Hoe het f-verdeelbord te lezen
In deze tutorial wordt uitgelegd hoe u de F-verdelingstabel leest en interpreteert.
Wat is de F-verdelingstabel?
De F-verdelingstabel is een tabel die de kritische waarden van de F-verdeling weergeeft. Om de F-verdelingstabel te gebruiken, hebt u slechts drie waarden nodig:
- De vrijheidsgraden van de teller
- De vrijheidsgraden van de noemer
- Het alfaniveau (veel voorkomende keuzes zijn 0,01, 0,05 en 0,10)
De volgende tabel toont de F-verdelingstabel voor alfa = 0,10. De getallen bovenaan de tabel vertegenwoordigen de vrijheidsgraden van de teller (aangeduid met DF1 in de tabel) en de getallen aan de linkerkant van de tabel vertegenwoordigen de vrijheidsgraden van de noemer (aangeduid met DF2 in de tabel).
Klik gerust op de tafel om in te zoomen.
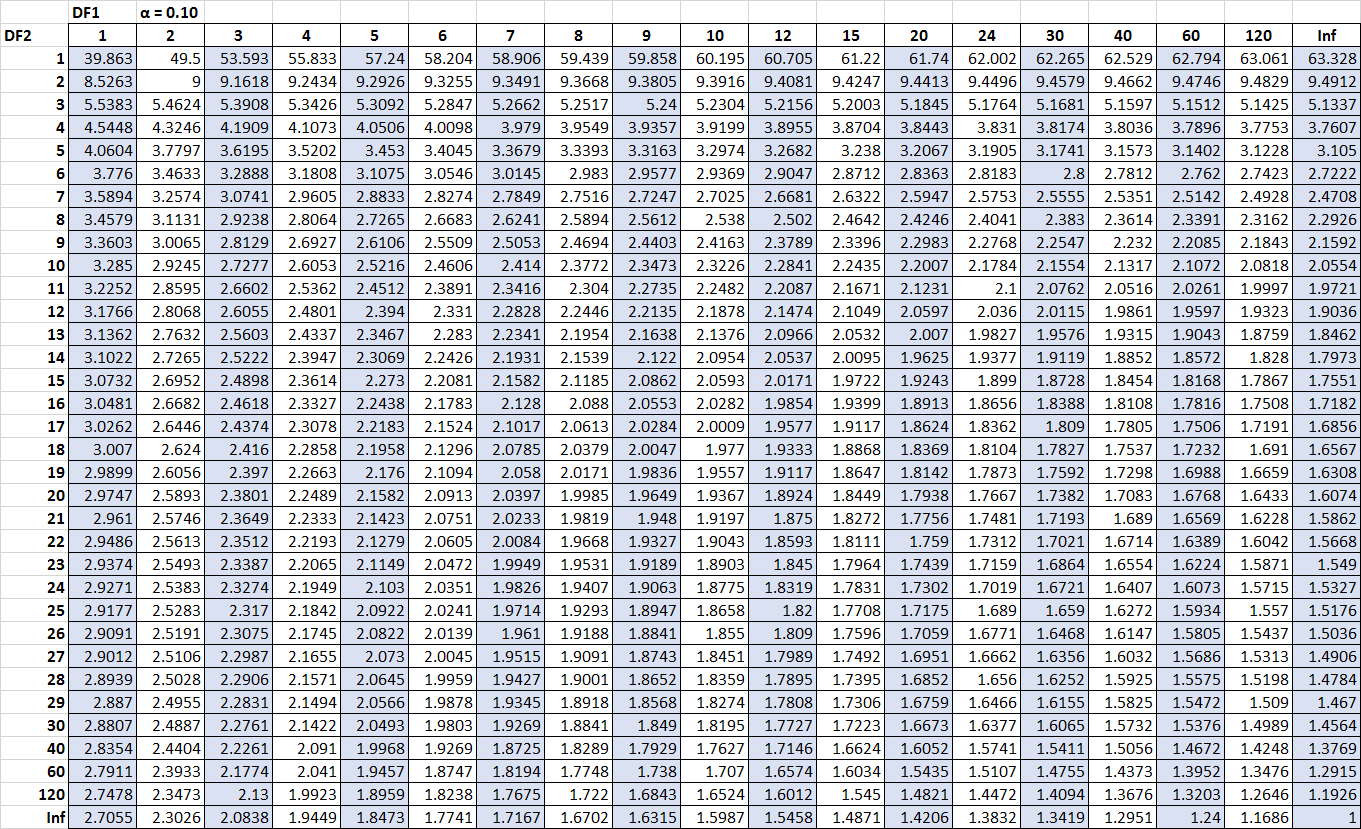
De kritische waarden in de tabel worden vaak vergeleken met de F-statistiek van een F-toets. Als de F-statistiek groter is dan de kritische waarde in de tabel, kunt u de nulhypothese van de F-toets verwerpen en concluderen dat de resultaten van de toets statistisch significant zijn.
Voorbeelden van het gebruik van de F-verdelingstabel
De F-verdelingstabel wordt gebruikt om de kritische waarde voor een F-test te vinden. De drie meest voorkomende scenario’s waarin je een F-test gaat uitvoeren zijn:
- F-test bij regressieanalyse om de algehele betekenis van een regressiemodel te testen.
- F-test in ANOVA (variantieanalyse) om te testen op een algemeen verschil tussen groepsgemiddelden.
- F-test om erachter te komen of twee populaties gelijke varianties hebben.
Laten we een voorbeeld bekijken van het gebruik van de F-distributietabel in elk van deze scenario’s.
F-test in regressieanalyse
Stel dat we een meervoudige lineaire regressieanalyse uitvoeren met gestudeerde uren en voorbereidende examens als voorspellende variabelen en het eindexamencijfer als responsvariabele. Wanneer we de regressieanalyse uitvoeren, krijgen we het volgende resultaat:
| Bron | SS | df | MEVR. | F | P. |
|---|---|---|---|---|---|
| Regressie | 546,53 | 2 | 273,26 | 5.09 | 0,033 |
| Resterend | 483.13 | 9 | 53,68 | ||
| Totaal | 1029,66 | 11 |
Bij regressieanalyse wordt de f-statistiek berekend als regressie-MS/residuele MS. Deze statistiek geeft aan of het regressiemodel beter bij de gegevens past dan een model dat geen onafhankelijke variabelen bevat. In wezen wordt getest of het regressiemodel als geheel bruikbaar is.
In dit voorbeeld is de F-statistiek 273,26 / 53,68 = 5,09 .
Stel dat we willen weten of deze F-statistiek significant is op het alpha = 0,05-niveau. Met behulp van de F-verdelingstabel voor alpha = 0,05, met de teller vrijheidsgraden 2 ( df voor regressie) en de noemer vrijheidsgraden 9 ( df voor residu) , vinden we dat de kritische waarde F 4, 2565 is.
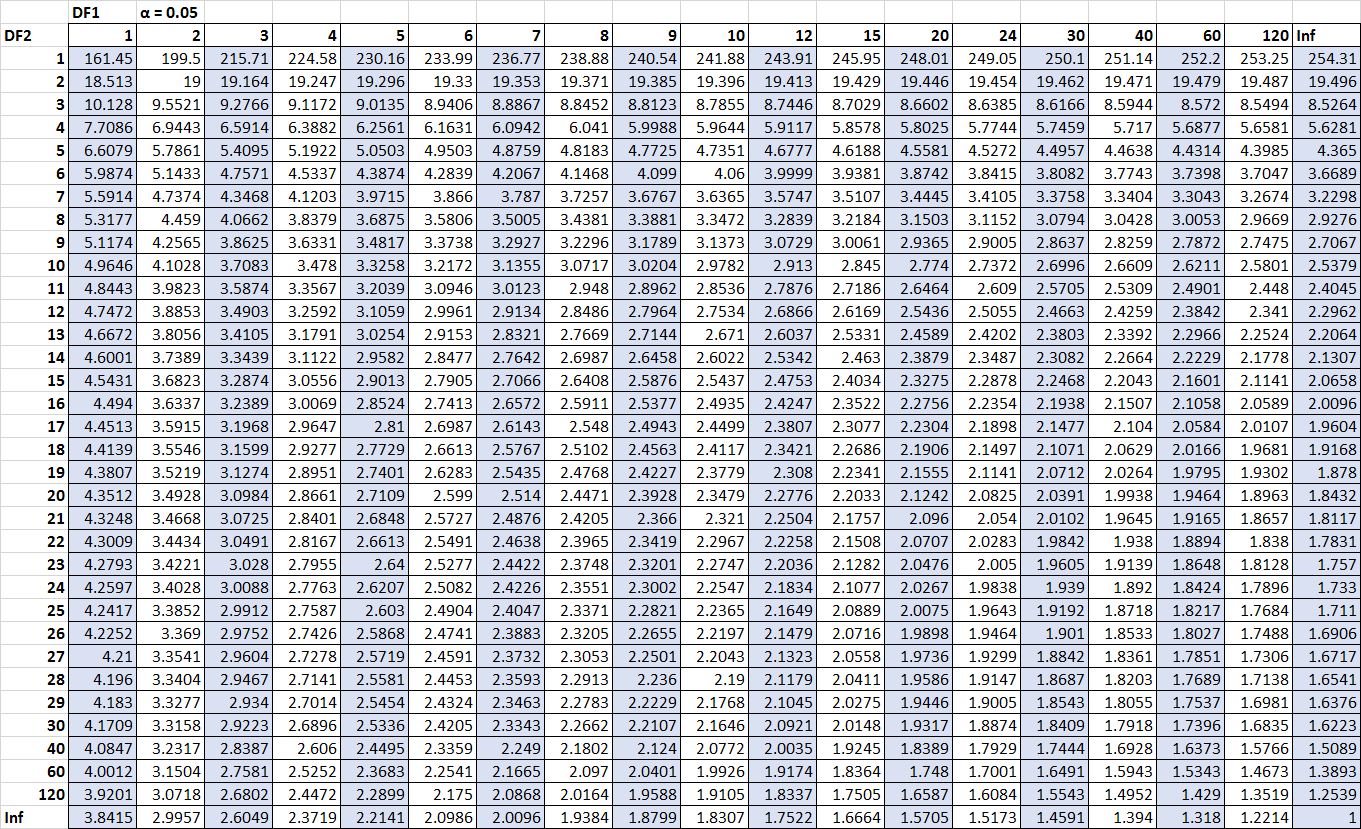
Omdat onze statistiek f( 5.09 ) groter is dan de kritische waarde F( 4.2565) kunnen we concluderen dat het regressiemodel als geheel statistisch significant is.
F-test in ANOVA
Stel dat we willen weten of drie verschillende onderzoekstechnieken tot verschillende toetsresultaten leiden. Om dit te testen werven we 60 studenten. We geven willekeurig twintig studenten de opdracht om een maand lang een van de drie studietechnieken te gebruiken ter voorbereiding op een examen. Nadat alle studenten het examen hebben afgelegd, voeren we een one-way ANOVA uit om te bepalen of de studietechniek al dan niet invloed heeft op de examenresultaten. De volgende tabel toont de resultaten van de eenrichtings-ANOVA:
| Bron | SS | df | MEVR. | F | P. |
|---|---|---|---|---|---|
| Behandeling | 58,8 | 2 | 29.4 | 1,74 | 0,217 |
| Fout | 202,8 | 12 | 16.9 | ||
| Totaal | 261,6 | 14 |
In een ANOVA wordt de f-statistiek berekend als behandelings-MS/fout-MS. Deze statistiek geeft aan of de gemiddelde score van de drie groepen gelijk is of niet.
In dit voorbeeld is de F-statistiek 29,4 / 16,9 = 1,74 .
Stel dat we willen weten of deze F-statistiek significant is op het alpha = 0,05-niveau. Met behulp van de F-verdelingstabel voor alpha = 0,05, met de teller vrijheidsgraden 2 ( df voor behandeling) en de noemer vrijheidsgraden 12 ( df voor fout) , vinden we dat de kritische waarde F 3, 8853 is.
Omdat onze f-statistiek ( 1,74 ) niet groter is dan de kritische waarde F ( 3,8853) , concluderen we dat er geen statistisch significant verschil is tussen de gemiddelde scores van de drie groepen.
F-test voor gelijke varianties van twee populaties
Stel dat we willen weten of de varianties van twee populaties gelijk zijn of niet. Om dit te testen kunnen we een F-test uitvoeren voor gelijke varianties, waarbij we een willekeurige steekproef van 25 waarnemingen uit elke populatie nemen en de steekproefvariantie voor elke steekproef bepalen.
De teststatistiek voor deze F-Test is als volgt gedefinieerd:
Statistieken F = s 1 2 / s 2 2
waarbij s 1 2 en s 2 2 de steekproefvarianties zijn. Hoe verder deze verhouding van één verwijderd is, hoe sterker het bewijs van ongelijke varianties binnen de populatie.
De kritische waarde van de F-test wordt als volgt gedefinieerd:
Kritische waarde F = waarde gevonden in de verdelingstabel F met n 1 -1 en n 2 -1 vrijheidsgraden en een significantieniveau van α.
Stel dat de steekproefvariantie voor steekproef 1 30,5 is en de steekproefvariantie voor steekproef 2 20,5. Dit betekent dat onze teststatistiek 30,5 / 20,5 = 1,487 is. Om erachter te komen of deze teststatistiek significant is bij alpha = 0,10, kunnen we de kritische waarde vinden in de F-verdelingstabel die hoort bij alpha = 0,10, teller df = 24 en noemer df = 24. Dit getal blijkt 1,7019 te zijn. .
Omdat onze statistiek f( 1.487 ) niet groter is dan de kritische waarde F( 1.7019) , concluderen we dat er geen statistisch significant verschil bestaat tussen de varianties van deze twee populaties.
Aanvullende bronnen
Zie deze pagina voor een complete set F-verdelingstabellen voor alfawaarden 0,001, 0,01, 0,025, 0,05 en 0,10.
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder