Excel: dubbele rijen verwijderen op basis van een kolom
Vaak wilt u mogelijk dubbele rijen verwijderen op basis van een kolom in Excel.
Gelukkig is dit eenvoudig te doen met de functie Duplicaten verwijderen op het tabblad Gegevens .
Het volgende voorbeeld laat zien hoe u deze functie in de praktijk kunt gebruiken.
Voorbeeld: duplicaten verwijderen op basis van een kolom in Excel
Stel dat we de volgende gegevensset in Excel hebben die informatie bevat over verschillende basketbalspelers:
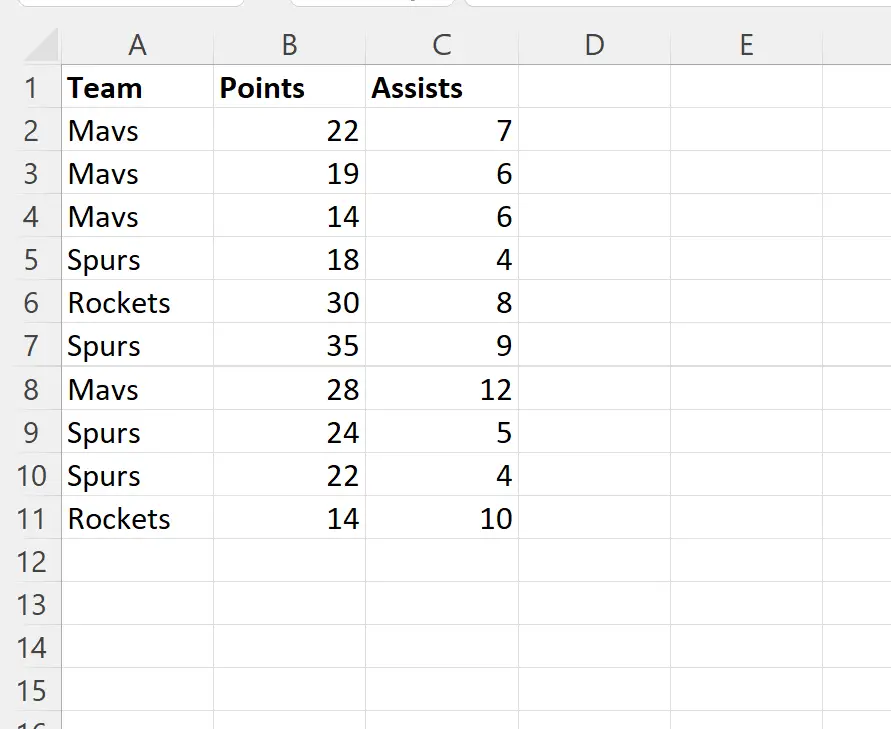
Houd er rekening mee dat er verschillende dubbele waarden in de kolom Team staan.
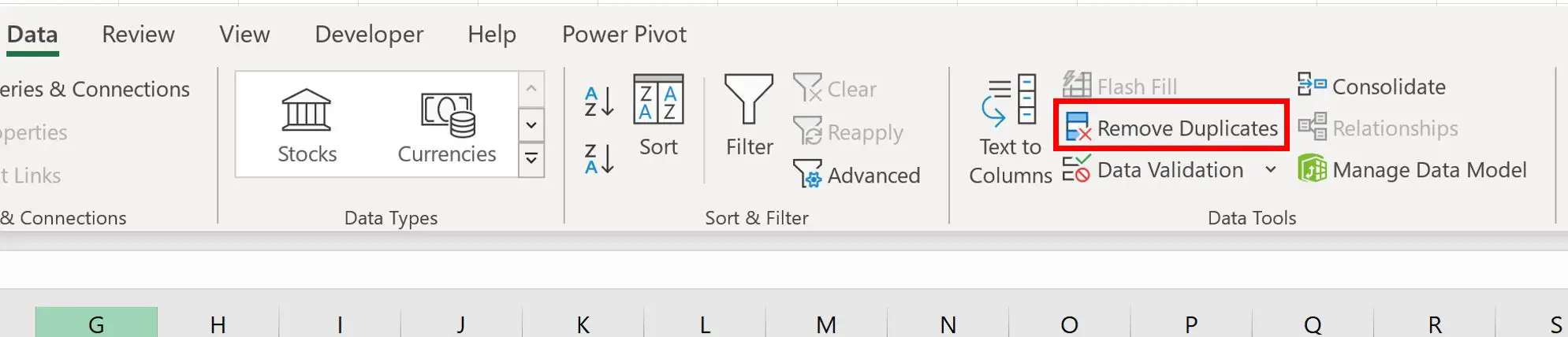
Als u rijen met dubbele waarden in de kolom Team wilt verwijderen, markeert u het celbereik A1:C11 , klikt u vervolgens op het tabblad Gegevens op het bovenste lint en klikt u vervolgens op Duplicaten verwijderen :
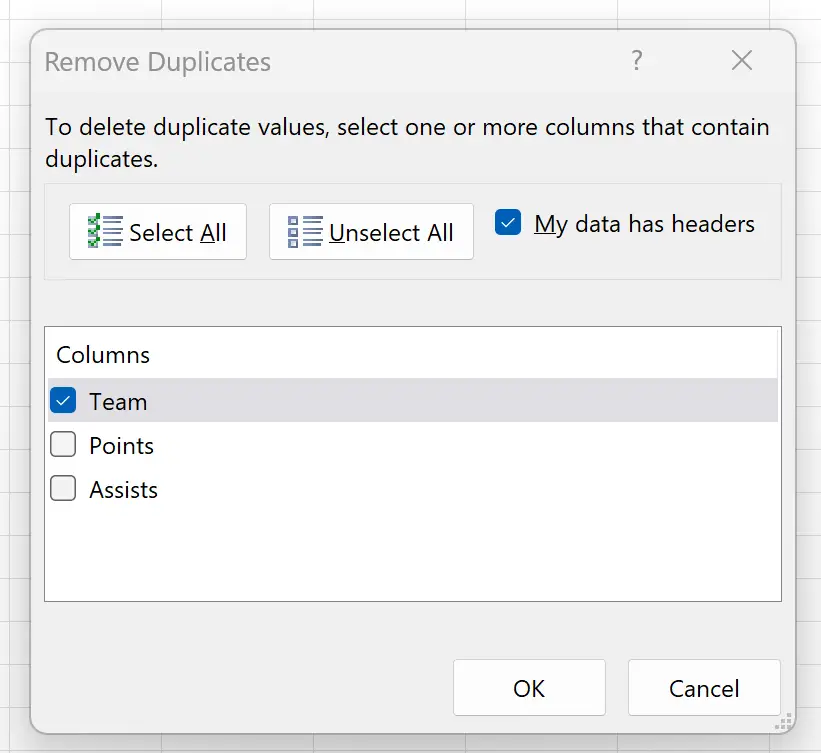
Zorg ervoor dat in het nieuwe venster dat verschijnt het vakje naast Mijn gegevens hebben kopteksten is aangevinkt en zorg ervoor dat alleen het vakje naast Team is aangevinkt:
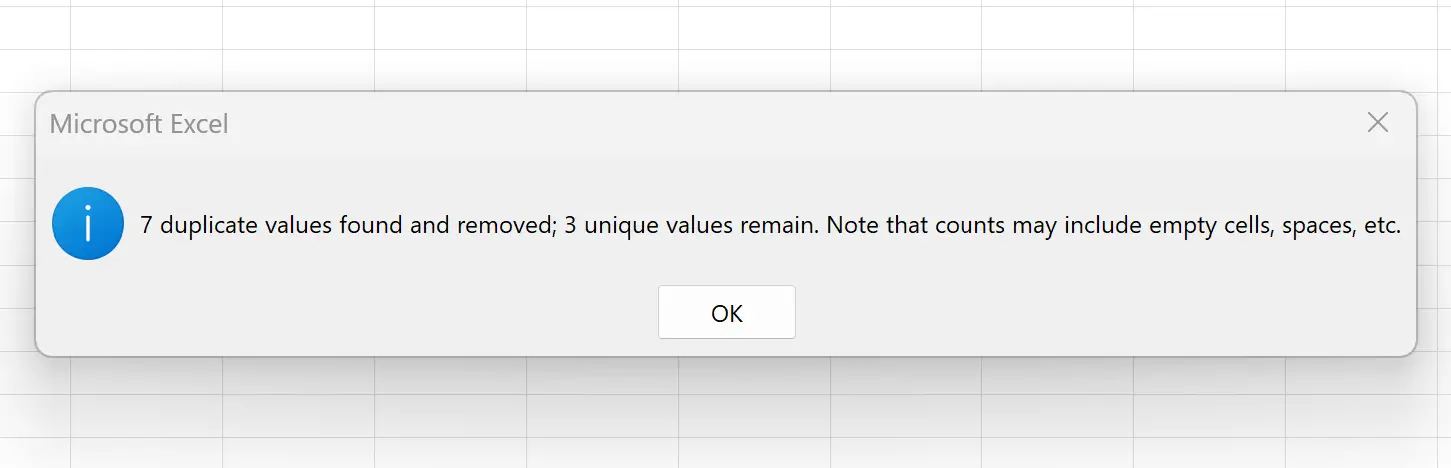
Zodra u op OK klikt, worden de rijen met dubbele waarden in de kolom Team automatisch verwijderd:
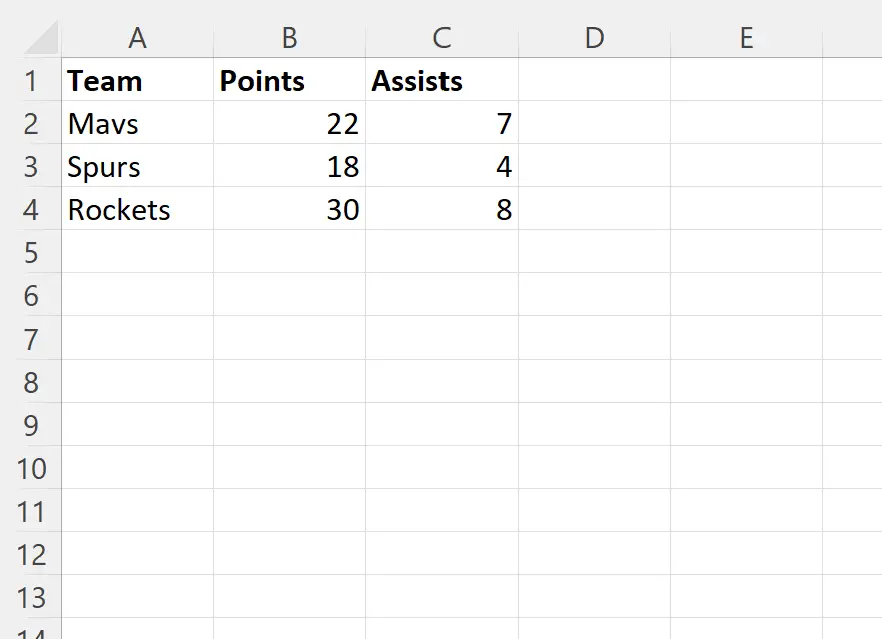
Excel vertelt ons dat er zeven dubbele rijen zijn gevonden en verwijderd en dat er nog drie unieke rijen over zijn.
Houd er rekening mee dat geen van de overige rijen dubbele waarden heeft in de kolom Team .
Houd er ook rekening mee dat de regel met de eerste vermelding van elke unieke teamnaam behouden blijft.
Bijvoorbeeld:
- De rij met Mavs, 22 punten en 7 assists is de eerste rij in de dataset met „Mavs“ in de Team- kolom.
- De rij met Spurs, 18 punten en 4 assists is de eerste rij in de dataset met ‘Spurs’ in de Team- kolom.
Enzovoort.
Aanvullende bronnen
In de volgende zelfstudies wordt uitgelegd hoe u andere veelvoorkomende bewerkingen in Excel uitvoert:
Excel: rijen met specifieke tekst verwijderen
Excel: lege cellen negeren bij het gebruik van formules
Excel geavanceerd filter: toon rijen met niet-lege waarden
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder