Hoe u dummyvariabelen in excel kunt maken (stap voor stap)
Een dummyvariabele is een type variabele die we creëren in regressieanalyse, zodat we een categorische variabele kunnen weergeven als een numerieke variabele die een van de twee waarden kan aannemen: nul of één.
Stel dat we de volgende gegevensset hebben en leeftijd en burgerlijke staat willen gebruiken om het inkomen te voorspellen:

Om de burgerlijke staat als voorspellende variabele in een regressiemodel te gebruiken, moeten we deze omzetten in een dummyvariabele.
Omdat dit momenteel een categorische variabele is die drie verschillende waarden kan aannemen („Single“, „Married“ of „Divorced“), moeten we k -1 = 3-1 = 2 dummyvariabelen maken.
Om deze dummyvariabele te maken, kunnen we ‚Single‘ als basiswaarde laten staan, aangezien deze het vaakst voorkomt. Zo zetten we de burgerlijke staat om in dummyvariabelen:

Deze zelfstudie biedt een stapsgewijs voorbeeld van hoe u dummyvariabelen voor deze exacte gegevensset in Excel kunt maken en vervolgens een regressieanalyse kunt uitvoeren met deze dummyvariabelen als voorspellers.
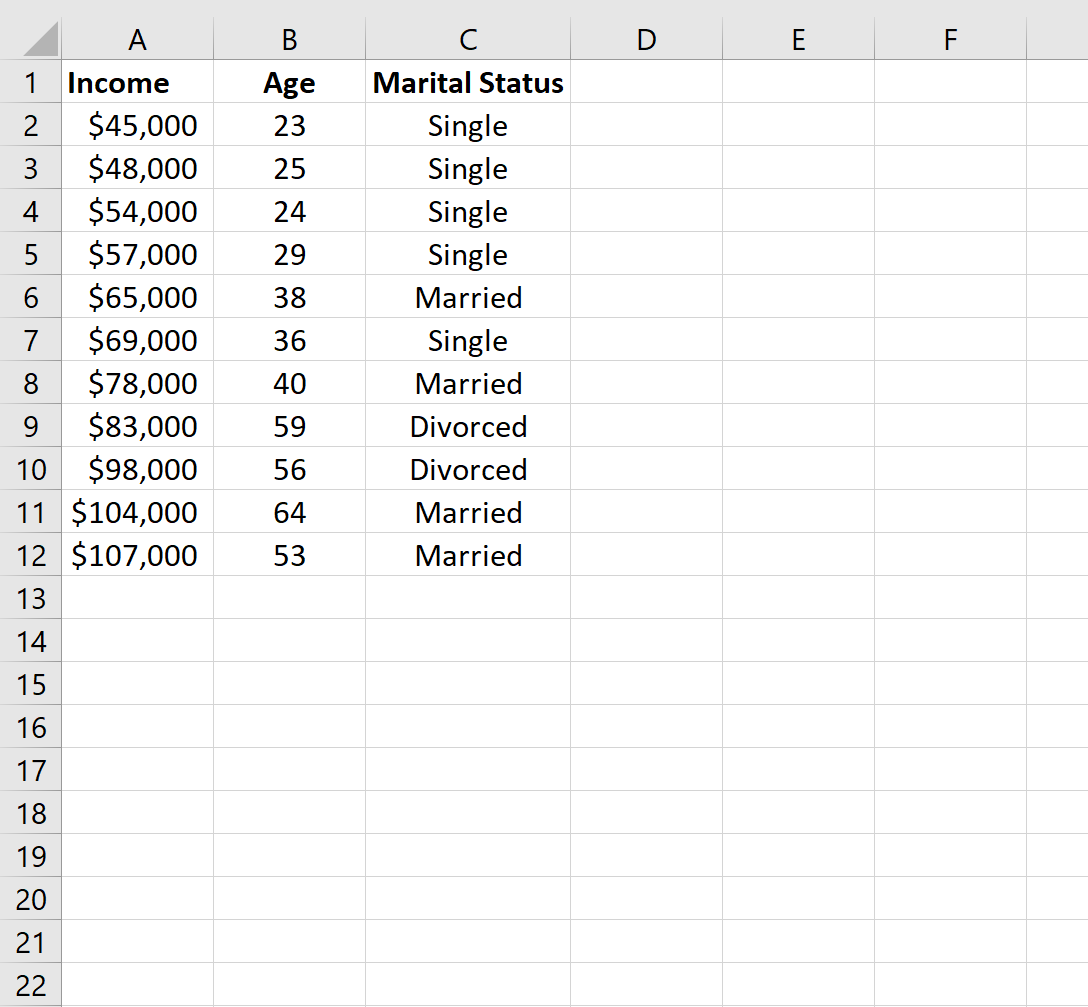
Stap 1: Creëer de gegevens
Laten we eerst de gegevensset in Excel maken:
Stap 2: Maak de dummyvariabelen
Vervolgens kunnen we de waarden uit de kolommen A en B naar de kolommen E en F kopiëren en vervolgens de functie IF() in Excel gebruiken om twee nieuwe dummyvariabelen te definiëren: Getrouwd en Gescheiden.
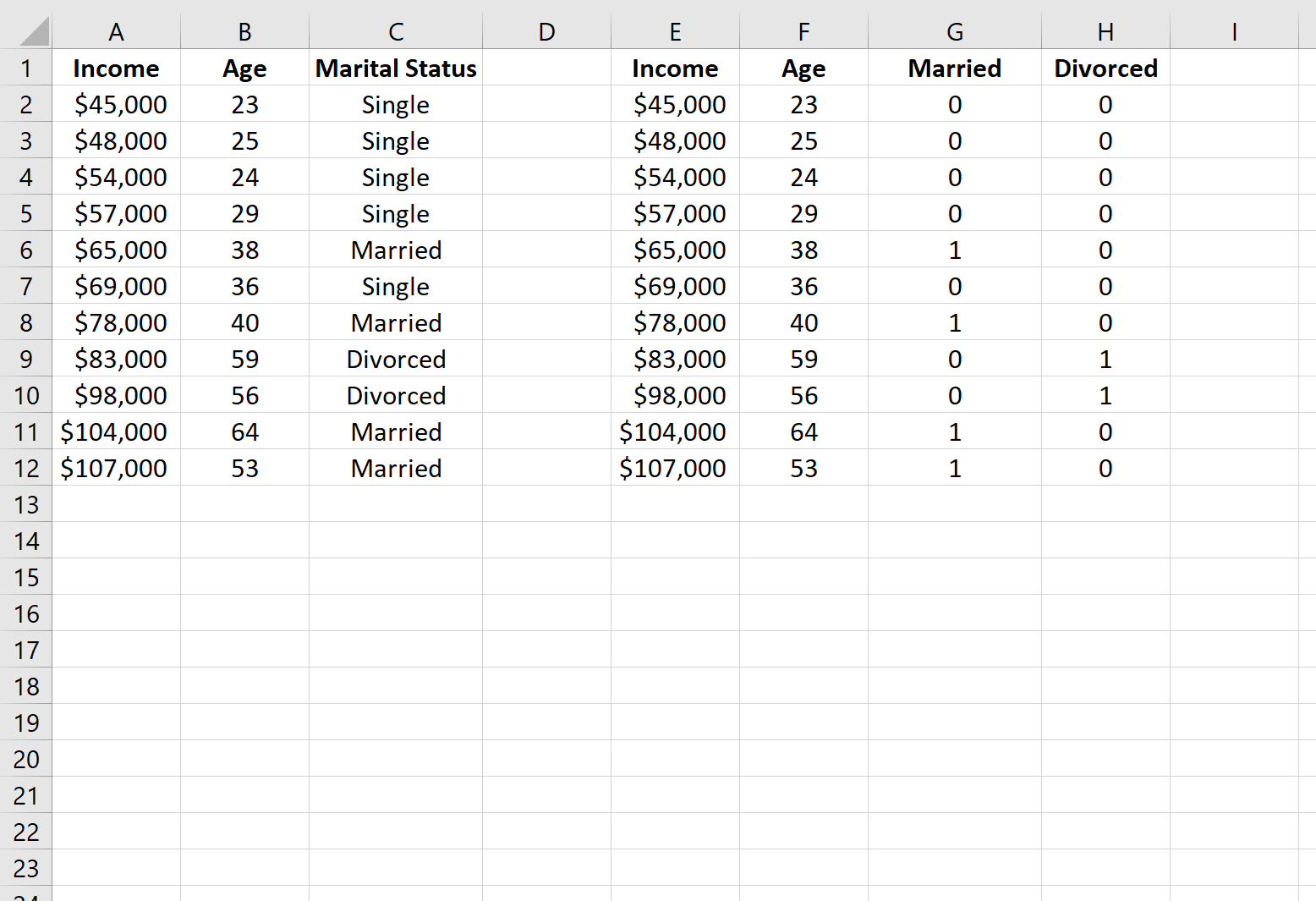
Dit is de formule die we hebben gebruikt in cel G2 en die we hebben gekopieerd naar de rest van de cellen in kolom G:
= IF (C2 = "Married", 1, 0)
En hier is de formule die we gebruikten in cel H2 , die we gekopieerd hebben naar de rest van de cellen in kolom H:
= IF (C2 = "Divorced", 1, 0)
Vervolgens kunnen we deze dummyvariabelen in een regressiemodel gebruiken om het inkomen te voorspellen.
Stap 3: Voer lineaire regressie uit
Om meervoudige lineaire regressie uit te voeren, moeten we op het tabblad Gegevens op het bovenste lint klikken en vervolgens op Gegevensanalyse klikken in het gedeelte Analyse :
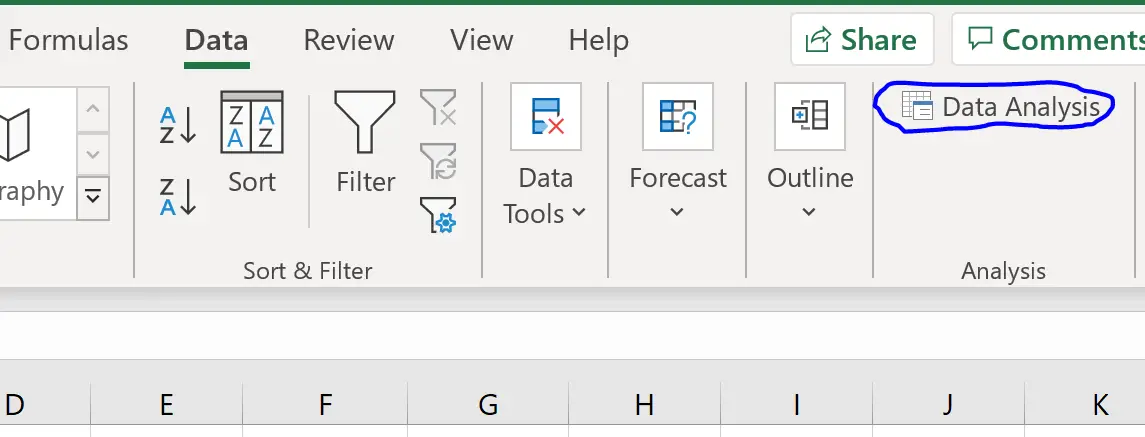
Als deze optie niet beschikbaar is, moet u eerst Analysis Toolpak laden.
In het venster dat verschijnt, klikt u op Regressie en vervolgens op OK .
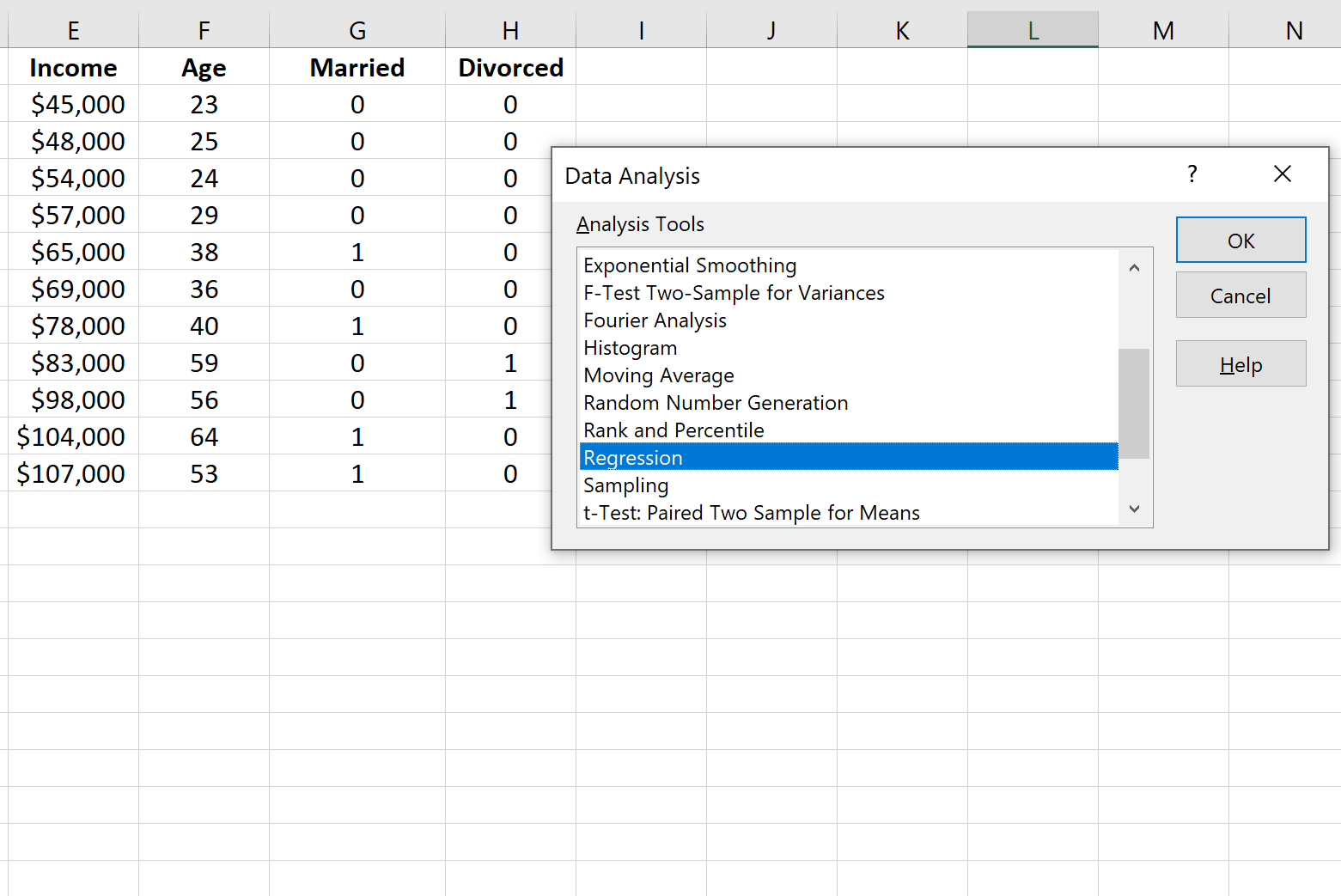
Vul vervolgens de volgende gegevens in en klik op OK .
Dit levert het volgende resultaat op:
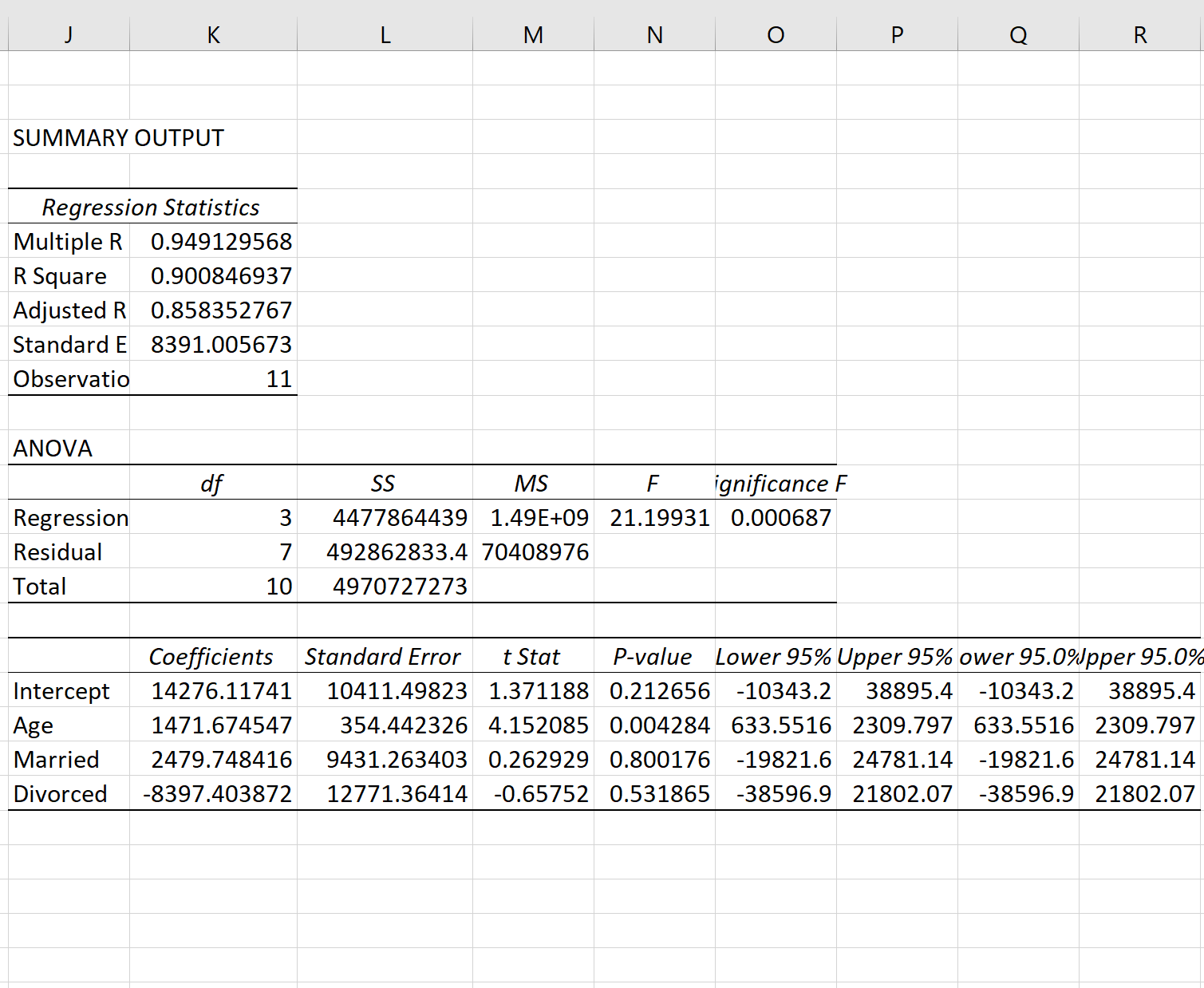
Uit het resultaat kunnen we zien dat de aangepaste regressielijn is:
Inkomen = 14.276,12 + 1.471,67*(leeftijd) + 2.479,75*(gehuwd) – 8.397,40*(gescheiden)
We kunnen deze vergelijking gebruiken om het geschatte inkomen van een persoon te vinden op basis van zijn leeftijd en burgerlijke staat. Een persoon van 35 jaar en getrouwd zou bijvoorbeeld een geschat inkomen hebben van $ 68.264 :
Inkomen = 14.276,12 + 1.471,67*(35) + 2.479,75*(1) – 8.397,40*(0) = $68.264
Zo interpreteert u de regressiecoëfficiënten in de tabel:
- Intercept: Het intercept vertegenwoordigt het gemiddelde inkomen van een alleenstaande van nul jaar oud. Omdat een individu niet nul jaar oud kan zijn, heeft het in dit specifieke regressiemodel geen zin om het intercept op zichzelf te interpreteren.
- Leeftijd: Elk jaar dat de leeftijd stijgt, gaat gepaard met een gemiddelde inkomensstijging van $ 1.471,67. Omdat de p-waarde (0,004) kleiner is dan 0,05, is leeftijd een statistisch significante voorspeller van het inkomen.
- Getrouwd: Een getrouwde persoon verdient gemiddeld €2.479,75 meer dan een alleenstaande. Omdat de p-waarde (0,800) niet kleiner is dan 0,05, is dit verschil niet statistisch significant.
- Gescheiden: Een gescheiden persoon verdient gemiddeld €8.397,40 minder dan een alleenstaande. Omdat de p-waarde (0,532) niet kleiner is dan 0,05, is dit verschil niet statistisch significant.
Omdat beide dummyvariabelen niet statistisch significant waren, konden we de burgerlijke staat als voorspeller uit het model verwijderen, omdat deze geen voorspellende waarde lijkt toe te voegen aan het inkomen.
Aanvullende bronnen
Hoe u eenvoudige lineaire regressie uitvoert in Excel
Hoe de resterende som van kwadraten in Excel te berekenen
Hoe polynomiale regressie uit te voeren in Excel
Hoe u een restplot in Excel maakt
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder