Hoe maak je een histogram van residuen in r
Een van de belangrijkste aannames van lineaire regressie is dat de residuen normaal verdeeld zijn.
Eén manier om deze aanname visueel te verifiëren, is door een histogram van de residuen te maken en te observeren of de verdeling al dan niet een „klokvorm“ volgt die doet denken aan de normale verdeling .
Deze zelfstudie biedt een stapsgewijs voorbeeld van hoe u een histogram van residuen maakt voor een regressiemodel in R.
Stap 1: Creëer de gegevens
Laten we eerst een aantal nepgegevens maken om mee te werken:
#make this example reproducible set.seed(0) #createdata x1 <- rnorm(n=100, 2, 1) x2 <- rnorm(100, 4, 3) y <- rnorm(100, 2, 3) data <- data.frame(x1, x2, y) #view first six rows of data head(data) x1 x2 y 1 3.262954 6.3455776 -1.1371530 2 1.673767 1.6696701 -0.6886338 3 3.329799 2.1520303 5.8081615 4 3.272429 4.1397409 3.7815228 5 2.414641 0.6088427 4.3269030 6 0.460050 5.7301563 6.6721111
Stap 2: Pas het regressiemodel aan
Vervolgens zullen we een meervoudig lineair regressiemodel op de gegevens passen:
#fit multiple linear regression model
model <- lm(y ~ x1 + x2, data=data)
Stap 3: Maak een histogram van residuen
Ten slotte zullen we het ggplot- visualisatiepakket gebruiken om een histogram van de modelresiduen te maken:
#load ggplot2
library (ggplot2)
#create histogram of residuals
ggplot(data = data, aes (x = model$residuals)) +
geom_histogram(fill = ' steelblue ', color = ' black ') +
labs(title = ' Histogram of Residuals ', x = ' Residuals ', y = ' Frequency ')
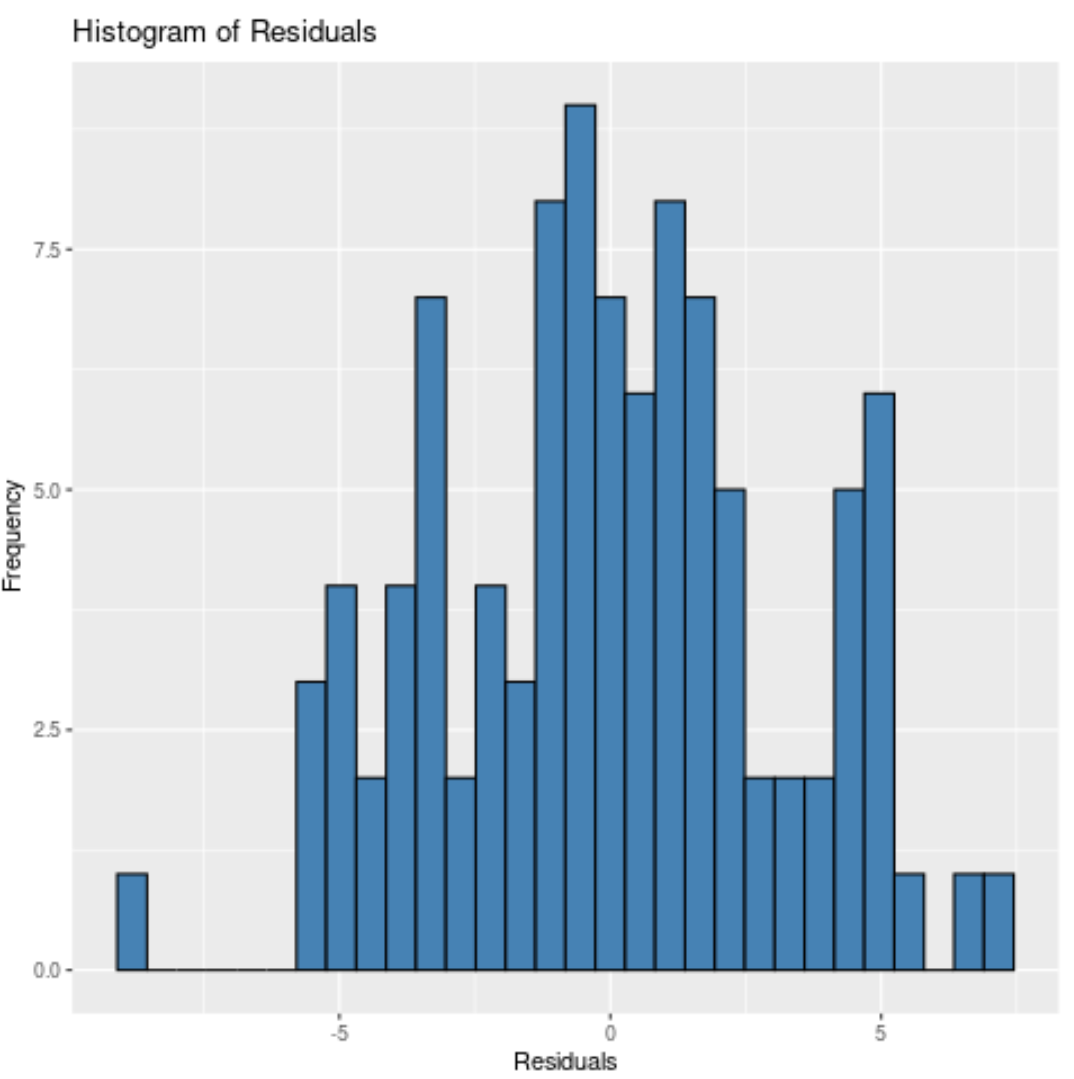
Merk op dat we ook het aantal bakken kunnen specificeren waarin de residuen moeten worden geplaatst met behulp van het bin- argument.
Hoe minder vakken er zijn, hoe breder de balken in het histogram zullen zijn. We kunnen bijvoorbeeld 20 bakken specificeren:
#create histogram of residuals
ggplot(data = data, aes (x = model$residuals)) +
geom_histogram(bins = 20 , fill = ' steelblue ', color = ' black ') +
labs(title = ' Histogram of Residuals ', x = ' Residuals ', y = ' Frequency ')
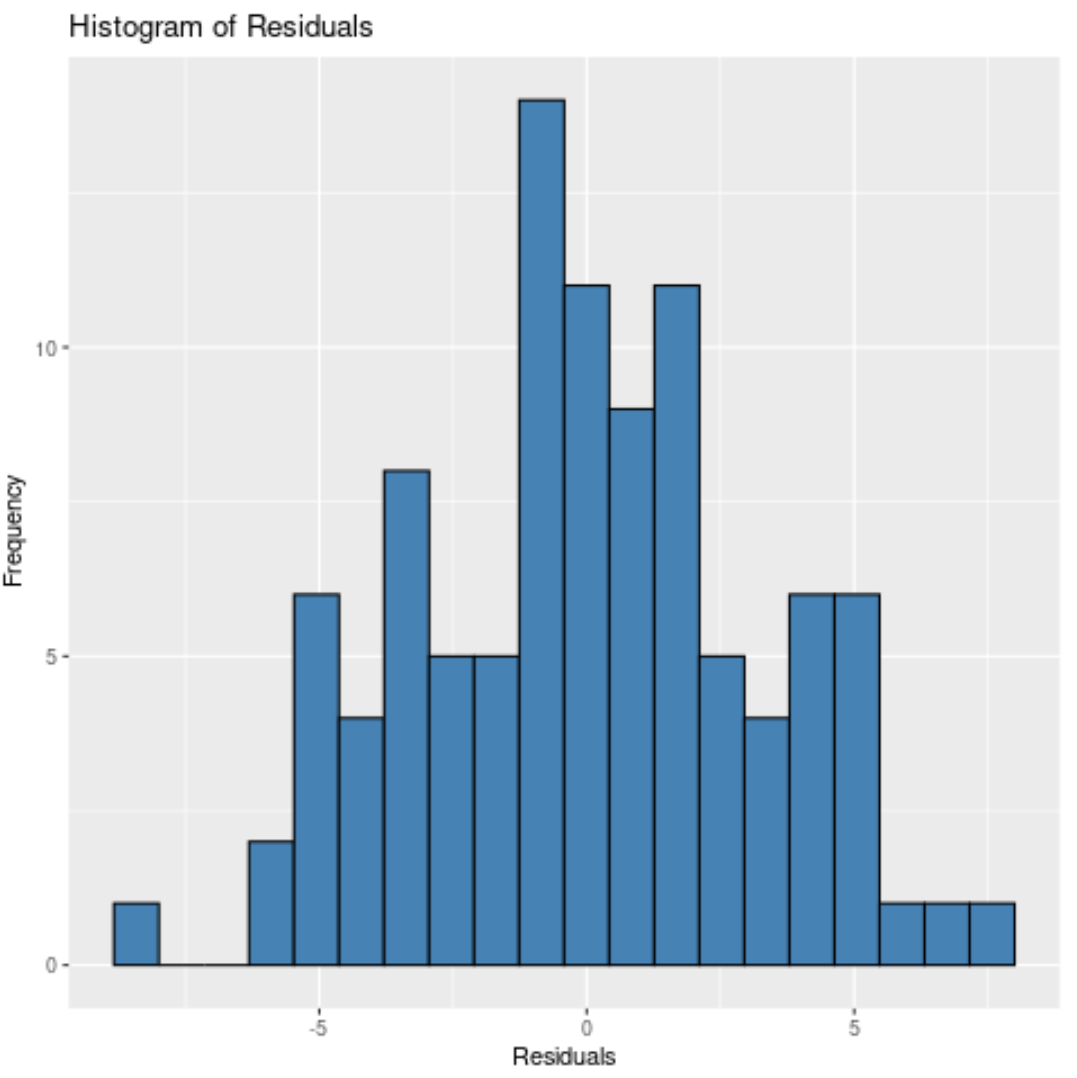
Of we kunnen 10 bakken specificeren:
#create histogram of residuals
ggplot(data = data, aes (x = model$residuals)) +
geom_histogram(bins = 10 , fill = ' steelblue ', color = ' black ') +
labs(title = ' Histogram of Residuals ', x = ' Residuals ', y = ' Frequency ')
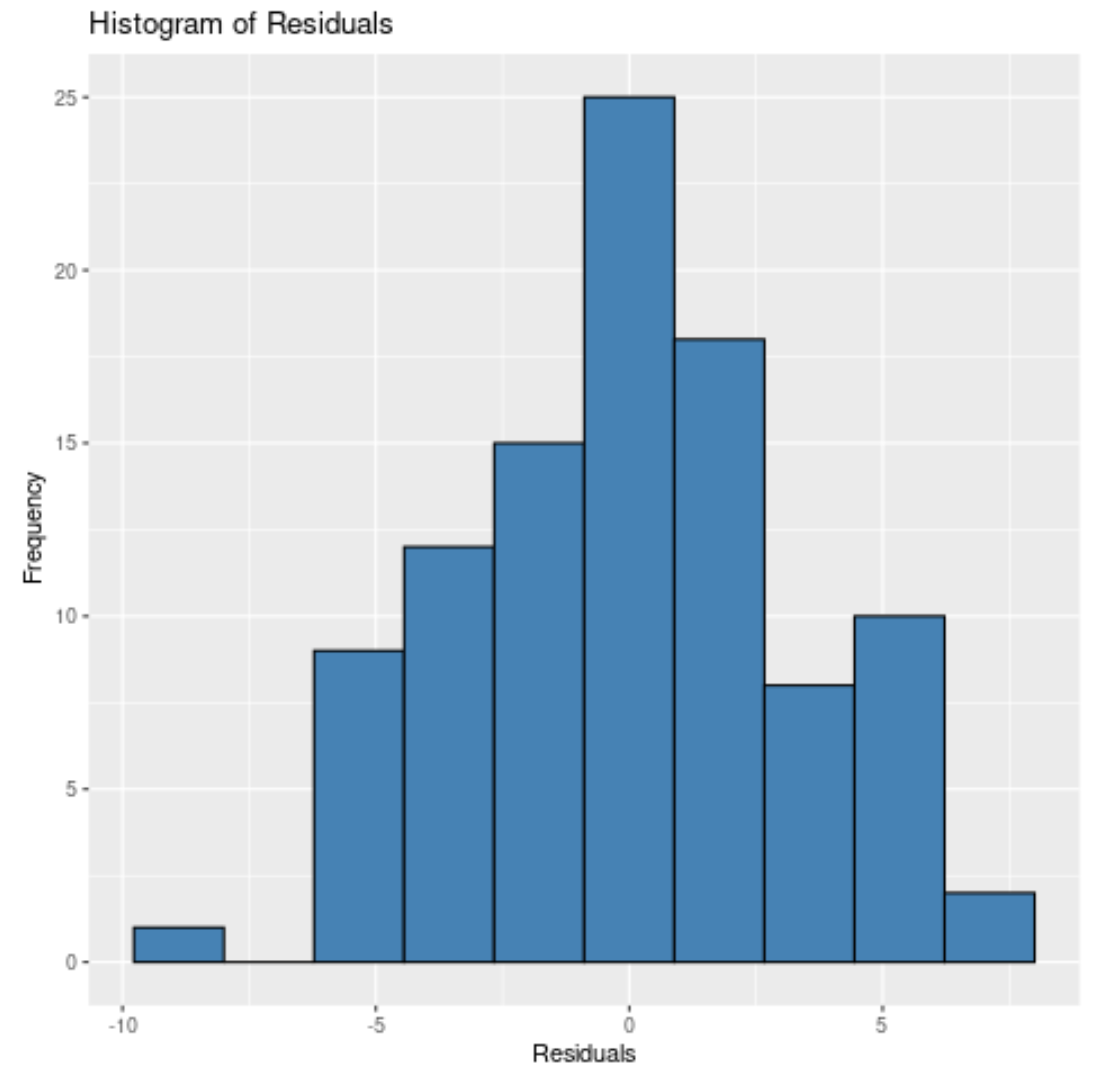
Ongeacht hoeveel dozen we specificeren, we kunnen zien dat de residuen ongeveer normaal verdeeld zijn.
We zouden ook een formele statistische test kunnen uitvoeren, zoals Shapiro-Wilk, Kolmogorov-Smirnov of Jarque-Bera, om te testen op normaliteit.
Houd er echter rekening mee dat deze tests gevoelig zijn voor grote steekproeven; dat wil zeggen dat ze vaak concluderen dat de residuen niet normaal zijn als de steekproefomvang groot is.
Om deze reden is het vaak gemakkelijker om de normaliteit te beoordelen door een histogram van de residuen te maken.
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder