Binning met gelijke frequentie in python
In de statistiek is groeperen het proces waarbij numerieke waarden in groepen worden geplaatst.
De meest voorkomende vorm van clustering staat bekend als clustering met gelijke breedte , waarbij we een dataset verdelen in k groepen van gelijke breedte.
Een minder vaak gebruikte vorm van clustering staat bekend als clustering met gelijke frequentie , waarbij we een dataset verdelen in k groepen die allemaal een gelijk aantal frequenties hebben.
In deze tutorial wordt uitgelegd hoe u clustering met gelijke frequentie in Python kunt uitvoeren.
Binning met gelijke frequentie in Python
Stel dat we een dataset hebben met 100 waarden:
import numpy as np import matplotlib.pyplot as plt #create data np.random.seed(1) data = np.random.randn(100) #view first 5 values data[:5] array([ 1.62434536, -0.61175641, -0.52817175, -1.07296862, 0.86540763])
Gelijke breedtegroepering:
Als we een histogram maken om deze waarden weer te geven, zal Python standaard groeperen met gelijke breedte:
#create histogram with equal-width bins n, bins, patches = plt.hist(data, edgecolor='black') plt.show() #display bin boundaries and frequency per bin bins, n (array([-2.3015387 , -1.85282729, -1.40411588, -0.95540447, -0.50669306, -0.05798165, 0.39072977, 0.83944118, 1.28815259, 1.736864, 2.18557541]), array([ 3., 1., 6., 17., 19., 20., 14., 12., 5., 3.]))
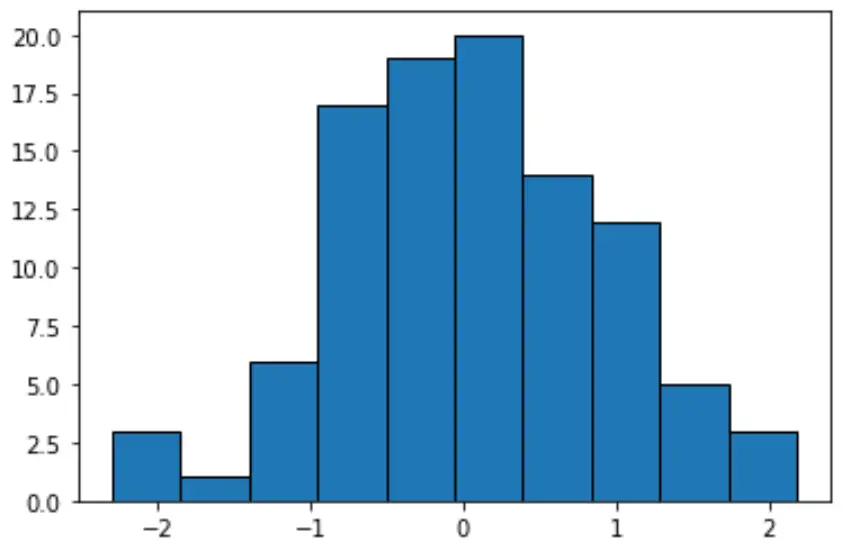
Elke groep heeft een gelijke breedte van ongeveer 0,4487, maar elke groep bevat niet een gelijk aantal waarnemingen. Bijvoorbeeld:
- De eerste bak strekt zich uit van -2,3015387 tot -1,8528279 en bevat 3 waarnemingen.
- De tweede bak strekt zich uit van -1,8528279 tot -1,40411588 en bevat 1 waarneming.
- De derde bak strekt zich uit van -1,40411588 tot -0,95540447 en bevat 6 waarnemingen.
Enzovoort.
Gelijke frequentiegroepering:
Om buckets te maken die een gelijk aantal waarnemingen bevatten, kunnen we de volgende functie gebruiken:
#define function to calculate equal-frequency bins def equalObs(x, nbin): nlen = len(x) return np.interp(np.linspace(0, nlen, nbin + 1), np.arange(nlen), np.sort(x)) #create histogram with equal-frequency bins n, bins, patches = plt.hist(data, equalObs(data, 10), edgecolor='black') plt.show() #display bin boundaries and frequency per bin bins, n (array([-2.3015387 , -0.93576943, -0.67124613, -0.37528495, -0.20889423, 0.07734007, 0.2344157, 0.51292982, 0.86540763, 1.19891788, 2.18557541]), array([10., 10., 10., 10., 10., 10., 10., 10., 10., 10.]))
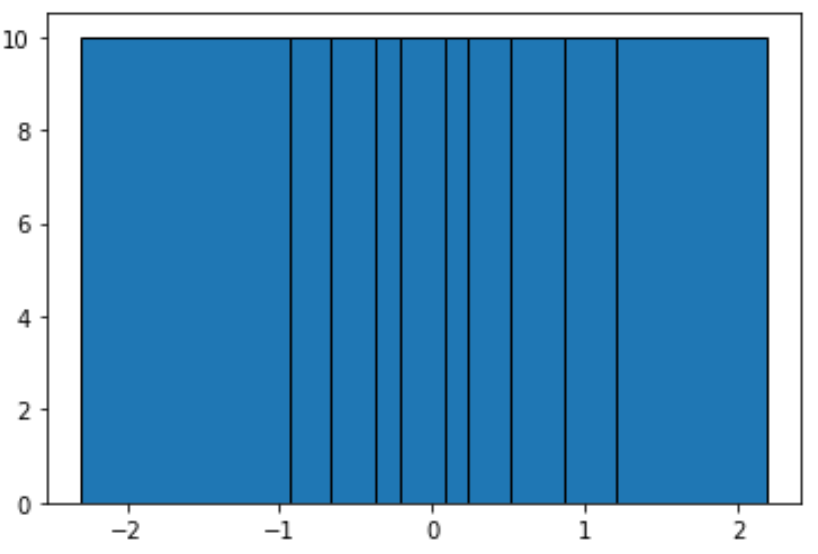
Elke groep is niet even breed, maar elke groep bevat een gelijk aantal waarnemingen. Bijvoorbeeld:
- De eerste bak strekt zich uit van -2,3015387 tot -0,93576943 en bevat 10 waarnemingen.
- De tweede bak strekt zich uit van -0,93576943 tot -0,67124613 en bevat 10 waarnemingen.
- De derde bak strekt zich uit van -0,67124613 tot -0,37528495 en bevat 10 waarnemingen.
Enzovoort.
Uit het histogram kunnen we zien dat elke bak duidelijk niet even breed is, maar dat elke bak hetzelfde aantal waarnemingen bevat, wat wordt bevestigd door het feit dat de hoogte van elke bak gelijk is.
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder