Regressie van hoofdcomponenten in python (stap voor stap)
Gegeven een reeks p- voorspellingsvariabelen en een responsvariabele, gebruikt meervoudige lineaire regressie een methode die bekend staat als de kleinste kwadraten om de resterende som van kwadraten (RSS) te minimaliseren:
RSS = Σ(y i – ŷ i ) 2
Goud:
- Σ : Een Grieks symbool dat som betekent
- y i : de werkelijke responswaarde voor de i-de waarneming
- ŷ i : De voorspelde responswaarde op basis van het meervoudige lineaire regressiemodel
Wanneer voorspellende variabelen echter sterk gecorreleerd zijn, kan multicollineariteit een probleem worden. Dit kan schattingen van modelcoëfficiënten onbetrouwbaar maken en een hoge variantie vertonen.
Eén manier om dit probleem te vermijden is het gebruik van regressie van hoofdcomponenten , waarbij M lineaire combinaties (zogenaamde „hoofdcomponenten“) van de oorspronkelijke p- voorspellers worden gevonden en vervolgens de kleinste kwadraten worden gebruikt om een lineair regressiemodel te passen met behulp van de hoofdcomponenten als voorspellers.
Deze zelfstudie biedt een stapsgewijs voorbeeld van hoe u regressie van hoofdcomponenten in Python kunt uitvoeren.
Stap 1: Importeer de benodigde pakketten
Eerst importeren we de pakketten die nodig zijn om hoofdcomponentenregressie (PCR) uit te voeren in Python:
import numpy as np
import pandas as pd
import matplotlib. pyplot as plt
from sklearn. preprocessing import scale
from sklearn import model_selection
from sklearn. model_selection import RepeatedKFold
from sklearn.model_selection import train_test_split
from sklearn. PCA import decomposition
from sklearn. linear_model import LinearRegression
from sklearn. metrics import mean_squared_error
Stap 2: Gegevens laden
Voor dit voorbeeld gebruiken we een dataset met de naam mtcars , die informatie bevat over 33 verschillende auto’s. We zullen hp gebruiken als de responsvariabele en de volgende variabelen als voorspellers:
- mpg
- weergave
- shit
- gewicht
- qsec
De volgende code laat zien hoe u deze gegevensset laadt en weergeeft:
#define URL where data is located
url = "https://raw.githubusercontent.com/Statorials/Python-Guides/main/mtcars.csv"
#read in data
data_full = pd. read_csv (url)
#select subset of data
data = data_full[["mpg", "disp", "drat", "wt", "qsec", "hp"]]
#view first six rows of data
data[0:6]
mpg disp drat wt qsec hp
0 21.0 160.0 3.90 2.620 16.46 110
1 21.0 160.0 3.90 2.875 17.02 110
2 22.8 108.0 3.85 2.320 18.61 93
3 21.4 258.0 3.08 3.215 19.44 110
4 18.7 360.0 3.15 3.440 17.02 175
5 18.1 225.0 2.76 3.460 20.22 105
Stap 3: Pas het PCR-model aan
De volgende code laat zien hoe u het PCR-model aan deze gegevens kunt aanpassen. Let op het volgende:
- pca.fit_transform(scale(X)) : Dit vertelt Python dat elk van de voorspellende variabelen moet worden geschaald om een gemiddelde van 0 en een standaarddeviatie van 1 te hebben. Dit zorgt ervoor dat geen enkele voorspellende variabele teveel invloed heeft in het model als dit gebeurt. in verschillende eenheden te meten.
- cv = RepeatedKFold() : Dit vertelt Python om k-voudige kruisvalidatie te gebruiken om de modelprestaties te evalueren. Voor dit voorbeeld kiezen we k = 10 vouwen, 3 keer herhaald.
#define predictor and response variables
X = data[["mpg", "disp", "drat", "wt", "qsec"]]
y = data[["hp"]]
#scale predictor variables
pca = pca()
X_reduced = pca. fit_transform ( scale (X))
#define cross validation method
cv = RepeatedKFold(n_splits= 10 , n_repeats= 3 , random_state= 1 )
regr = LinearRegression()
mse = []
# Calculate MSE with only the intercept
score = -1*model_selection. cross_val_score (regr,
n.p. ones ((len(X_reduced),1)), y, cv=cv,
scoring=' neg_mean_squared_error '). mean ()
mse. append (score)
# Calculate MSE using cross-validation, adding one component at a time
for i in np. arange (1, 6):
score = -1*model_selection. cross_val_score (regr,
X_reduced[:,:i], y, cv=cv, scoring=' neg_mean_squared_error '). mean ()
mse. append (score)
# Plot cross-validation results
plt. plot (mse)
plt. xlabel ('Number of Principal Components')
plt. ylabel ('MSE')
plt. title ('hp')
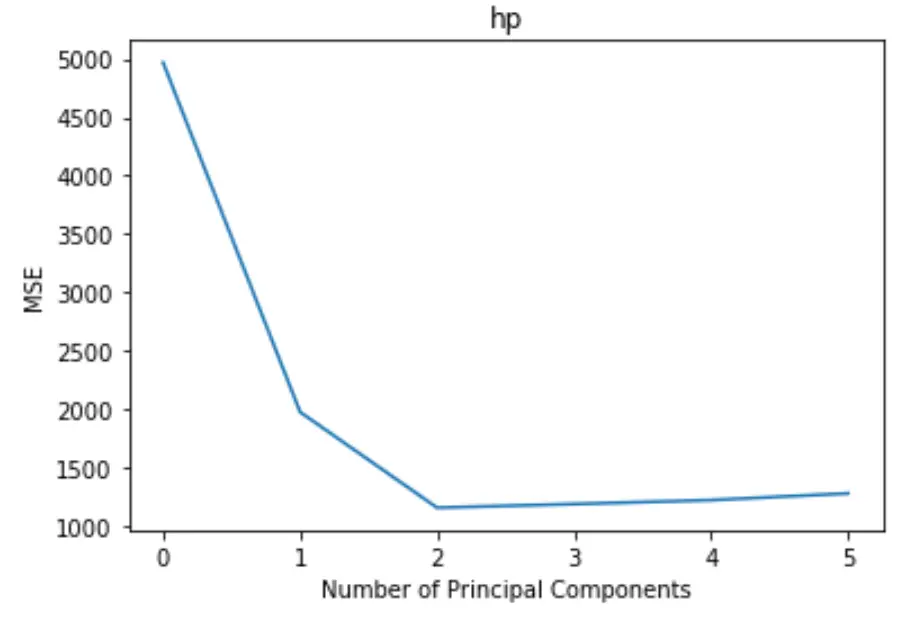
De plot toont het aantal hoofdcomponenten langs de x-as en de MSE-test (mean square error) langs de y-as.
Uit de grafiek kunnen we zien dat de MSE van de test afneemt als we twee hoofdcomponenten toevoegen, maar begint te stijgen als we meer dan twee hoofdcomponenten toevoegen.
Het optimale model omvat dus alleen de eerste twee hoofdcomponenten.
We kunnen ook de volgende code gebruiken om het variantiepercentage in de responsvariabele te berekenen, verklaard door elke hoofdcomponent aan het model toe te voegen:
n.p. cumsum (np. round (pca. explained_variance_ratio_ , decimals= 4 )* 100 )
array([69.83, 89.35, 95.88, 98.95, 99.99])
We kunnen het volgende zien:
- Met alleen de eerste hoofdcomponent kunnen we 69,83% van de variatie in de responsvariabele verklaren.
- Door de tweede hoofdcomponent toe te voegen, kunnen we 89,35% van de variatie in de responsvariabele verklaren.
Merk op dat we nog steeds meer variantie kunnen verklaren door meer hoofdcomponenten te gebruiken, maar we kunnen zien dat het toevoegen van meer dan twee hoofdcomponenten het percentage verklaarde variantie feitelijk niet veel verhoogt.
Stap 4: Gebruik het definitieve model om voorspellingen te doen
We kunnen het laatste PCR-model met twee hoofdcomponenten gebruiken om voorspellingen te doen over nieuwe waarnemingen.
De volgende code laat zien hoe u de oorspronkelijke gegevensset kunt opsplitsen in een trainings- en testset en hoe u het PCR-model met twee hoofdcomponenten kunt gebruiken om voorspellingen te doen over de testset.
#split the dataset into training (70%) and testing (30%) sets
X_train,X_test,y_train,y_test = train_test_split (X,y,test_size= 0.3 , random_state= 0 )
#scale the training and testing data
X_reduced_train = pca. fit_transform ( scale (X_train))
X_reduced_test = pca. transform ( scale (X_test))[:,:1]
#train PCR model on training data
regr = LinearRegression()
reg. fit (X_reduced_train[:,:1], y_train)
#calculate RMSE
pred = regr. predict (X_reduced_test)
n.p. sqrt ( mean_squared_error (y_test, pred))
40.2096
We zien dat de RMSE-test 40.2096 blijkt te zijn. Dit is de gemiddelde afwijking tussen de voorspelde pk- waarde en de waargenomen pk- waarde voor de waarnemingen van de testset.
De volledige Python-code die in dit voorbeeld wordt gebruikt, vindt u hier .
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder