One-hot-codering uitvoeren in python
One-hot-codering wordt gebruikt om categorische variabelen om te zetten in een indeling die gemakkelijk kan worden gebruikt door machine learning-algoritmen .
Het basisidee van one-hot coding is het creëren van nieuwe variabelen die de waarden 0 en 1 aannemen om de oorspronkelijke categorische waarden weer te geven.
De volgende afbeelding laat bijvoorbeeld zien hoe we one-hot-encoderen om een categorische variabele met teamnamen te converteren naar nieuwe variabelen die alleen 0- en 1-waarden bevatten:
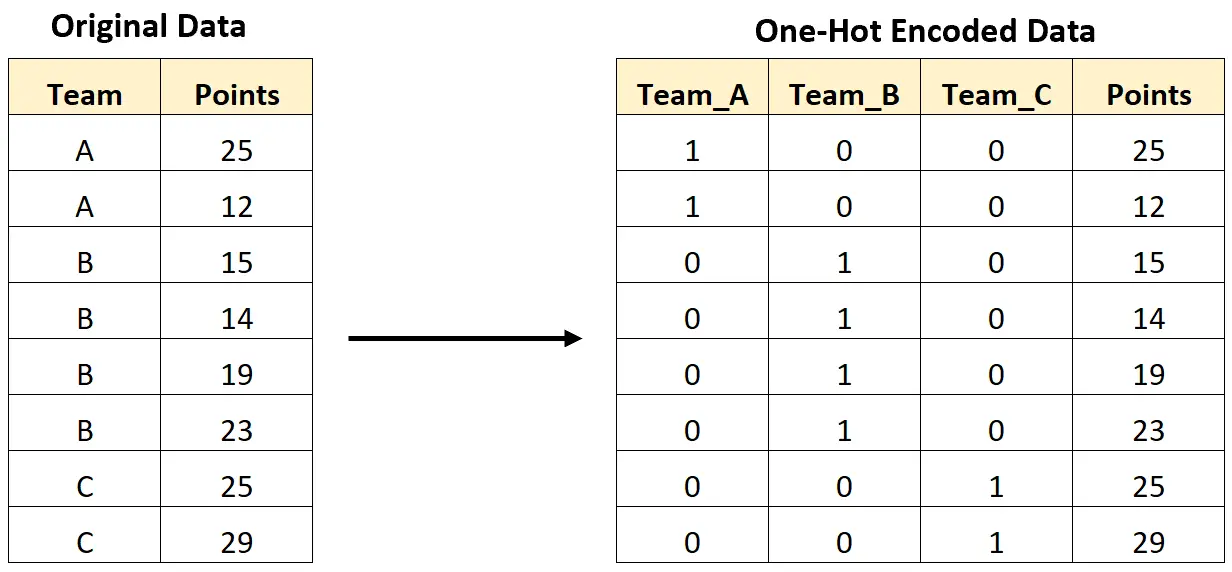
In het volgende stapsgewijze voorbeeld ziet u hoe u one-hot-codering kunt uitvoeren voor deze exacte gegevensset in Python.
Stap 1: Creëer de gegevens
Laten we eerst de volgende panda’s DataFrame maken:
import pandas as pd #createDataFrame df = pd. DataFrame ({' team ': ['A', 'A', 'B', 'B', 'B', 'B', 'C', 'C'], ' points ': [25, 12, 15, 14, 19, 23, 25, 29]}) #view DataFrame print (df) team points 0 to 25 1 to 12 2 B 15 3 B 14 4 B 19 5 B 23 6 C 25 7 C 29
Stap 2: Voer one-hot-codering uit
Laten we vervolgens de functie OneHotEncoder() importeren uit de sklearn- bibliotheek en deze gebruiken om hot-encoding uit te voeren op de ‚team‘-variabele in het pandas DataFrame:
from sklearn. preprocessing import OneHotEncoder #creating instance of one-hot-encoder encoder = OneHotEncoder(handle_unknown=' ignore ') #perform one-hot encoding on 'team' column encoder_df = pd. DataFrame ( encoder.fit_transform (df[[' team ']]). toarray ()) #merge one-hot encoded columns back with original DataFrame final_df = df. join (encoder_df) #view final df print (final_df) team points 0 1 2 0 to 25 1.0 0.0 0.0 1 to 12 1.0 0.0 0.0 2 B 15 0.0 1.0 0.0 3 B 14 0.0 1.0 0.0 4 B 19 0.0 1.0 0.0 5 B 23 0.0 1.0 0.0 6 C 25 0.0 0.0 1.0 7 C 29 0.0 0.0 1.0
Houd er rekening mee dat er drie nieuwe kolommen aan het DataFrame zijn toegevoegd, omdat de oorspronkelijke kolom ‚team‘ drie unieke waarden bevatte.
Opmerking : u kunt de volledige documentatie voor de OneHotEncoder()- functie hier vinden.
Stap 3: Verwijder de oorspronkelijke categorische variabele
Ten slotte kunnen we de originele ‚team‘-variabele uit het DataFrame verwijderen, omdat we deze niet langer nodig hebben:
#drop 'team' column final_df. drop (' team ', axis= 1 , inplace= True ) #view final df print (final_df) points 0 1 2 0 25 1.0 0.0 0.0 1 12 1.0 0.0 0.0 2 15 0.0 1.0 0.0 3 14 0.0 1.0 0.0 4 19 0.0 1.0 0.0 5 23 0.0 1.0 0.0 6 25 0.0 0.0 1.0 7 29 0.0 0.0 1.0
Gerelateerd: Kolommen verwijderen in Panda’s (4 methoden)
We kunnen ook de kolommen van het uiteindelijke DataFrame hernoemen om ze gemakkelijker leesbaar te maken:
#rename columns final_df. columns = ['points', 'teamA', 'teamB', 'teamC'] #view final df print (final_df) points teamA teamB teamC 0 25 1.0 0.0 0.0 1 12 1.0 0.0 0.0 2 15 0.0 1.0 0.0 3 14 0.0 1.0 0.0 4 19 0.0 1.0 0.0 5 23 0.0 1.0 0.0 6 25 0.0 0.0 1.0 7 29 0.0 0.0 1.0
De one-hot-codering is voltooid en we kunnen dit panda’s DataFrame nu in elk gewenst machine learning-algoritme invoegen.
Aanvullende bronnen
Hoe een getrimd gemiddelde in Python te berekenen
Hoe lineaire regressie uit te voeren in Python
Hoe logistieke regressie uit te voeren in Python
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder