Een normale verdeling in r genereren (met voorbeelden)
U kunt snel eennormale verdeling in R genereren met behulp van de functie rnorm() , die de volgende syntaxis gebruikt:
rnorm(n, mean=0, sd=1)
Goud:
- n: Aantal waarnemingen.
- gemiddelde: gemiddelde van de normale verdeling. De standaardwaarde is 0.
- sd: standaarddeviatie van de normale verdeling. De standaardwaarde is 1.
Deze tutorial toont een voorbeeld van het gebruik van deze functie om een normale verdeling in R te genereren.
Gerelateerd: Een gids voor dnorm, pnorm, qnorm en rnorm in R
Voorbeeld: het genereren van een normale verdeling in R
De volgende code laat zien hoe u een normale verdeling in R genereert:
#make this example reproducible set.seed(1) #generate sample of 200 obs. that follows normal dist. with mean=10 and sd=3 data <- rnorm(200, mean=10, sd=3) #view first 6 observations in sample head(data) [1] 8.120639 10.550930 7.493114 14.785842 10.988523 7.538595
We kunnen snel het gemiddelde en de standaardafwijking van deze verdeling vinden:
#find mean of sample
mean(data)
[1] 10.10662
#find standard deviation of sample
sd(data)
[1] 2.787292
We kunnen ook een snel histogram maken om de verdeling van gegevenswaarden te visualiseren:
hist(data, col=' steelblue ')
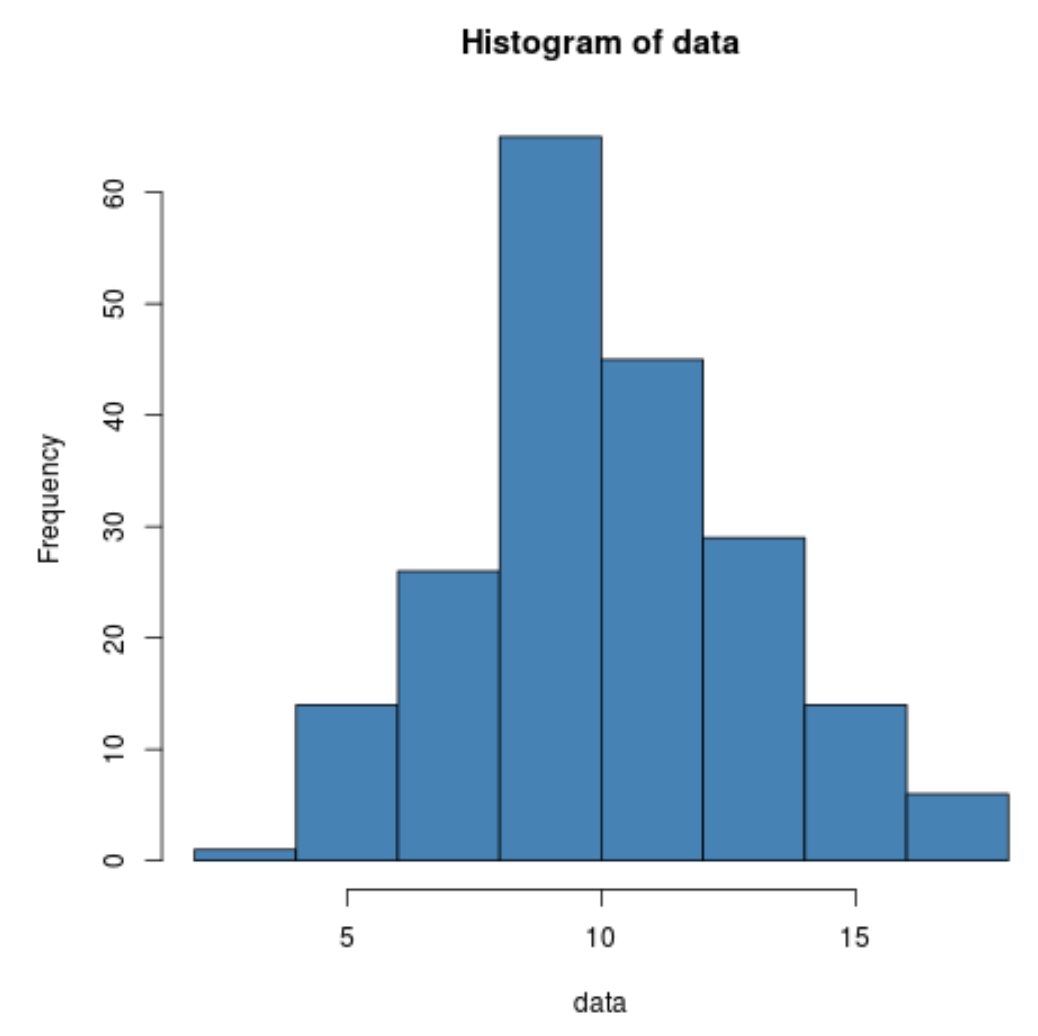
We kunnen zelfs een Shapiro-Wilk-test uitvoeren om te zien of de dataset uit een normale populatie komt:
shapiro.test(data)
Shapiro-Wilk normality test
data:data
W = 0.99274, p-value = 0.4272
De p-waarde van de test blijkt 0,4272 te zijn. Omdat deze waarde niet kleiner is dan 0,05, kunnen we aannemen dat de steekproefgegevens afkomstig zijn uit een normaal verdeelde populatie.
Dit resultaat zou geen verrassing moeten zijn, aangezien we de gegevens hebben gegenereerd met behulp van de functie rnorm() , die op natuurlijke wijze een willekeurige steekproef van gegevens uit een normale verdeling genereert.
Aanvullende bronnen
Hoe een normale verdeling in R te plotten
Een gids voor dnorm, pnorm, qnorm en rnorm in R
Hoe een Shapiro-Wilk-test uit te voeren voor normaliteit in R
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder