Hoe u een chikwadraat-goodness of fit-test uitvoert in stata
Een chikwadraat-goodness-of-fit-test wordt gebruikt om te bepalen of een categorische variabele al dan niet een hypothetische verdeling volgt.
In deze tutorial wordt uitgelegd hoe u een chikwadraat-goodness-of-fit-test uitvoert in Stata.
Voorbeeld: Chi-kwadraat goodness-of-fit-test in Stata
Om te illustreren hoe deze test moet worden uitgevoerd, zullen we een dataset gebruiken met de naam nlsw88 , die informatie bevat over de arbeidsstatistieken van vrouwen in de Verenigde Staten in 1988.
Volg de volgende stappen om een chikwadraat-goodness-of-fit-test uit te voeren om te bepalen of de werkelijke verdeling van ras in deze dataset is: 70% blank, 20% zwart, 10% anders.
Stap 1: Onbewerkte gegevens laden en weergeven.
Eerst zullen we de gegevens laden door de volgende opdracht te typen:
nlsw88-systeem
We kunnen de onbewerkte gegevens bekijken door de volgende opdracht te typen:
br
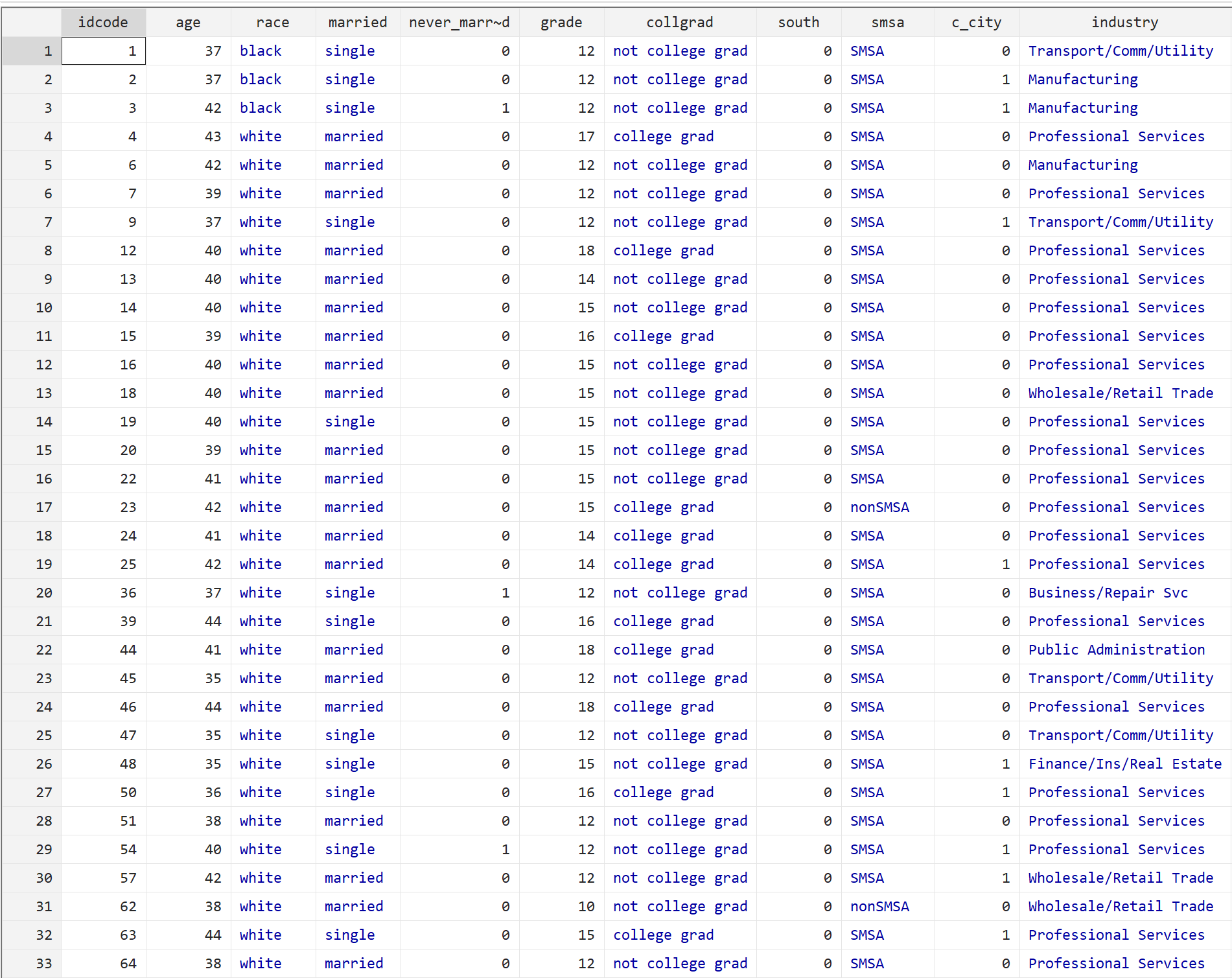
Elke rij geeft informatie over een persoon weer, waaronder leeftijd, ras, burgerlijke staat, opleidingsniveau en diverse andere factoren.
Stap 2: Laad het aanpassingspakket.
Om een geschiktheidstest uit te voeren, moeten we het csgof- pakket installeren. We kunnen dit doen door het volgende commando te typen:
csgof vinden
Er verschijnt een nieuw venster. Klik op de link met de tekst csgof van https://stats.idre.ucla.edu/stat/stata/ado/analysis .
Er verschijnt een ander venster. Klik op de link met de tekst Klik hier om te installeren .
Het installeren van het pakket duurt slechts enkele seconden.
Stap 3: Voer de fittest uit.
Zodra het pakket is geïnstalleerd, kunnen we de goodness-of-fit-test uitvoeren op de gegevens om te bepalen of de werkelijke race-indeling als volgt is: 70% blank, 20% zwart, 10% anders.
We zullen de volgende syntaxis gebruiken om de test uit te voeren:
csgof variabele_van_rente, expperc(lijst_van_verwachte_percentages)
Hier is de exacte syntaxis die we in ons geval zullen gebruiken:
voer csgof, expperc(70, 20, 10) uit

Zo interpreteert u het resultaat:
Samenvattingsvak: Dit vak toont ons het verwachte percentage, de verwachte frequentie en de waargenomen frequentie voor elke race. Bijvoorbeeld:
- Het verwachte percentage blanke individuen was 70%. Dit is het percentage dat wij hebben opgegeven.
- De verwachte frequentie van blanke individuen was 1.572,2. Dit wordt berekend op basis van het feit dat er 2.246 individuen in de dataset zaten, dus 70% van dat aantal is 1.572,2.
- De waargenomen frequentie van blanke individuen was 1.637. Dit is het werkelijke aantal blanke individuen in de dataset.
Chisq(2): Dit is de Chi-kwadraat-teststatistiek voor de goodness-of-fit-test. Het blijkt 218.13 te zijn.
p: Dit is de p-waarde die is gekoppeld aan de Chi-kwadraattoetsstatistiek. Het blijkt 0 te zijn. Omdat het minder dan 0,05 is, slagen we er niet in de nulhypothese te verwerpen dat de werkelijke raciale verdeling 70% blank, 20% zwart en 10% anderen is. We hebben voldoende bewijs om te concluderen dat de werkelijke raciale verdeling verschilt van deze hypothetische verdeling.
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder