5 voorbeelden van bivariate gegevens in het echte leven
Bivariate gegevens verwijzen naar een gegevensset die precies twee variabelen bevat.
Dit soort gegevens verschijnen voortdurend in praktijksituaties en we gebruiken doorgaans de volgende methoden om dit soort gegevens te analyseren:
- Puntenwolken
- Correlatie coëfficiënten
- Eenvoudige lineaire regressie
De volgende voorbeelden laten verschillende scenario’s zien waarin bivariate gegevens in het echte leven voorkomen.
Voorbeeld 1: Zakelijk
Bedrijven verzamelen vaak bivariate gegevens over het totale geld dat aan advertenties wordt besteed en de totale inkomsten.
Een bedrijf kan bijvoorbeeld de volgende gegevens verzamelen voor twaalf opeenvolgende verkoopkwartalen:
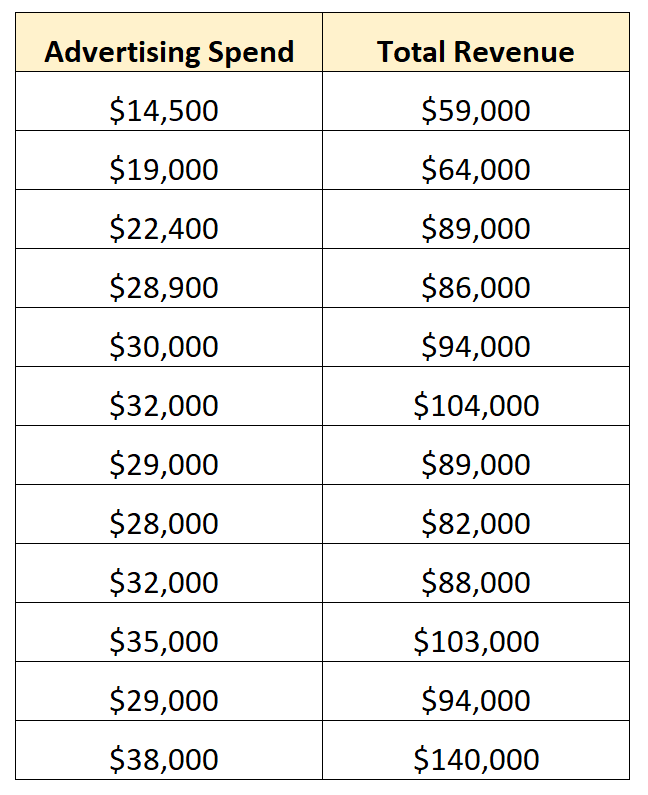
Dit is een voorbeeld van bivariate gegevens omdat deze informatie bevatten over precies twee variabelen: advertentie-uitgaven en totale inkomsten.
Het bedrijf kan besluiten om een eenvoudig lineair regressiemodel aan deze dataset toe te passen en het volgende passende model te vinden:
Totale opbrengst = 14.942,75 + 2,70* (advertentiekosten)
Dit vertelt het bedrijf dat voor elke extra dollar die aan advertenties wordt besteed, de totale omzet met gemiddeld $ 2,70 stijgt.
Voorbeeld 2: Medisch
Medische onderzoekers verzamelen vaak bivariate gegevens om de relatie tussen gezondheidsgerelateerde variabelen beter te begrijpen.
Een onderzoeker kan bijvoorbeeld de volgende leeftijds- en resterende hartslaggegevens van 15 mensen verzamelen:
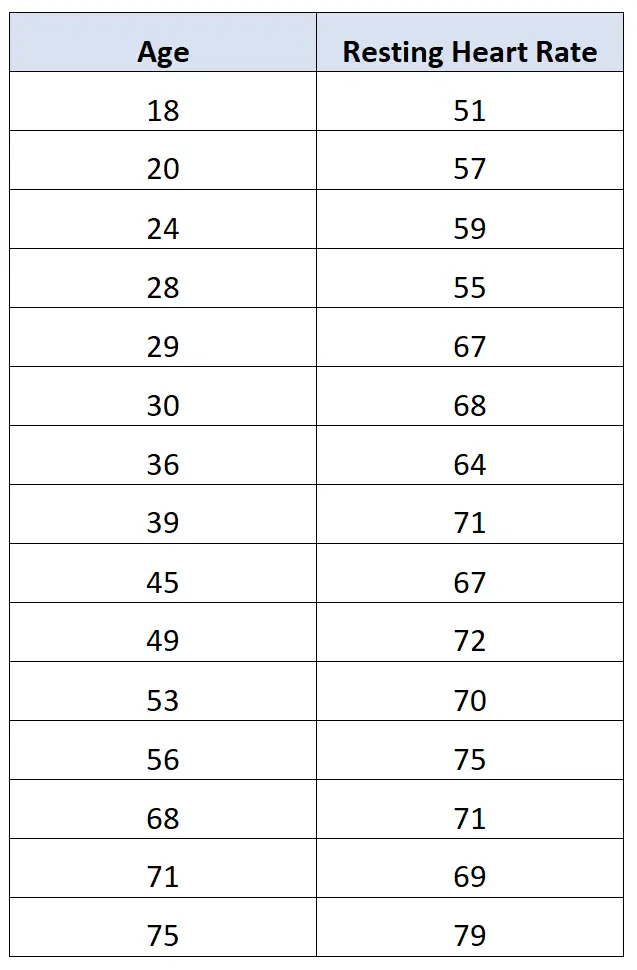
De onderzoeker kan dan besluiten om de correlatie tussen de twee variabelen te berekenen en deze gelijk te stellen aan 0,812 .
Dit geeft aan dat er een sterke positieve correlatie bestaat tussen de twee variabelen. Dat wil zeggen dat naarmate de leeftijd toeneemt, de resterende hartslag ook voorspelbaar toeneemt.
Gerelateerd: Wat wordt beschouwd als een “sterke” correlatie?
Voorbeeld 3: academici
Onderzoekers verzamelen vaak bivariate gegevens om te begrijpen welke variabelen de prestaties van studenten beïnvloeden.
Een onderzoeker kan bijvoorbeeld gegevens verzamelen over het aantal gestudeerde uren per week en het bijbehorende GPA voor studenten in een bepaalde klas:
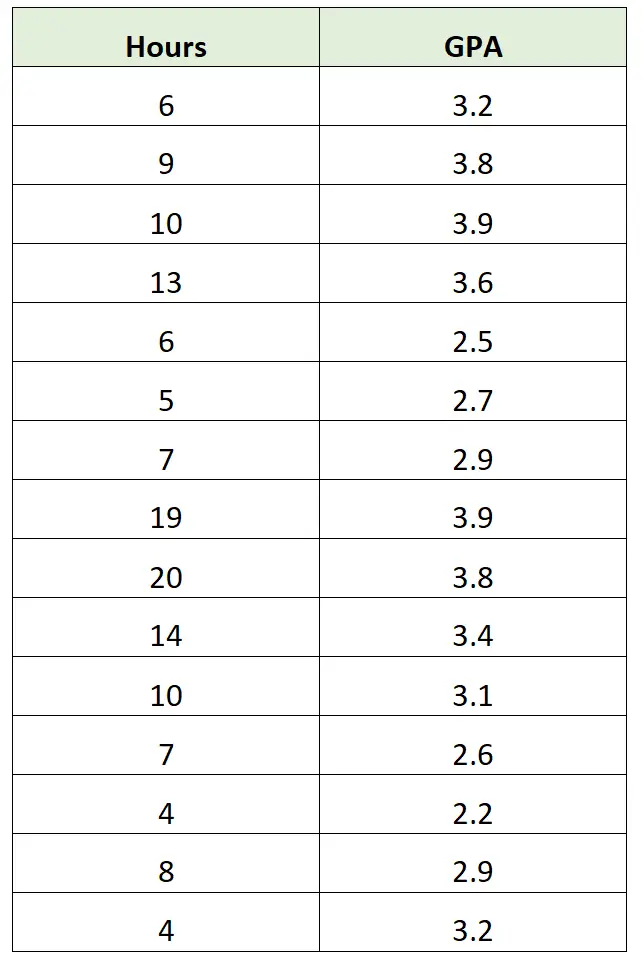
Vervolgens kan ze een eenvoudig spreidingsdiagram maken om de relatie tussen deze twee variabelen te visualiseren:
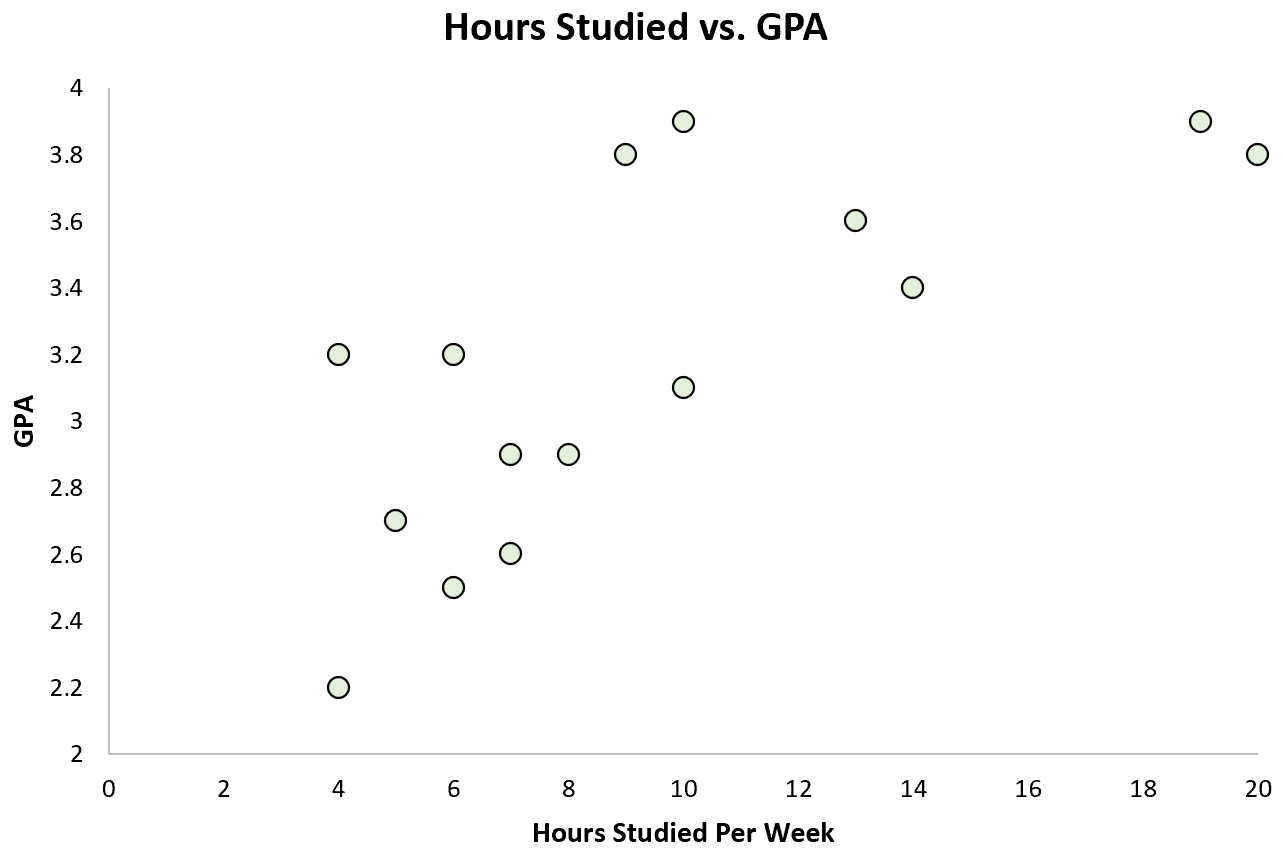
Er is duidelijk een positief verband tussen de twee variabelen: naarmate het aantal uren dat per week wordt gestudeerd toeneemt, neigt ook het GPA van de student toe te nemen.
Voorbeeld 4: Economie
Economen verzamelen vaak bivariate gegevens om de relatie tussen twee sociaal-economische variabelen te begrijpen.
Een econoom kan bijvoorbeeld gegevens verzamelen over het totale aantal jaren scholing en het totale jaarinkomen van individuen in een bepaalde stad:
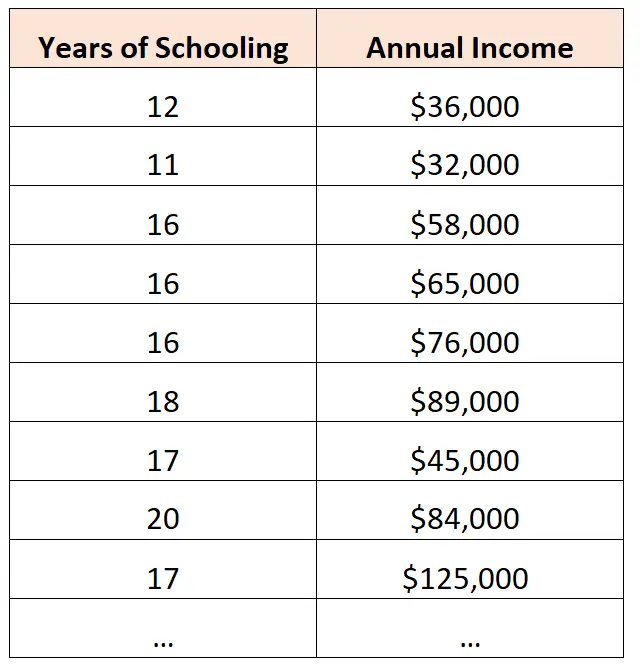
Hij kan dan besluiten het volgende eenvoudige lineaire regressiemodel aan te passen:
Jaarinkomen = -45.353 + 7.120*(jaren scholing)
Dit vertelt de econoom dat voor elk extra jaar scholing het jaarinkomen met gemiddeld $7.120 stijgt.
Voorbeeld 5: Biologie
Biologen verzamelen vaak bivariate gegevens om te begrijpen hoe twee variabelen verband houden tussen planten of dieren.
Een bioloog kan bijvoorbeeld gegevens verzamelen over de totale neerslag en het totale aantal planten in verschillende regio’s:
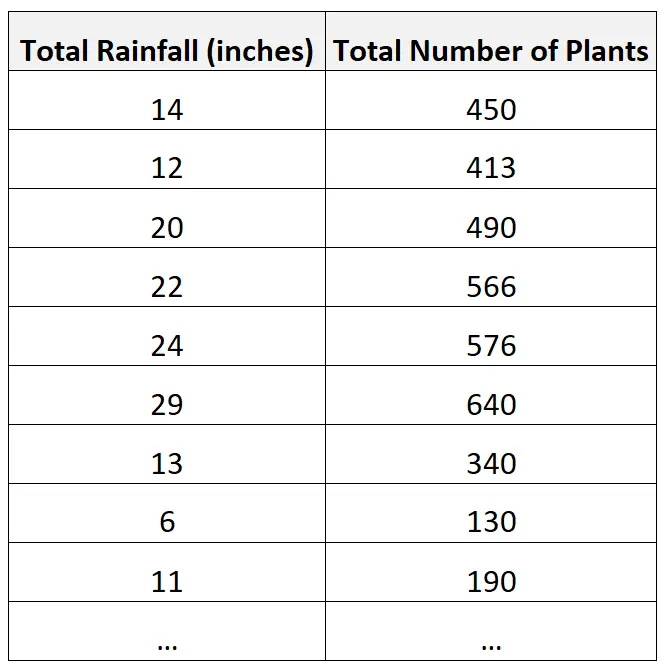
De bioloog kan dan besluiten de correlatie tussen de twee variabelen te berekenen en deze gelijk te stellen aan 0,926 .
Dit geeft aan dat er een sterke positieve correlatie bestaat tussen de twee variabelen.
Dat wil zeggen dat hogere neerslag nauw verband houdt met een groter aantal planten in een regio.
Aanvullende bronnen
De volgende zelfstudies bieden aanvullende informatie over bivariate gegevens en hoe u deze kunt analyseren.
Inleiding tot bivariate analyse
Inleiding tot univariate analyse
Inleiding tot de Pearson-correlatiecoëfficiënt
Inleiding tot eenvoudige lineaire regressie
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder