Een eenvoudige introductie tot het stimuleren van machine learning
De meeste machine learning-algoritmen onder toezicht zijn gebaseerd op het gebruik van één enkel voorspellend model, zoals lineaire regressie , logistische regressie , nokregressie , enz.
Met methoden zoals bagging en willekeurige forests worden echter veel verschillende modellen gebouwd op basis van herhaalde, bootstrapped samples van de oorspronkelijke dataset. Voorspellingen op basis van nieuwe gegevens worden gedaan door het gemiddelde te nemen van de voorspellingen van de afzonderlijke modellen.
Deze methoden bieden doorgaans een verbetering in de nauwkeurigheid van de voorspelling ten opzichte van methoden die slechts één voorspellend model gebruiken, omdat ze het volgende proces gebruiken:
- Bouw eerst individuele modellen met een hoge variantie en weinig bias (bijvoorbeeld diepgegroeide beslissingsbomen ).
- Bereken vervolgens het gemiddelde van de voorspellingen van de afzonderlijke modellen om de variantie te verkleinen.
Een andere methode die de neiging heeft om een nog grotere verbetering in de voorspellende nauwkeurigheid te bieden, staat bekend als boosting .
Wat is boosten?
Boosting is een methode die bij elk type model kan worden gebruikt, maar wordt het vaakst gebruikt bij beslisbomen.
Het idee achter boosten is simpel:
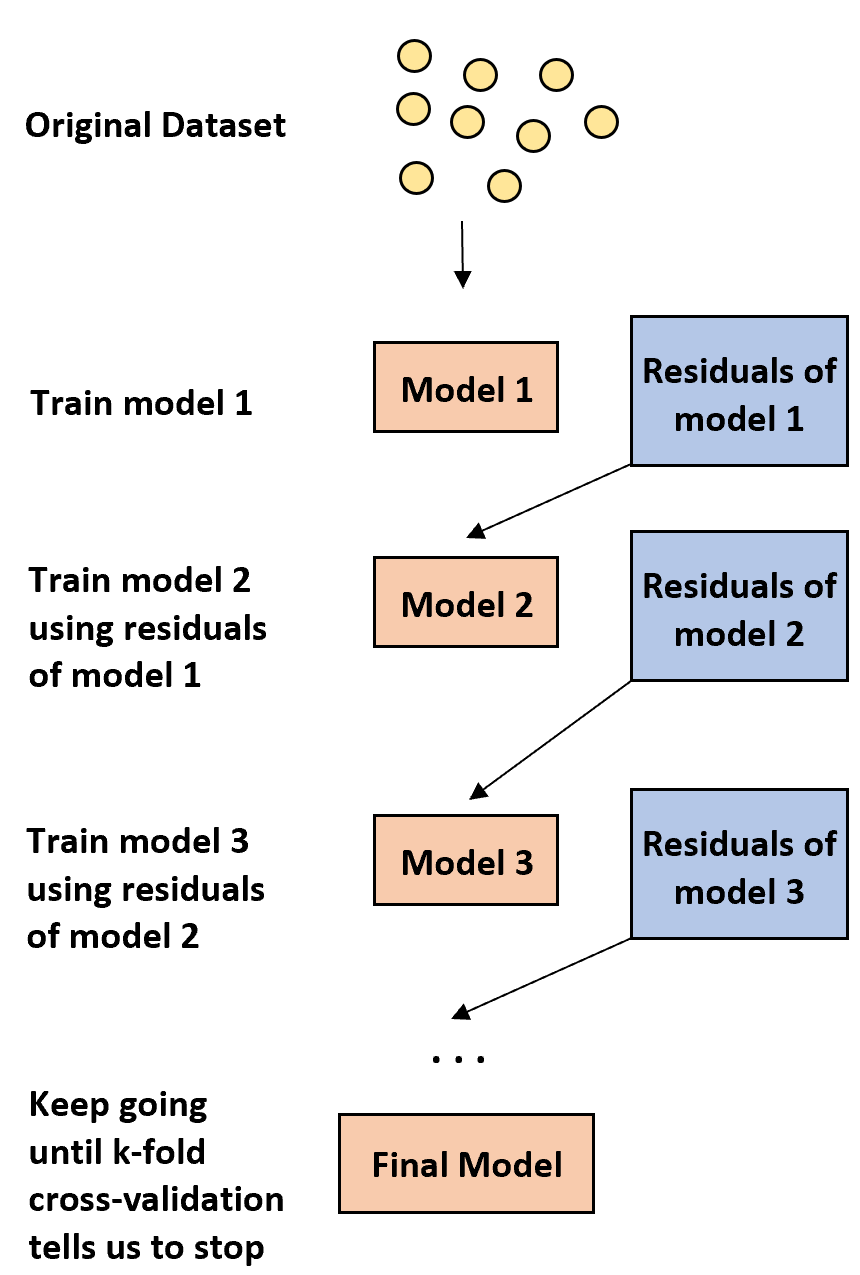
1. Bouw eerst een zwak model.
- Een ‘zwak’ model is een model waarvan het foutenpercentage slechts iets beter is dan een willekeurige schatting.
- In de praktijk is dit meestal een beslisboom met slechts één of twee divisies.
2. Bouw vervolgens nog een zwak model op basis van de residuen uit het vorige model.
- In de praktijk gebruiken we de residuen van het vorige model (dwz de fouten in onze voorspellingen) om een nieuw model in te passen dat het algehele foutenpercentage enigszins verbetert.
3. Ga door met dit proces totdat de k-voudige kruisvalidatie aangeeft dat we moeten stoppen.
- In de praktijk gebruiken we k-voudige kruisvalidatie om te bepalen wanneer we moeten stoppen met het ontwikkelen van het versterkte model.
Met behulp van deze methode kunnen we beginnen met een zwak model en de prestaties ervan blijven „verbeteren“ door opeenvolgend nieuwe bomen te bouwen die de prestaties van de vorige boom verbeteren, totdat we een definitief model verkrijgen met een hoge voorspellende nauwkeurigheid.
Waarom werkt boosten?
Het blijkt dat boosting enkele van de krachtigste modellen op het gebied van machinaal leren kan opleveren.
In veel industrieën worden versterkte modellen gebruikt als referentiemodellen in de productie, omdat ze de neiging hebben beter te presteren dan alle andere modellen.
De reden waarom versterkte sjablonen zo goed werken, komt neer op het begrijpen van een eenvoudig idee:
1. Ten eerste construeren de verbeterde modellen een zwakke beslissingsboom met een lage voorspellende nauwkeurigheid. Er wordt gezegd dat deze beslissingsboom een lage variantie en een hoge bias heeft.
2. Omdat de verbeterde modellen het opeenvolgende verbeteringsproces van eerdere beslissingsbomen volgen, kan het algehele model de vertekening bij elke stap langzaam verminderen zonder de variantie significant te vergroten.
3. Het uiteindelijk aangepaste model heeft doorgaans een voldoende lage bias en variantie, wat leidt tot een model dat in staat is lage testfoutenpercentages op nieuwe gegevens te produceren.
Voor- en nadelen van boosten
Het voor de hand liggende voordeel van boosting is dat het modellen kan produceren met een hoge voorspellende nauwkeurigheid in vergelijking met bijna alle andere typen modellen.
Een mogelijk nadeel is dat een aangepast verbeterd model zeer moeilijk te interpreteren is. Hoewel het een enorm vermogen kan bieden om responswaarden van nieuwe gegevens te voorspellen, is het moeilijk uit te leggen welk proces het precies gebruikt om dit te bereiken.
In de praktijk creëren de meeste datawetenschappers en beoefenaars van machine learning verbeterde modellen omdat ze de responswaarden van nieuwe data nauwkeurig willen kunnen voorspellen. Het feit dat verbeterde modellen moeilijk te interpreteren zijn, is dus over het algemeen geen probleem.
Booster in de praktijk
In de praktijk worden er veel soorten algoritmen gebruikt voor het stimuleren, waaronder:
Afhankelijk van de grootte van uw dataset en de verwerkingskracht van uw machine kan een van deze methoden de voorkeur verdienen boven de andere.
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder