Hoe de gewogen standaarddeviatie in r te berekenen
Gewogen standaarddeviatie is een handige manier om de spreiding van waarden in een dataset te meten wanneer sommige waarden in de dataset een hoger gewicht hebben dan andere.
De formule voor het berekenen van een gewogen standaardafwijking is:
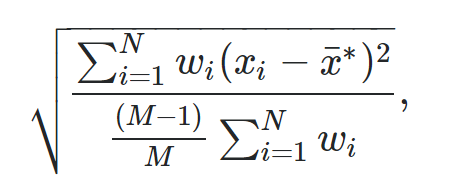
Goud:
- N: Het totale aantal waarnemingen
- M: Het aantal niet-nulgewichten
- w i : Een gewichtsvector
- x i : Een vector van gegevenswaarden
- x : Het gewogen gemiddelde
De eenvoudigste manier om een gewogen standaardafwijking in R te berekenen is door de functie wt.var() uit het Hmisc- pakket te gebruiken, die de volgende syntaxis gebruikt:
#define data values x <- c(4, 7, 12, 13, ...) #define weights wt <- c(.5, 1, 2, 2, ...) #calculate weighted variance weighted_var <- wtd. var (x, wt) #calculate weighted standard deviation weighted_sd <- sqrt(weighted_var)
De volgende voorbeelden laten zien hoe u deze functie in de praktijk kunt gebruiken.
Voorbeeld 1: Gewogen standaardafwijking voor een vector
De volgende code laat zien hoe u de gewogen standaardafwijking voor een enkele vector in R kunt berekenen:
library (Hmisc) #define data values x <- c(14, 19, 22, 25, 29, 31, 31, 38, 40, 41) #define weights wt <- c(1, 1, 1.5, 2, 2, 1.5, 1, 2, 3, 2) #calculate weighted variance weighted_var <- wtd. var (x, wt) #calculate weighted standard deviation sqrt(weighted_var) [1] 8.570051
De gewogen standaarddeviatie blijkt 8,57 te zijn.
Voorbeeld 2: Gewogen standaardafwijking voor een kolom in het dataframe
De volgende code laat zien hoe u de gewogen standaardafwijking voor een kolom van een gegevensframe in R kunt berekenen:
library (Hmisc) #define data frame df <- data. frame (team=c('A', 'A', 'A', 'A', 'A', 'B', 'B', 'C'), wins=c(2, 9, 11, 12, 15, 17, 18, 19), dots=c(1, 2, 2, 2, 3, 3, 3, 3)) #define weights wt <- c(1, 1, 1.5, 2, 2, 1.5, 1, 2) #calculate weighted standard deviation of points sqrt(wtd. var (df$points, wt)) [1] 0.6727938
De gewogen standaarddeviatie voor de puntenkolom blijkt 0,673 te zijn.
Voorbeeld 3: Gewogen standaardafwijking voor meerdere kolommen in een dataframe
De volgende code laat zien hoe u de functie sapply() in R gebruikt om de gewogen standaardafwijking voor meerdere kolommen in een gegevensframe te berekenen:
library (Hmisc) #define data frame df <- data. frame (team=c('A', 'A', 'A', 'A', 'A', 'B', 'B', 'C'), wins=c(2, 9, 11, 12, 15, 17, 18, 19), dots=c(1, 2, 2, 2, 3, 3, 3, 3)) #define weights wt <- c(1, 1, 1.5, 2, 2, 1.5, 1, 2) #calculate weighted standard deviation of points and wins sapply(df[c(' wins ', ' points ')], function(x) sqrt(wtd. var (x, wt))) win points 4.9535723 0.6727938
De gewogen standaardafwijking voor de overwinningskolom is 4,954 en de gewogen standaardafwijking voor de puntenkolom is 0,673 .
Aanvullende bronnen
Hoe u de gewogen standaarddeviatie in Excel kunt berekenen
Hoe de standaardafwijking in R te berekenen
Hoe de variatiecoëfficiënt van R te berekenen
Hoe bereik in R te berekenen
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder