Gegevens centreren in r (met voorbeelden)
Het centreren van een dataset betekent dat de gemiddelde waarde van elke individuele waarneming in de dataset wordt afgetrokken.
Stel dat we bijvoorbeeld de volgende gegevensset hebben:
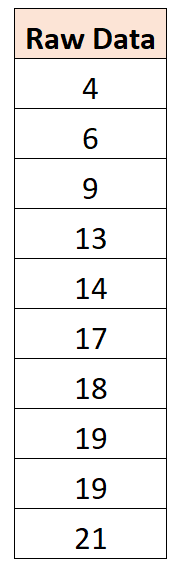
Het blijkt dat de gemiddelde waarde 14 is. Om deze dataset te centreren, trekken we dus 14 af van elke individuele waarneming:
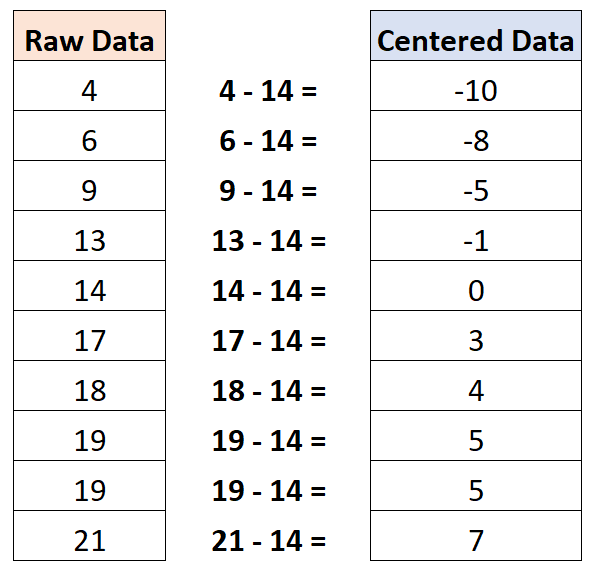
Merk op dat de gemiddelde waarde van de gecentreerde dataset nul is.
Deze zelfstudie biedt verschillende voorbeelden van hoe u gegevens in R kunt centreren.
Voorbeeld 1: Centreer de waarden van een vector
De volgende code laat zien hoe u de base R scale() -functie gebruikt om waarden in een vector te centreren:
#createvector data <- c(4, 6, 9, 13, 14, 17, 18, 19, 19, 21) #subtract the mean value from each observation in the vector scale(data, scale= FALSE ) [,1] [1,] -10 [2,] -8 [3,] -5 [4,] -1 [5,] 0 [6,] 3 [7,] 4 [8,] 5 [9,] 5 [10,] 7 attr(,"scaled:center") [1] 14
De resulterende waarden zijn de gecentreerde waarden van de dataset. De functie scale() vertelt ons ook dat de gemiddelde waarde van de dataset 14 is.
Merk op dat de functie scale() standaard het gemiddelde van elke individuele waarneming aftrekt en dit vervolgens deelt door de standaarddeviatie.
Door scale=FALSE op te geven, vertellen we R dat hij niet moet delen door de standaarddeviatie.
Voorbeeld 2: Kolommen centreren in een gegevensframe
De volgende code laat zien hoe u de functie sapply() en de functie scale() van de R-database gebruikt om de waarden van elke kolom van een dataframe te centreren:
#create data frame df <- data.frame(x = c(1, 4, 5, 6, 6, 8, 9), y = c(7, 7, 8, 8, 8, 9, 12), z = c(3, 3, 4, 4, 6, 7, 7)) #center each column in the data frame df_new <- sapply(df, function (x) scale(x, scale= FALSE )) #display data frame df_new X Y Z [1,] -4.5714286 -1.4285714 -1.8571429 [2,] -1.5714286 -1.4285714 -1.8571429 [3,] -0.5714286 -0.4285714 -0.8571429 [4,] 0.4285714 -0.4285714 -0.8571429 [5,] 0.4285714 -0.4285714 1.1428571 [6,] 2.4285714 0.5714286 2.1428571 [7,] 3.4285714 3.5714286 2.1428571
We kunnen controleren of het gemiddelde van elke kolom in het nieuwe dataframe nul is met behulp van de colMeans() functie:
colMeans(df_new)
xyz 2.537653e-16 -2.537653e-16 3.806479e-16
Waarden worden weergegeven in wetenschappelijke notatie, maar elke waarde is in wezen nul.
Aanvullende bronnen
Hoe u het gemiddelde kunt nemen over kolommen in R
Hoe specifieke kolommen in R op te tellen
Hoe u uitschieters uit meerdere kolommen in R kunt verwijderen
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder