Een complete gids voor de iris-dataset in r
De irisdataset is een geïntegreerde dataset in R die metingen bevat van 4 verschillende attributen (in centimeters) voor 50 bloemen van 3 verschillende soorten.
In deze zelfstudie wordt uitgelegd hoe u een gegevensset in R kunt verkennen en samenvatten, waarbij u de irisgegevensset als voorbeeld gebruikt.
Gerelateerd: een complete gids voor de mtcars-dataset in R
Iris-gegevensset laden
Omdat de iris-dataset een ingebouwde dataset in R is, kunnen we deze laden met de volgende opdracht:
data(iris)
We kunnen de eerste zes rijen van de dataset bekijken met behulp van de head() functie:
#view first six rows of iris dataset
head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
Vat de Iris-dataset samen
We kunnen de functie summary() gebruiken om elke variabele in de dataset snel samen te vatten:
#summarize iris dataset
summary(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width
Min. :4,300 Min. :2,000 Min. :1,000 Min. :0.100
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
Median: 5,800 Median: 3,000 Median: 4,350 Median: 1,300
Mean:5.843 Mean:3.057 Mean:3.758 Mean:1.199
3rd Qu.:6,400 3rd Qu.:3,300 3rd Qu.:5,100 3rd Qu.:1,800
Max. :7,900 Max. :4,400 Max. :6,900 Max. :2,500
Species
setosa:50
versicolor:50
virginica :50
Voor elk van de numerieke variabelen kunnen we de volgende informatie zien:
- Min : De minimumwaarde.
- 1e Qu : de waarde van het eerste kwartiel (25e percentiel).
- Mediaan : de mediaanwaarde.
- Gemiddelde : de gemiddelde waarde.
- 3e Qu : de waarde van het derde kwartiel (75e percentiel).
- Max : de maximale waarde.
Voor de enige categorische variabele in de dataset (Species) zien we een frequentietelling van elke waarde:
- setosa : Deze soort komt 50 keer voor.
- versicolor : Deze soort komt 50 keer voor.
- virginica : Deze soort komt 50 keer voor.
We kunnen de functie dim() gebruiken om de afmetingen van de dataset te verkrijgen in termen van het aantal rijen en kolommen:
#display rows and columns
dim(iris)
[1] 150 5
We kunnen zien dat de dataset 150 rijen en 5 kolommen heeft.
We kunnen ook de functie namen() gebruiken om de kolomnamen van het dataframe weer te geven:
#display column names
names(iris)
[1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"
Visualiseer de Iris-gegevensset
We kunnen ook plots maken om de waarden van de dataset te visualiseren.
We kunnen bijvoorbeeld de functie hist() gebruiken om een histogram te maken van de waarden van een bepaalde variabele:
#create histogram of values for sepal length
hist(iris$Sepal.Length,
col=' steelblue ',
main=' Histogram ',
xlab=' Length ',
ylab=' Frequency ')
We kunnen ook de functie plot() gebruiken om een spreidingsdiagram te maken van elke paarsgewijze combinatie van variabelen:
#create scatterplot of sepal width vs. sepal length
plot(iris$Sepal.Width, iris$Sepal.Length,
col=' steelblue ',
main=' Scatterplot ',
xlab=' Sepal Width ',
ylab=' Sepal Length ',
pch= 19 )
We kunnen ook de functie boxplot() gebruiken om een boxplot per groep te maken:
#create scatterplot of sepal width vs. sepal length
boxplot(Sepal.Length~Species,
data=iris,
main=' Sepal Length by Species ',
xlab=' Species ',
ylab=' Sepal Length ',
col=' steelblue ',
border=' black ')
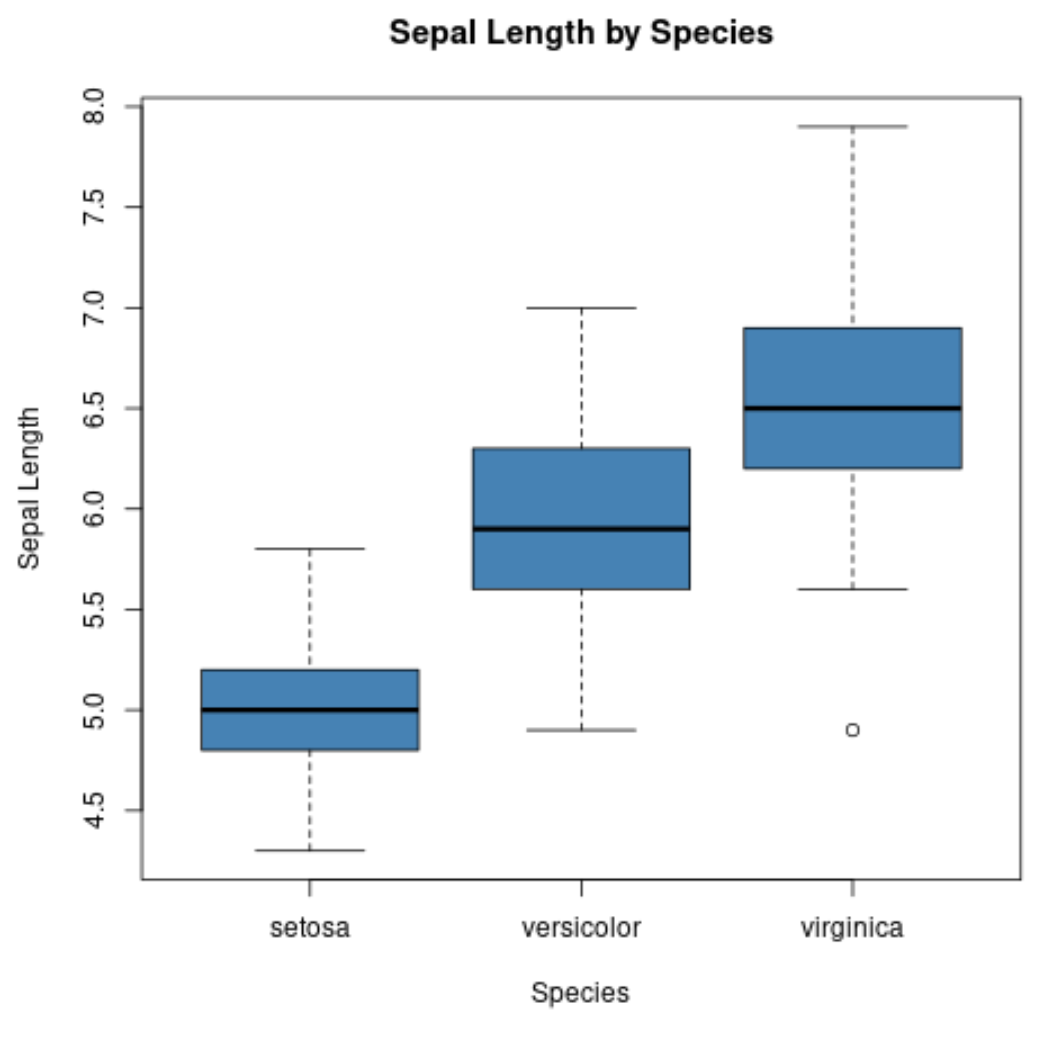
Op de x-as worden de drie soorten weergegeven en op de y-as wordt de verdeling van de kelkbladlengtewaarden voor elke soort weergegeven.
Met dit type plot kunnen we snel zien dat de lengte van de kelkblaadjes meestal het grootst is voor de virginica-soort en het kleinst voor de setosa-soort.
Aanvullende bronnen
In de volgende tutorials wordt gedetailleerder uitgelegd hoe u gegevenssets in R samenvat:
De eenvoudigste manier om samenvattende tabellen te maken in R
Hoe de samenvatting van vijf getallen in R te berekenen
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder