Hoe u een chow-test uitvoert in python
Een Chow-test wordt gebruikt om te testen of de coëfficiënten van twee verschillende regressiemodellen op verschillende datasets gelijk zijn.
Deze test wordt doorgaans gebruikt op het gebied van de econometrie met tijdreeksgegevens om te bepalen of er op een bepaald moment een structurele breuk in de gegevens is.
Het volgende stapsgewijze voorbeeld laat zien hoe u een Chow-test in Python uitvoert.
Stap 1: Creëer de gegevens
Eerst zullen we valse gegevens creëren:
import pandas as pd #createDataFrame df = pd. DataFrame ({' x ': [1, 1, 2, 3, 4, 4, 5, 5, 6, 7, 7, 8, 8, 9, 10, 10, 11, 12, 12, 13, 14, 15, 15, 16, 17, 18, 18, 19, 20, 20], ' y ': [3, 5, 6, 10, 13, 15, 17, 14, 20, 23, 25, 27, 30, 30, 31, 33, 32, 32, 30, 32, 34, 34, 37, 35, 34, 36, 34, 37, 38, 36]}) #view first five rows of DataFrame df. head () x y 0 1 3 1 1 5 2 2 6 3 3 10 4 4 13
Stap 2: Visualiseer de gegevens
Vervolgens maken we een eenvoudig spreidingsdiagram om de gegevens te visualiseren:
import matplotlib. pyplot as plt
#create scatterplot
plt. plot (df. x , df. y , ' o ')
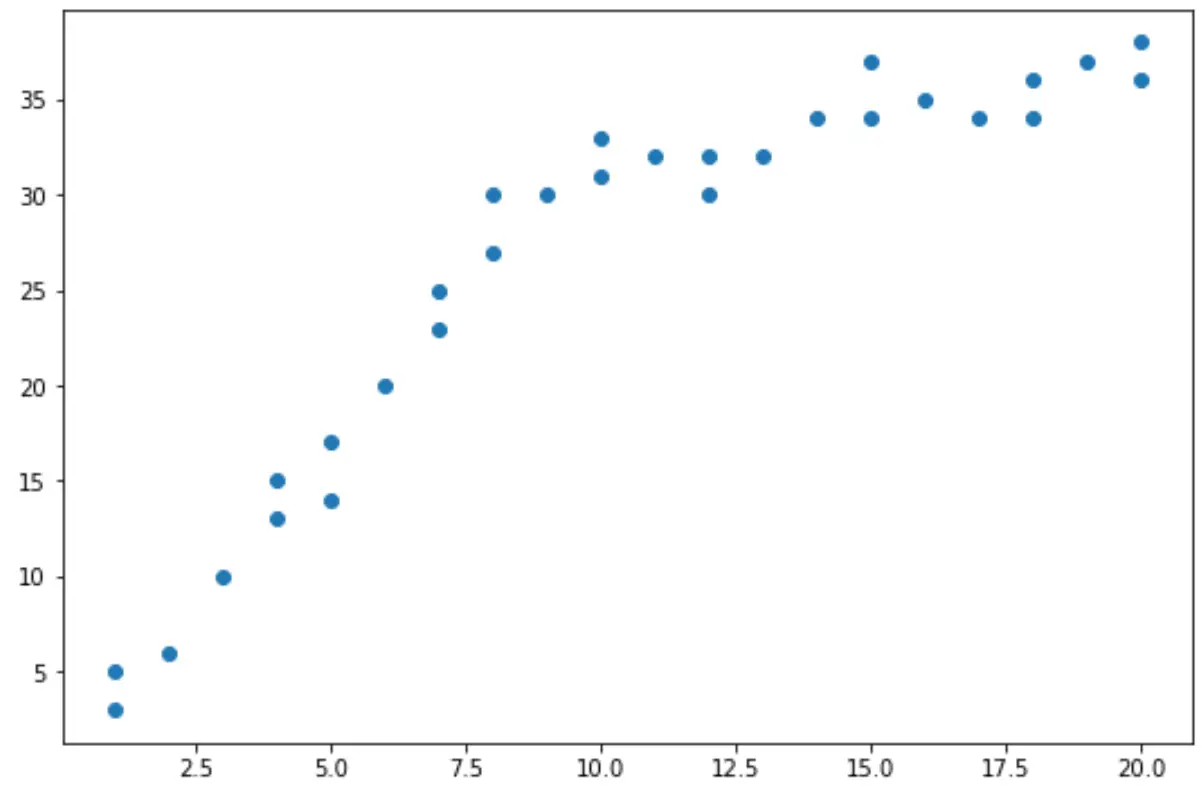
Uit het spreidingsdiagram kunnen we zien dat de trend in de gegevens lijkt te veranderen bij x = 10.
We kunnen dus de Chow-test uitvoeren om te bepalen of er een structureel breekpunt in de gegevens is op x = 10.
Stap 3: Voer de Chow-test uit
We kunnen de chowtest-functie van het chowtest- pakket in Python gebruiken om een Chow-test uit te voeren.
Eerst moeten we dit pakket installeren met pip:
pip install chowtest
Vervolgens kunnen we de volgende syntaxis gebruiken om de Chow-test uit te voeren:
from chow_test import chowtest chowtest ( y=df[[' y ']], last_index_in_model_1= 15 , first_index_in_model_2= 16 , significance_level= .05 ) ************************************************** ********************************* Reject the null hypothesis of equality of regression coefficients in the 2 periods. ************************************************** ********************************* Chow Statistic: 118.14097335479373 p value: 0.0 ************************************************** ********************************* (118.14097335479373, 1.1102230246251565e-16)
Dit is wat de individuele argumenten in de chowtest() functie betekenen:
- y : De responsvariabele in het DataFrame
- x : De voorspellende variabele in het DataFrame
- last_index_in_model_1 : De indexwaarde van het laatste punt vóór de structurele breuk
- first_index_in_model_2 : De indexwaarde voor het eerste punt na de structurele breuk
- significantieniveau : het significantieniveau dat moet worden gebruikt voor de hypothesetest
Uit het testresultaat kunnen we zien:
- F-teststatistiek : 118.14
- p-waarde: <.0000
Omdat de p-waarde kleiner is dan 0,05, kunnen we de nulhypothese van de test verwerpen. Dit betekent dat we voldoende bewijs hebben om te zeggen dat er een structureel breekpunt in de gegevens aanwezig is.
Met andere woorden: twee regressielijnen kunnen het model effectiever in de gegevens passen dan één enkele regressielijn.
Aanvullende bronnen
In de volgende tutorials wordt uitgelegd hoe u andere veelvoorkomende tests in Python uitvoert:
Hoe u een Granger-causaliteitstest uitvoert in Python
Hoe een Breusch-Pagan-test uit te voeren in Python
Hoe de test van White in Python uit te voeren
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder