Hoe u een paired samples t-test uitvoert op een ti-84-rekenmachine
Een paired samples t-test wordt gebruikt om de gemiddelden van twee monsters te vergelijken wanneer elke waarneming in het ene monster kan worden geassocieerd met een waarneming in het andere monster.
In deze tutorial wordt uitgelegd hoe u een gepaarde t-test uitvoert op een TI-84-rekenmachine.
Voorbeeld: t-test met gepaarde steekproeven op een TI-84-rekenmachine
Onderzoekers willen weten of een nieuwe brandstofbehandeling een verandering in het gemiddelde mpg van een bepaalde auto veroorzaakt. Om dit te testen voeren ze een experiment uit waarbij ze het mpg meten van 11 auto’s met en zonder brandstofbehandeling.
Omdat elke auto de behandeling krijgt, kunnen we een gepaarde t-test uitvoeren waarbij elke auto aan zichzelf wordt gekoppeld om te bepalen of er een verschil is in het gemiddelde mpg met en zonder de brandstofbehandeling.
Voer de volgende stappen uit om een gepaarde t-test uit te voeren op een TI-84-rekenmachine.
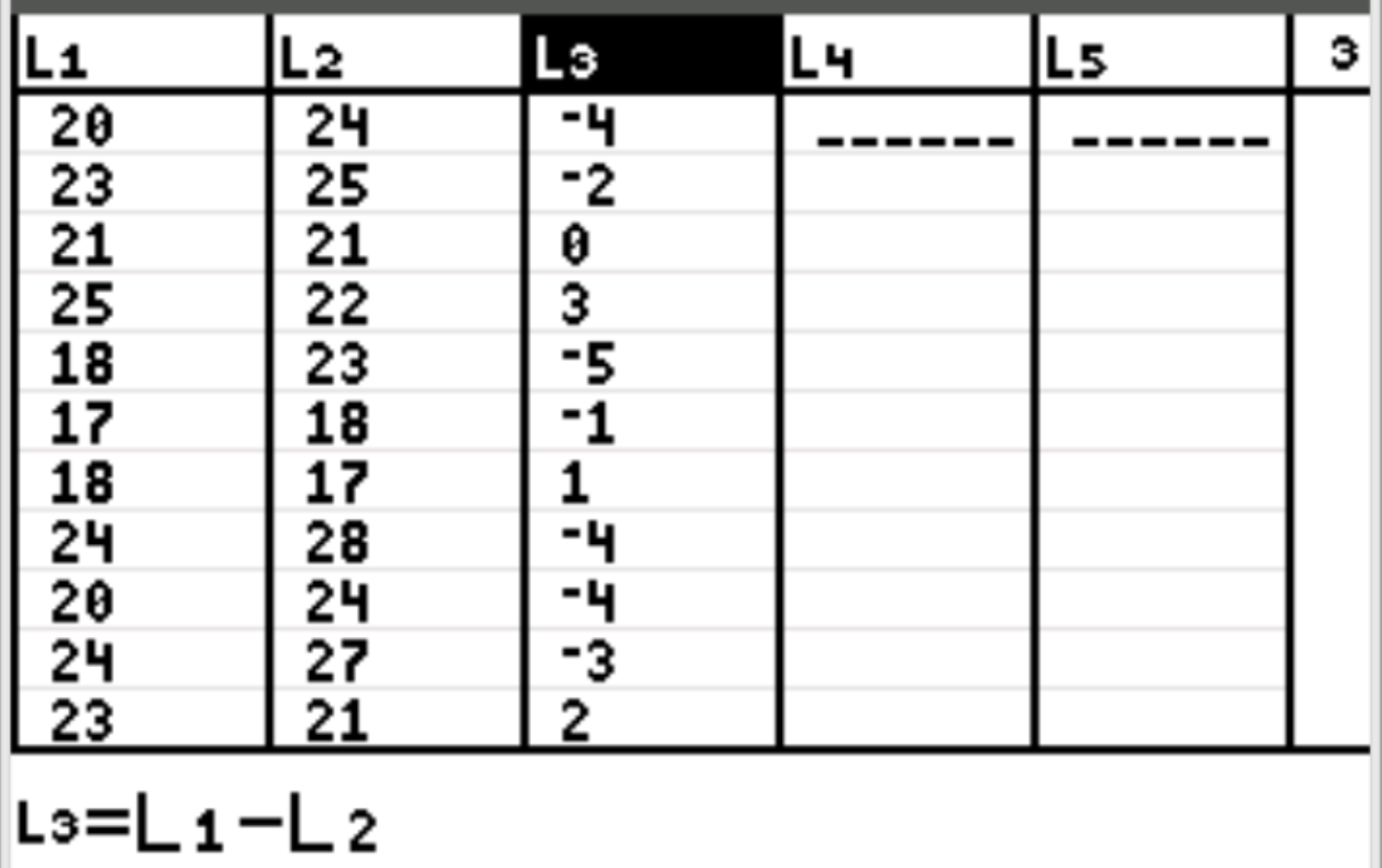
Stap 1: Voer de gegevens in.
Eerst zullen we de gegevenswaarden voor beide monsters invoeren. Druk op Stat en vervolgens op BEWERKEN . Vul in kolom L1 de volgende waarden in voor de controlegroep (geen brandstofbehandeling) en in kolom L2 de waarden voor de behandelgroepvariabele (ontvangen brandstofbehandeling), gevolgd door het verschil tussen deze twee waarden in de kolom L3.
Opmerking: markeer bovenaan de derde kolom L3. Druk vervolgens op 2nd en 1 om L1 te creëren, gevolgd door een minteken, en druk vervolgens op 2nd en 2 om L2 te creëren. Druk vervolgens op Enter . Elk van de waarden in kolom L3 wordt automatisch ingevuld met de formule L1-L2.
Stap 2: Voer de gepaarde t-test uit.
Om de gepaarde t-test uit te voeren, voeren we eenvoudigweg een t-test uit op kolom L3, die de gepaarde verschilwaarden bevat.
Tik op Stat . Scroll naar beneden naar TESTEN . Blader naar 2:T-Test en druk op ENTER .
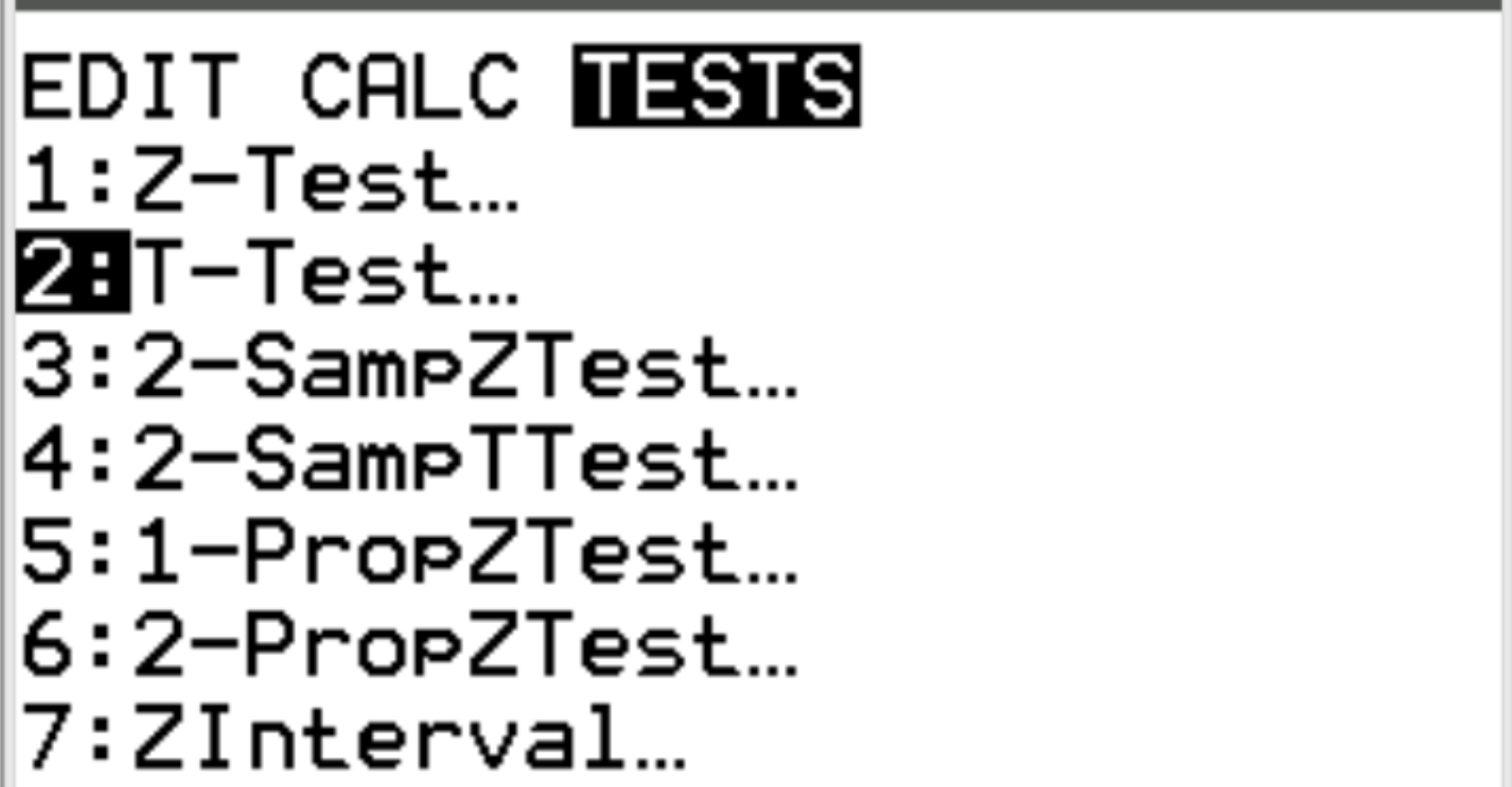
De rekenmachine vraagt om de volgende informatie:
- Invoer: Kies of u met ruwe gegevens (Data) of samenvattende statistieken (Stats) werkt. In dit geval zullen we Data markeren en op ENTER drukken.
- μ 0 : het gemiddelde verschil dat in de nulhypothese moet worden gebruikt. We typen 0 en drukken op ENTER .
- Lijst: de lijst met de verschillen tussen de twee monsters. We typen L3 en drukken op ENTER . Opmerking: Om L3 te laten verschijnen, drukt u op 2 en vervolgens op 3 .
- Freq: De frequentie. Laat deze set op 1 staan.
- μ : De alternatieve hypothese die moet worden gebruikt. Omdat we een tweezijdige test uitvoeren, zullen we ≠ μ 0 markeren en op ENTER drukken. Dit geeft aan dat onze alternatieve hypothese μ≠0 is. De andere twee opties zouden worden gebruikt voor linkertests (<μ 0 ) en rechtertests (>μ 0 ).
Markeer ten slotte Bereken en druk op ENTER .

Stap 3: Interpreteer de resultaten.
Onze rekenmachine produceert automatisch de resultaten van de one-sample t-test:

Zo interpreteert u de resultaten:
- μ≠0 : Dit is de alternatieve hypothese van de test.
- t=-1,8751 : Dit is de t-teststatistiek.
- p=0,0903 : Dit is de p-waarde die overeenkomt met de teststatistiek.
- x =-1,5455 . Dit is het gemiddelde verschil met groep 1 – groep 2.
- s x = 2,7336 . Dit is de standaarddeviatie van de verschillen.
- n=11 : Dit is het totale aantal gepaarde monsters.
Omdat de p-waarde van de test (0,0903) niet kleiner is dan 0,05, slagen we er niet in de nulhypothese te verwerpen.
Dit betekent dat we niet genoeg bewijs hebben om te zeggen dat er een verschil is tussen de gemiddelde mpg van de twee groepen. Simpel gezegd: we hebben niet genoeg bewijs om te zeggen dat brandstofbehandeling de mpg beïnvloedt.
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder