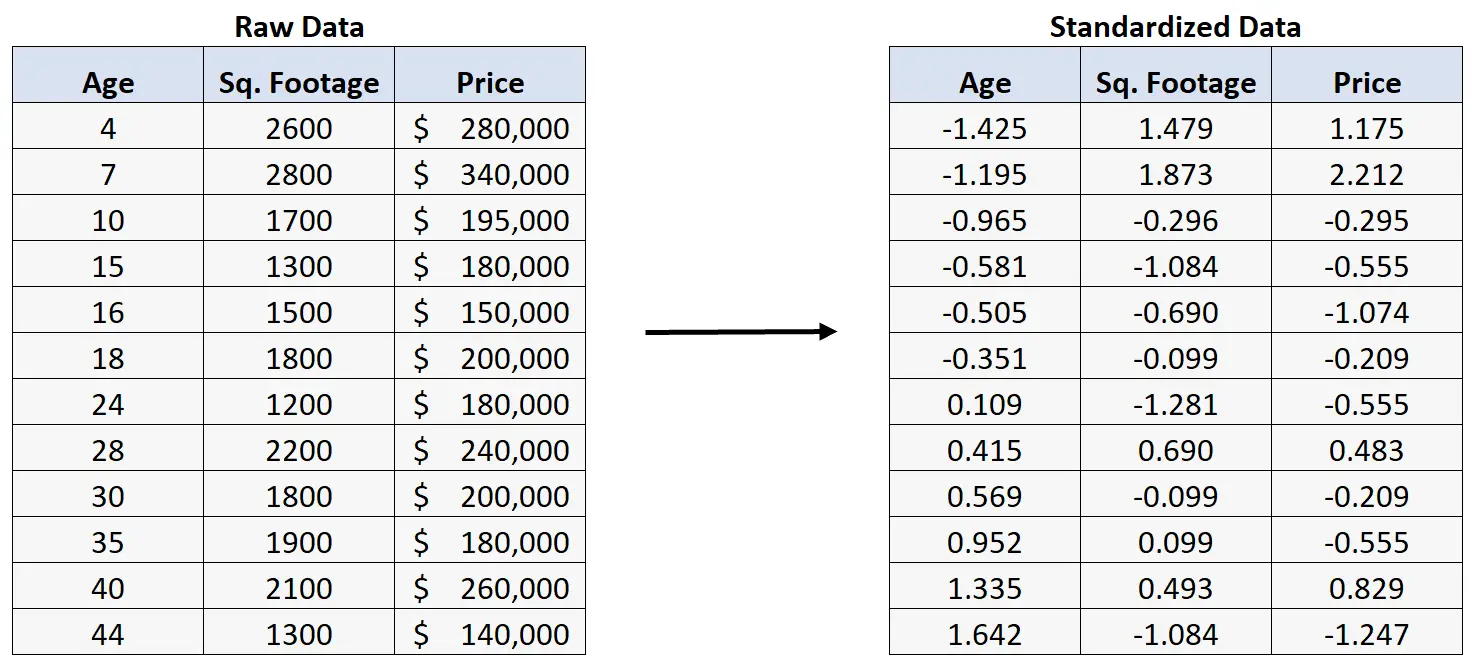
Als we vervolgens een meervoudige lineaire regressie uitvoeren met behulp van de gestandaardiseerde gegevens, verkrijgen we het volgende regressieresultaat:

De regressiecoëfficiënten in deze tabel zijn gestandaardiseerd , wat betekent dat er gestandaardiseerde gegevens zijn gebruikt om in dit regressiemodel te passen.
De manier om de coëfficiënten in de tabel te interpreteren is als volgt:
- Een stijging van één standaardafwijking in leeftijd gaat gepaard met een daling van de huizenprijs met 0,092 standaardafwijking, ervan uitgaande dat het aantal vierkante meters constant blijft.
- Een toename van één standaardafwijking in vierkante meters gaat gepaard met een stijging van de huizenprijs met 0,885 standaardafwijking, ervan uitgaande dat de leeftijd constant blijft.
We kunnen nu zien dat vierkante meters een veel groter effect hebben op de huizenprijzen dan leeftijd.
Opmerking : de p-waarden voor elke voorspellende variabele zijn exact dezelfde als die in het vorige regressiemodel.
Bij het beslissen welk eindmodel we moeten gebruiken, weten we nu dat vierkante meters veel belangrijker zijn bij het voorspellen van de prijs van een huis dan de leeftijd ervan .
Uiteindelijk zullen we onze inhoudelijke expertise moeten gebruiken om te bepalen welke variabelen we in het uiteindelijke model moeten opnemen, op basis van bestaande kennis over huizen- en vastgoedprijzen.
Aanvullende bronnen
De volgende zelfstudies bieden aanvullende informatie over regressiemodellen:
Een regressietabel lezen en interpreteren
Hoe regressiecoëfficiënten te interpreteren
Hoe P-waarden te interpreteren in lineaire regressie
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder