Hoe hiërarchische regressie uit te voeren in stata
Hiërarchische regressie is een techniek die we kunnen gebruiken om verschillende lineaire modellen met elkaar te vergelijken.
Het basisidee is dat we eerst een lineair regressiemodel passen met één enkele verklarende variabele. Vervolgens passen we een ander regressiemodel aan met behulp van een extra verklarende variabele. Als de R-kwadraat (het deel van de variantie in de responsvariabele dat kan worden verklaard door de verklarende variabelen) in het tweede model aanzienlijk hoger is dan de R-kwadraat in het vorige model, betekent dit dat het tweede model beter is.
Vervolgens herhalen we het proces van het uitrusten van aanvullende regressiemodellen met meer verklarende variabelen en kijken we of de nieuwere modellen een verbetering bieden ten opzichte van de vorige modellen.
Deze tutorial geeft een voorbeeld van hoe u hiërarchische regressie uitvoert in Stata.
Voorbeeld: hiërarchische regressie in Stata
We zullen een ingebouwde dataset genaamd auto gebruiken om te illustreren hoe hiërarchische regressie in Stata kan worden uitgevoerd. Laad eerst de gegevensset door het volgende in het opdrachtvenster te typen:
automatisch gebruik van het systeem
We kunnen een snel overzicht van de gegevens krijgen met behulp van de volgende opdracht:
samenvatten
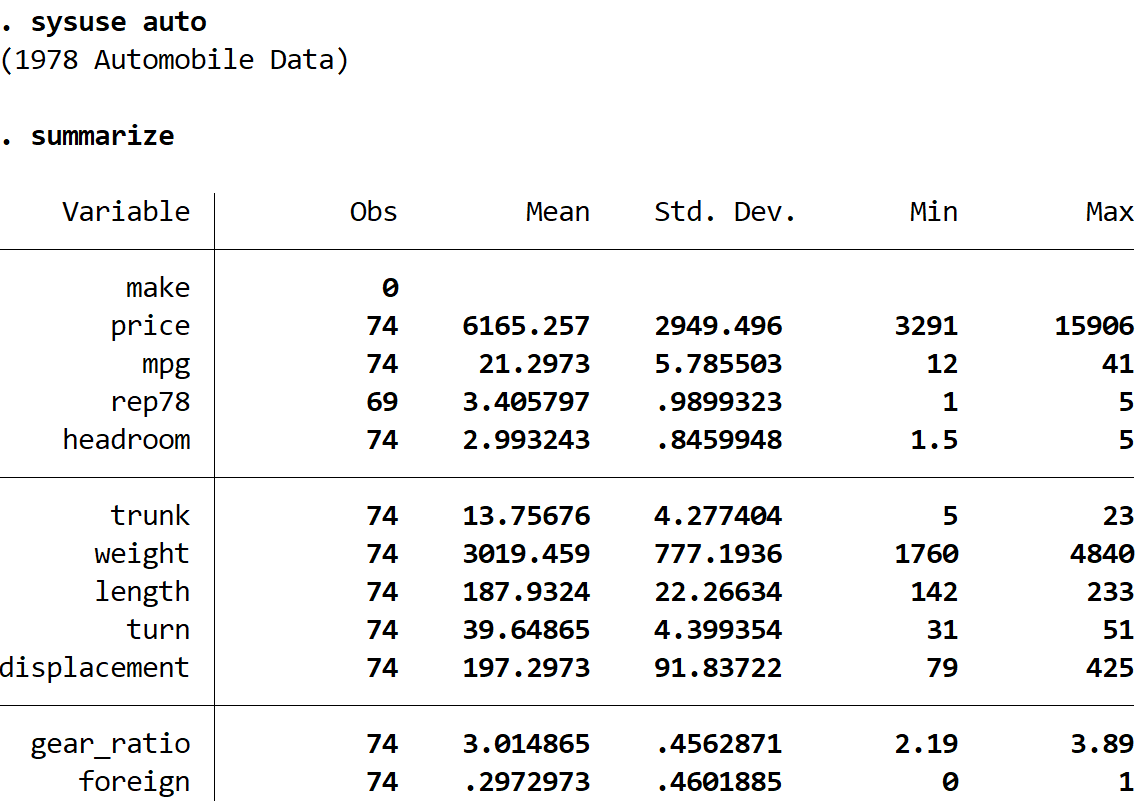
We kunnen zien dat de dataset informatie bevat over 12 verschillende variabelen voor in totaal 74 auto’s.
We zullen de volgende drie lineaire regressiemodellen passen en hiërarchische regressie gebruiken om te zien of elk volgend model al dan niet een significante verbetering oplevert ten opzichte van het vorige model:
Model 1: prijs = onderscheppen + mpg
Model 2: prijs = onderscheppen + mpg + gewicht
Model 3: prijs = onderscheppen + mpg + gewicht + overbrengingsverhouding
Om hiërarchische regressie in Stata uit te voeren, moeten we eerst het Hireg- pakket installeren. Om dit te doen, typt u het volgende in het opdrachtvak:
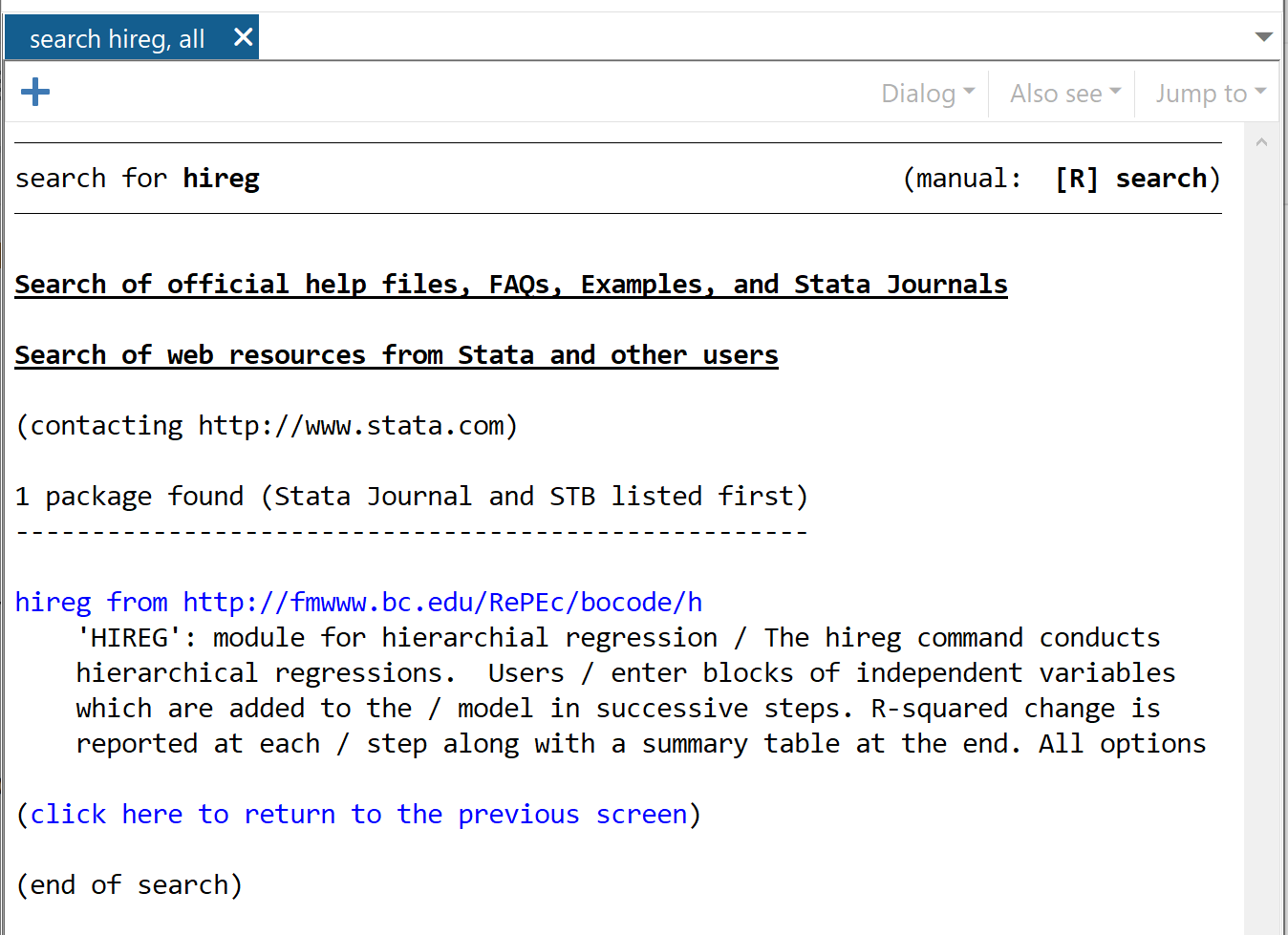
Vind Hireg
In het venster dat verschijnt, klikt u op Hireg van https://fmwww.bc.edu/RePEc/bocode/h
Klik in het volgende venster op de link Klik hier om te installeren .
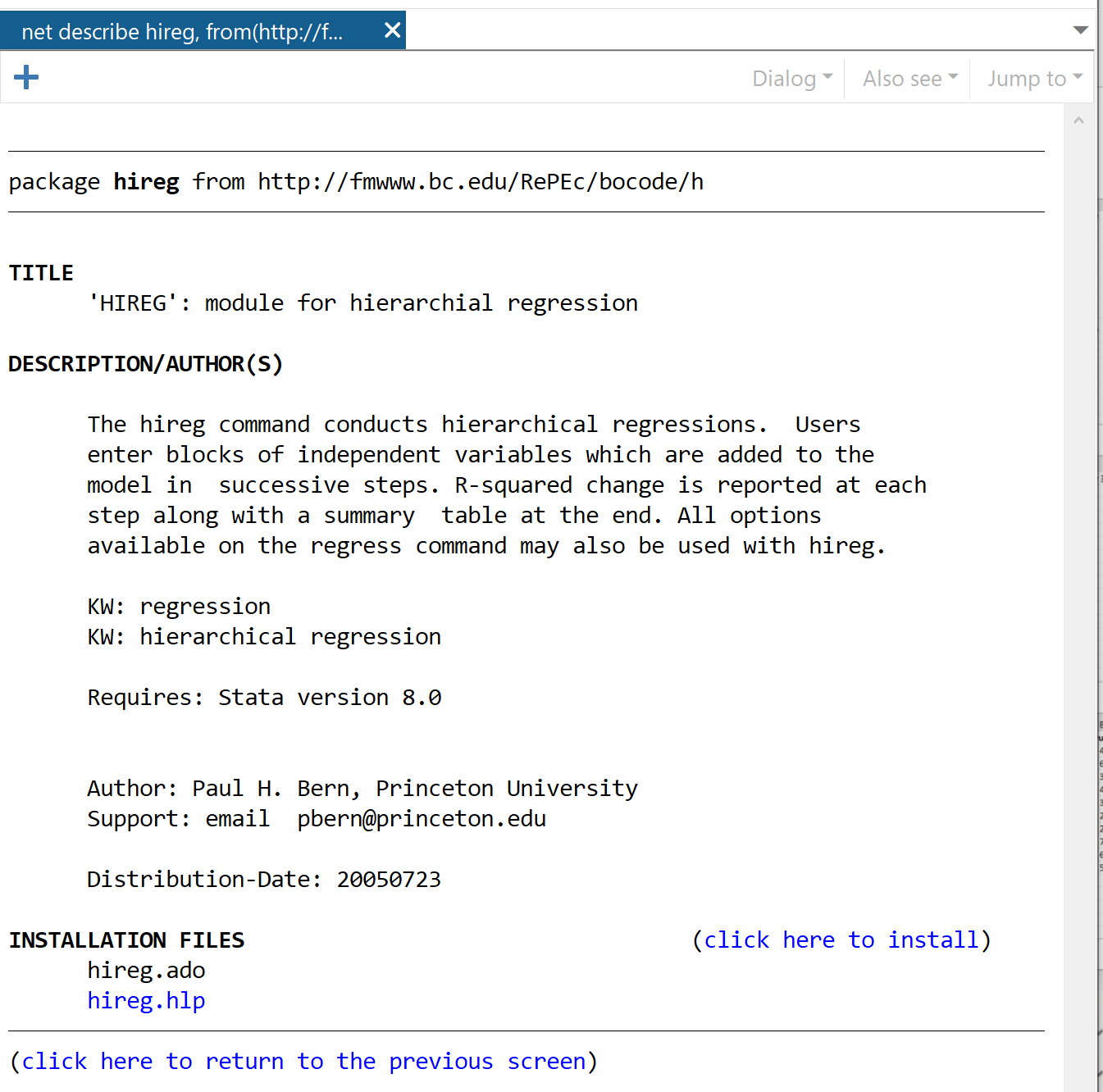
Het pakket wordt binnen enkele seconden geïnstalleerd. Om vervolgens een hiërarchische regressie uit te voeren, gebruiken we het volgende commando:
huurprijs (mpg) (gewicht) (gear_ratio)
Dit is wat Stata vraagt te doen:
- Voer een hiërarchische regressie uit met prijs als responsvariabele in elk model.
- Gebruik voor het eerste model mpg als verklarende variabele.
- Voor het tweede model voegt u gewicht toe als aanvullende verklarende variabele.
- Voeg voor het derde model gear_ratio toe als een andere verklarende variabele.
Hier is het resultaat van het eerste model:
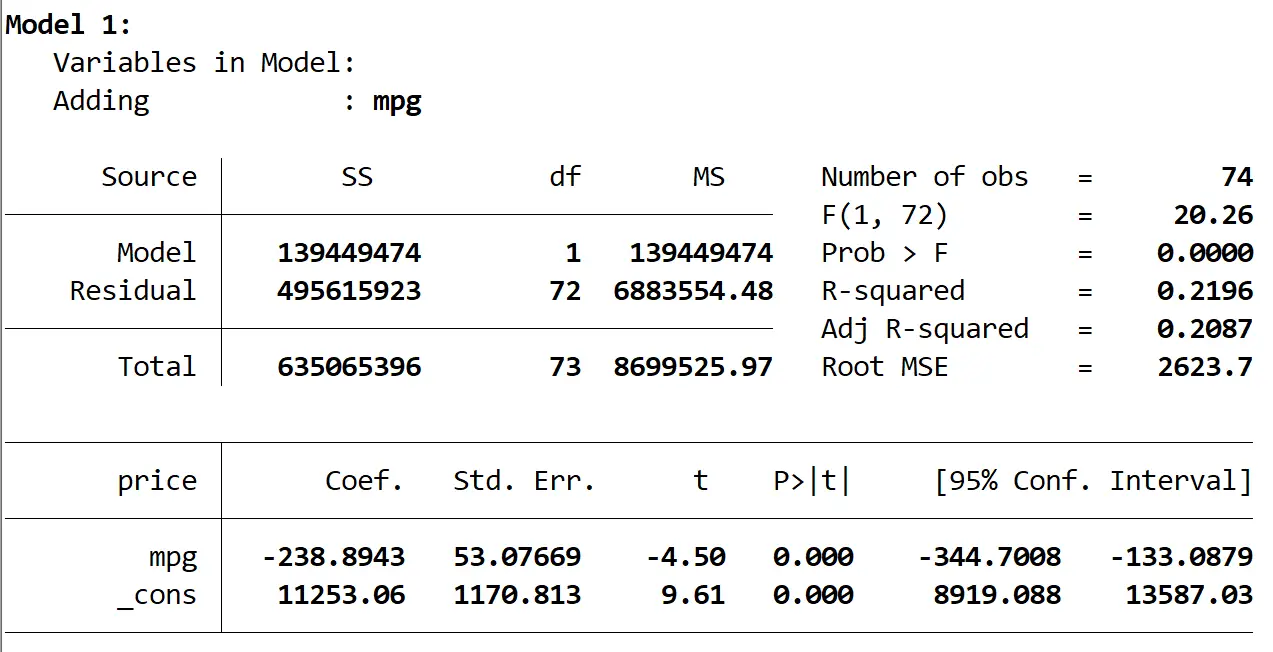
We zien dat de R-kwadraat van het model 0,2196 is en dat de totale p-waarde (Prob > F) van het model 0,0000 is, wat statistisch significant is bij α = 0,05.
Vervolgens zien we het resultaat van het tweede model:
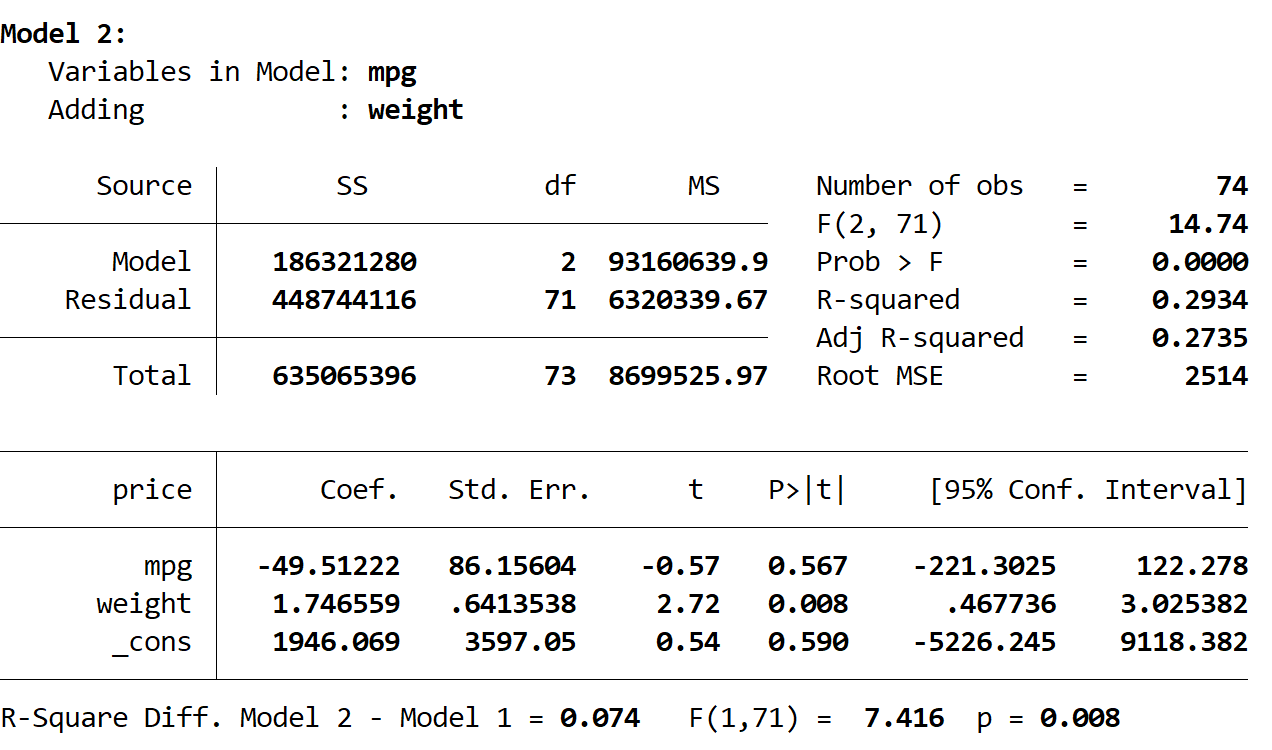
Het R-kwadraat van dit model is 0,2934 , wat groter is dan dat van het eerste model. Om te bepalen of dit verschil statistisch significant is, voerde Stata een F-test uit die onderaan het resultaat de volgende getallen opleverde:
- R-kwadraat verschil tussen de twee modellen = 0,074
- F-statistiek voor verschil = 7,416
- Overeenkomstige p-waarde van de F-statistiek = 0,008
Omdat de p-waarde kleiner is dan 0,05 concluderen we dat er een statistisch significante verbetering is in het tweede model vergeleken met het eerste model.
Ten slotte kunnen we het resultaat van het derde model zien:
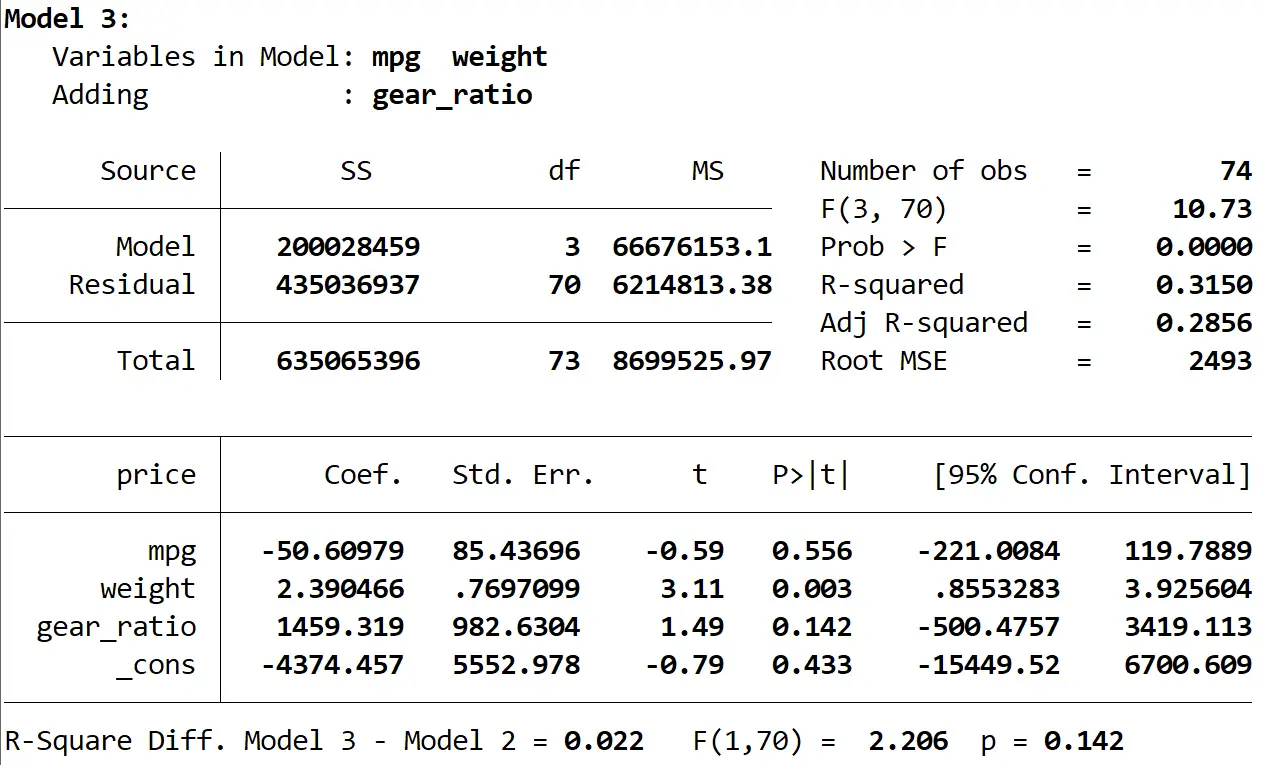
Het R-kwadraat van dit model is 0,3150 , wat groter is dan dat van het tweede model. Om te bepalen of dit verschil statistisch significant is, voerde Stata een F-test uit die onderaan het resultaat de volgende getallen opleverde:
- R-kwadraat verschil tussen de twee modellen = 0,022
- F-statistiek voor verschil = 2,206
- Overeenkomstige p-waarde van F-statistiek = 0,142
Omdat de p-waarde niet kleiner is dan 0,05, hebben we niet voldoende bewijs om te zeggen dat het derde model een verbetering oplevert ten opzichte van het tweede model.
Helemaal aan het einde van het resultaat kunnen we zien dat Stata een samenvatting van de resultaten geeft:

In dit specifieke voorbeeld zouden we concluderen dat Model 2 een significante verbetering ten opzichte van Model 1 bood, maar dat Model 3 geen significante verbetering ten opzichte van Model 2 bood.
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder