Wat zijn gekoppelde gegevens? (uitleg & voorbeelden)
Wanneer twee datasets even lang zijn en elke waarneming uit de ene dataset kan worden „gepaard“ met een waarneming uit een andere dataset, noemen we dit gepaarde gegevens .

Om twee datasets te kunnen associëren, is het belangrijk dat elke waarneming uit de ene dataset slechts kan worden geassocieerd met één waarneming uit de andere dataset.
Voorbeelden van overeenkomende gegevens
Hier volgen enkele voorbeelden van overeenkomende gegevens:
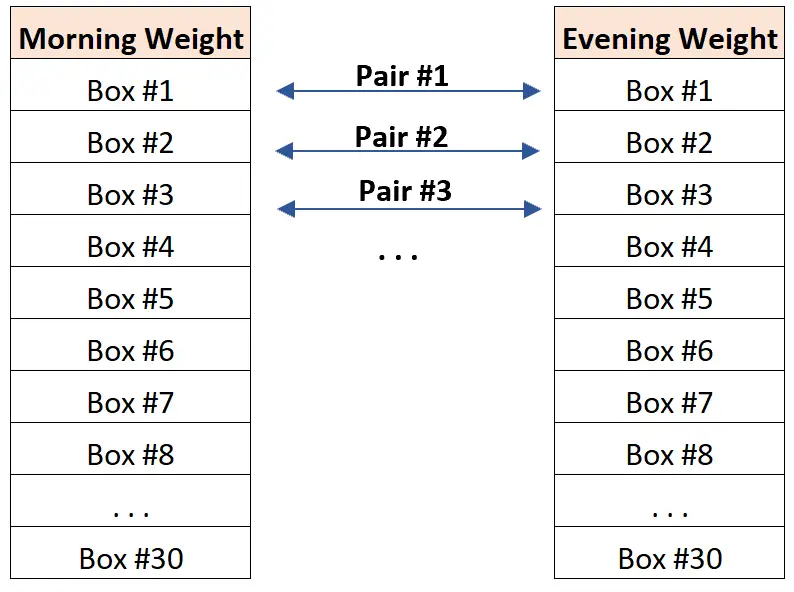
Voorbeeld 1: Dubbele metingen.
Stel dat onderzoekers willen weten of een weegschaal in een bepaald magazijn op alle uren van de dag dozen kan wegen. Om dit te testen gebruiken onderzoekers de weegschaal om ’s ochtends en ’s avonds dertig verschillende dozen te wegen.
Het eindresultaat zijn twee datasets waarin de ochtend- en avondgewichten van elke box aan elkaar kunnen worden ‚gematcht‘.
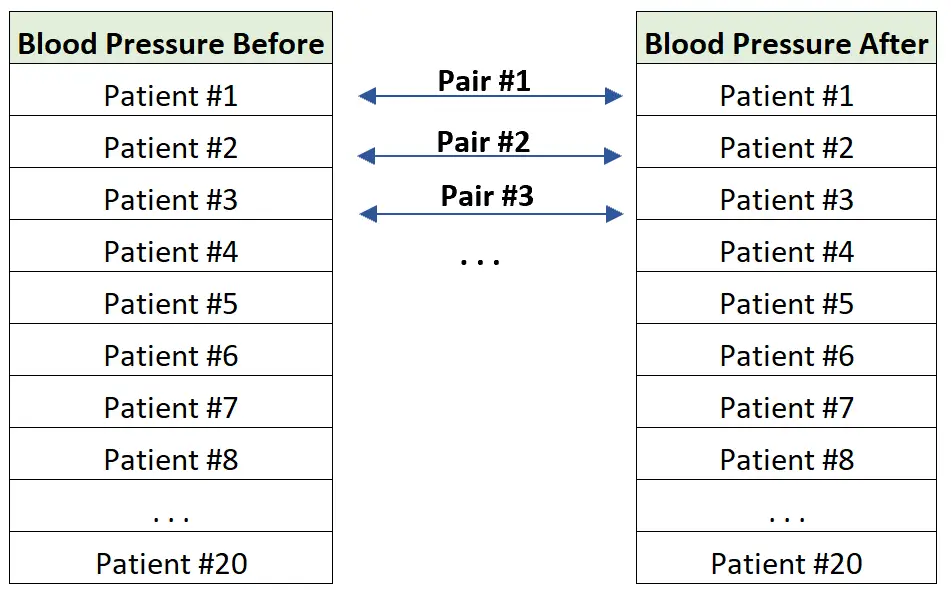
Voorbeeld 2: metingen vooraf.
Een arts wil weten of een nieuw medicijn de bloeddruk van patiënten kan verlagen. Om dit te testen mat hij de bloeddruk van twintig verschillende patiënten, voor en na een week lang gebruik van het medicijn.
Het eindresultaat zijn twee sets gegevens, waarin de bloeddruk voor en na elk individu met zichzelf kan worden ‘gematcht’.
Gekoppelde gegevens analyseren
Er zijn twee veelgebruikte manieren om gepaarde gegevens te analyseren:
1. Voer een gepaarde t-test uit.
Eén manier om gepaarde gegevens te analyseren is door een t-test voor gepaarde monsters uit te voeren, waarbij de gemiddelden van twee monsters worden vergeleken wanneer elke waarneming uit het ene monster kan worden gematcht met een waarneming uit het andere monster.
Deze test vertelt ons of de gemiddelde waarde gelijk is tussen de twee datasets.
2. Bereken de correlatie tussen de twee datasets.
Een andere manier om gepaarde gegevens te analyseren is door decorrelatie tussen de twee gegevenssets te berekenen.
Dit geeft ons een idee van de richting en sterkte van de relatie tussen de waarden van de twee datasets.
Gekoppelde gegevens en ongeëvenaarde gegevens
In tegenstelling tot gepaarde gegevens komen ongepaarde gegevens voor wanneer waarnemingen uit de ene dataset niet op unieke wijze kunnen worden geassocieerd met een waarneming uit een andere dataset.
Laten we bijvoorbeeld zeggen dat onderzoekers willen weten of een bepaald trainingsprogramma de gemiddelde verticale sprong van basketbalspelers vergroot.
Eén manier om dit te testen met behulp van gematchte gegevens is het meten van de maximale verticale sprong van dezelfde 20 spelers voor en na gebruik van het trainingsprogramma:

Om dit te testen met behulp van ongepaarde data , konden de onderzoekers de maximale verticale sprong meten van 20 spelers die het trainingsprogramma niet hadden gebruikt, en vervolgens de maximale verticale sprong meten van 20 verschillende spelers die het trainingsprogramma hadden gebruikt. ‚opleiding:
Wanneer we met gepaarde gegevens werken, gebruiken we een gepaarde steekproeven-t-test om te bepalen of het verschil tussen de steekproefgemiddelden verschillend is.
En als we met ongepaarde gegevens werken, gebruiken we een independent samples t-test om te bepalen of het verschil tussen de steekproefgemiddelden verschillend is.
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder