Waarschijnlijkheidsverdeling
In dit artikel wordt uitgelegd wat kansverdelingen in de statistiek zijn. Zo vindt u de definitie van kansverdeling, voorbeelden van kansverdelingen en de verschillende soorten kansverdelingen.
Wat is een kansverdeling?
Een kansverdeling is een functie die de waarschijnlijkheid definieert dat elke waarde van een willekeurige variabele voorkomt. Simpel gezegd is een kansverdeling een wiskundige functie die de waarschijnlijkheid van alle mogelijke uitkomsten van een willekeurig experiment beschrijft.
Laat bijvoorbeeld
Daarom worden kansverdelingen vaak gebruikt in de waarschijnlijkheidstheorie en statistiek, omdat ze worden gebruikt om de waarschijnlijkheid van verschillende gebeurtenissen in een steekproefruimte te berekenen.
Soorten kansverdelingen
Kansverdelingen kunnen in twee brede typen worden verdeeld: discrete verdelingen en continue verdelingen.
- Discrete kansverdeling: De verdeling kan slechts een telbaar aantal waarden in een interval aannemen. Normaal gesproken kunnen discrete kansverdelingen alleen gehele waarden aannemen, dat wil zeggen dat ze geen decimalen hebben.
- Continue kansverdeling: De verdeling kan een oneindig aantal waarden in een interval aannemen. Over het algemeen kunnen continue kansverdelingen decimale waarden aannemen.
Discrete kansverdelingen
Een discrete kansverdeling is de verdeling die de kansen van een discrete willekeurige variabele definieert. Daarom kan een discrete kansverdeling slechts een eindig aantal waarden aannemen (meestal gehele waarden).
Discrete uniforme distributie
Discrete uniforme verdeling is een discrete kansverdeling waarin alle waarden gelijkwaardig zijn, dat wil zeggen dat in een discrete uniforme verdeling alle waarden dezelfde waarschijnlijkheid hebben om te voorkomen.
De worp van een dobbelsteen kan bijvoorbeeld worden gedefinieerd met een discrete uniforme verdeling, aangezien alle mogelijke uitkomsten (1, 2, 3, 4, 5 of 6) dezelfde waarschijnlijkheid van voorkomen hebben.
Over het algemeen heeft een discrete uniforme verdeling twee karakteristieke parameters, a en b , die het bereik van mogelijke waarden definiëren die de verdeling kan aannemen. Wanneer een variabele dus wordt gedefinieerd door een discrete uniforme verdeling, wordt deze geschreven Uniform(a,b) .

De discrete uniforme verdeling kan worden gebruikt om willekeurige experimenten te beschrijven, want als alle uitkomsten dezelfde waarschijnlijkheid hebben, betekent dit dat het experiment willekeurig is.
Bernoulli-distributie
De Bernoulli-verdeling , ook bekend als de dichotome verdeling , is een kansverdeling die een discrete variabele vertegenwoordigt die slechts twee uitkomsten kan hebben: „succes“ of „mislukking“.
In de Bernoulli-verdeling is ’succes‘ de uitkomst die we verwachten en heeft deze de waarde 1, terwijl de uitkomst van ‚mislukking‘ een andere uitkomst is dan de verwachte en de waarde 0 heeft. Dus als de waarschijnlijkheid van de uitkomst ‚ succes” is p , de waarschijnlijkheid van de uitkomst van “mislukking” is q=1-p .
![\begin{array}{c}X\sim \text{Bernoulli}(p)\\[2ex]\begin{array}{l} \text{\'Exito}\ \color{orange}\bm{\longrightarrow}\color{black} \ P[X=1]=p\\[2ex]\text{Fracaso}\ \color{orange}\bm{\longrightarrow}\color{black} \ P[X=0]=q=1-p\end{array}\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-384fd7d96d4d6584739b04a6e331b251_l3.png "Rendered by QuickLaTeX.com")
De Bernoulli-verdeling is vernoemd naar de Zwitserse statisticus Jacob Bernoulli.
In de statistiek heeft de Bernoulli-verdeling hoofdzakelijk één toepassing: het definiëren van de waarschijnlijkheden van experimenten waarbij er slechts twee mogelijke uitkomsten zijn: succes en mislukking. Een experiment dat de Bernoulli-verdeling gebruikt, wordt dus een Bernoulli-test of Bernoulli-experiment genoemd.
Binomiale verdeling
De binomiale verdeling , ook wel de binomiale verdeling genoemd, is een kansverdeling die het aantal successen telt bij het uitvoeren van een reeks onafhankelijke, dichotome experimenten met een constante kans op succes. Met andere woorden: de binomiale verdeling is een verdeling die het aantal succesvolle uitkomsten van een reeks Bernoulli-proeven beschrijft.
Het aantal keren dat er „kop“ verschijnt bij het 25 keer opgooien van een munt is bijvoorbeeld een binominale verdeling.
Over het algemeen wordt het totale aantal uitgevoerde experimenten gedefinieerd met de parameter n , terwijl p de kans op succes van elk experiment is. Een willekeurige variabele die een binominale verdeling volgt, wordt dus als volgt geschreven:

Merk op dat in een binominale verdeling exact hetzelfde experiment n keer wordt herhaald en dat de experimenten onafhankelijk van elkaar zijn, dus de kans op succes van elk experiment is hetzelfde (p) .
Vis distributie
De Poisson-verdeling is een waarschijnlijkheidsverdeling die de waarschijnlijkheid definieert dat een bepaald aantal gebeurtenissen gedurende een bepaalde periode plaatsvindt. Met andere woorden: de Poisson-verdeling wordt gebruikt om willekeurige variabelen te modelleren die het aantal keren beschrijven dat een fenomeen zich binnen een tijdsinterval herhaalt.
Het aantal oproepen dat een telefooncentrale per minuut ontvangt, is bijvoorbeeld een discrete willekeurige variabele die kan worden gedefinieerd met behulp van de Poisson-verdeling.
De Poisson-verdeling heeft een karakteristieke parameter, weergegeven door de Griekse letter λ, en geeft aan hoe vaak de bestudeerde gebeurtenis naar verwachting zal plaatsvinden tijdens een bepaald interval.

multinomiale distributie
De multinomiale verdeling (of multinomiale verdeling ) is een waarschijnlijkheidsverdeling die de waarschijnlijkheid beschrijft dat verschillende elkaar uitsluitende gebeurtenissen na verschillende pogingen een bepaald aantal keren voorkomen.
Dat wil zeggen, als een willekeurig experiment kan resulteren in drie of meer exclusieve gebeurtenissen en de waarschijnlijkheid dat elke gebeurtenis afzonderlijk plaatsvindt bekend is, wordt de multinomiale verdeling gebruikt om de waarschijnlijkheid te berekenen dat wanneer meerdere experimenten worden uitgevoerd, een bepaald aantal gebeurtenissen plaatsvindt. keer elke keer.
De multinomiale verdeling is daarom een generalisatie van de binominale verdeling.
geometrische distributie
De geometrische verdeling is een waarschijnlijkheidsverdeling die het aantal Bernoulli-pogingen definieert dat nodig is om het eerste succesvolle resultaat te verkrijgen. Dat wil zeggen, een geometrische verdeling modelleert processen waarin Bernoulli-experimenten worden herhaald totdat een van hen een positief resultaat verkrijgt.
Het aantal auto’s dat op een snelweg passeert totdat ze een gele auto zien, is bijvoorbeeld een geometrische verdeling.
Bedenk dat een Bernoulli-test een experiment is dat twee mogelijke uitkomsten heeft: ’succes‘ en ‚mislukking‘. Dus als de kans op ‘succes’ p is, is de kans op ‘mislukking’ q=1-p .
De geometrische verdeling hangt daarom af van de parameter p , de kans op succes van alle uitgevoerde experimenten. Bovendien is de waarschijnlijkheid p voor alle experimenten hetzelfde.

negatieve binomiale verdeling
De negatieve binomiale verdeling is een waarschijnlijkheidsverdeling die het aantal Bernoulli-proeven beschrijft dat nodig is om een bepaald aantal positieve resultaten te verkrijgen.
Daarom heeft een negatieve binomiale verdeling twee karakteristieke parameters: r is het aantal gewenste succesvolle uitkomsten en p is de kans op succes voor elk uitgevoerd Bernoulli-experiment.

Een negatieve binominale verdeling definieert dus een proces waarin zoveel Bernoulli-proeven worden uitgevoerd als nodig is om positieve resultaten te verkrijgen. Bovendien zijn al deze Bernoulli-proeven onafhankelijk en hebben ze een constante kans op succes .
Een willekeurige variabele die een negatieve binominale verdeling volgt, is bijvoorbeeld het aantal keren dat een dobbelsteen moet worden gegooid totdat het getal 6 drie keer wordt gegooid.
hypergeometrische distributie
De hypergeometrische verdeling is een waarschijnlijkheidsverdeling die het aantal succesvolle gevallen beschrijft in een willekeurige extractie zonder vervanging van n elementen uit een populatie.
Dat wil zeggen dat de hypergeometrische verdeling wordt gebruikt om de waarschijnlijkheid te berekenen van het verkrijgen van x successen bij het extraheren van n elementen uit een populatie zonder een van deze te vervangen.
Daarom heeft de hypergeometrische verdeling drie parameters:
- N : is het aantal elementen in de populatie (N = 0, 1, 2,…).
- K : is het maximale aantal succesgevallen (K = 0, 1, 2,…,N). Omdat bij een hypergeometrische verdeling een element alleen als een „succes“ of een „mislukking“ kan worden beschouwd, is NK het maximale aantal faalgevallen.
- n : is het aantal niet-vervangingsophaalacties dat wordt uitgevoerd.

Continue waarschijnlijkheidsverdelingen
Een continue kansverdeling is een kansverdeling die elke waarde in een interval kan aannemen, inclusief decimale waarden. Daarom definieert een continue kansverdeling de kansen van een continue willekeurige variabele.
uniforme en continue distributie
De continue uniforme verdeling , ook wel de rechthoekige verdeling genoemd, is een soort continue kansverdeling waarbij alle waarden dezelfde kans hebben om te verschijnen. Met andere woorden: de continue uniforme verdeling is een verdeling waarbij de waarschijnlijkheid uniform verdeeld is over een interval.
De continue uniforme verdeling wordt gebruikt om continue variabelen te beschrijven die een constante waarschijnlijkheid hebben. Op dezelfde manier wordt continue uniforme verdeling gebruikt om willekeurige processen te definiëren, omdat als alle uitkomsten dezelfde waarschijnlijkheid hebben, dit betekent dat er willekeur in de uitkomst zit.
De continue uniforme verdeling heeft twee karakteristieke parameters, a en b , die het equiprobabiliteitsinterval definiëren. Het symbool voor de continue uniforme verdeling is dus U(a,b) , waarbij a en b de karakteristieke waarden van de verdeling zijn.

Als de uitkomst van een willekeurig experiment bijvoorbeeld elke waarde tussen 5 en 9 kan aannemen en alle mogelijke uitkomsten dezelfde waarschijnlijkheid hebben om te voorkomen, kan het experiment worden gesimuleerd met een continue uniforme verdeling U(5.9).
Normale verdeling
De normale verdeling is een continue kansverdeling waarvan de grafiek klokvormig is en symmetrisch ten opzichte van het gemiddelde. In de statistiek wordt de normale verdeling gebruikt om verschijnselen met zeer verschillende kenmerken te modelleren. Daarom is deze verdeling zo belangrijk.
In feite wordt de normale verdeling in de statistiek beschouwd als verreweg de belangrijkste verdeling van alle waarschijnlijkheidsverdelingen, omdat deze niet alleen een groot aantal verschijnselen uit de echte wereld kan modelleren, maar de normale verdeling ook kan worden gebruikt om andere typen kansverdelingen te benaderen. distributies. onder bepaalde omstandigheden.
Het symbool voor normale verdeling is de hoofdletter N. Om aan te geven dat een variabele een normale verdeling volgt, wordt deze aangegeven met de letter N en worden de waarden van het rekenkundig gemiddelde en de standaarddeviatie tussen haakjes toegevoegd.

De normale verdeling heeft veel verschillende namen, waaronder Gaussische verdeling , Gaussische verdeling en Laplace-Gauss-verdeling .
Lognormale verdeling
De lognormale verdeling , of lognormale verdeling , is een kansverdeling die een willekeurige variabele definieert waarvan de logaritme een normale verdeling volgt.
Als de variabele X dus een normale verdeling heeft, heeft de exponentiële functie ex x een lognormale verdeling.

Merk op dat de lognormale verdeling alleen kan worden gebruikt als de waarden van de variabele positief zijn, aangezien de logaritme een functie is die slechts één positief argument accepteert.
Onder de verschillende toepassingen van de lognormale verdeling in de statistiek onderscheiden we het gebruik van deze verdeling om financiële investeringen te analyseren en betrouwbaarheidsanalyses uit te voeren.
De lognormale verdeling is ook bekend als de Tinaut-verdeling , soms ook geschreven als de lognormale verdeling of log-normale verdeling .
Chi-kwadraatverdeling
De Chi-kwadraatverdeling is een kansverdeling waarvan het symbool χ² is. Preciezer gezegd: de Chi-kwadraatverdeling is de som van het kwadraat van k onafhankelijke willekeurige variabelen met een normale verdeling.
De Chi-kwadraatverdeling heeft dus k vrijheidsgraden. Daarom heeft een Chi-kwadraatverdeling evenveel vrijheidsgraden als de som van de kwadraten van de normaal verdeelde variabelen die deze vertegenwoordigt.
![\displaystyle X\sim\chi^2_k \ \color{orange}\bm{\longrightarrow}\color{black}\ \begin{array}{l}\text{Distribuci\'on chi-cuadrado}\\[2ex]\text{con k grados de libertad}\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-9ea0bf7a87071883ceae5e419bae9e71_l3.png "Rendered by QuickLaTeX.com")
De Chi-kwadraatverdeling wordt ook wel de Pearson-verdeling genoemd.
De chikwadraatverdeling wordt veel gebruikt bij statistische gevolgtrekkingen, bijvoorbeeld bij het testen van hypothesen en betrouwbaarheidsintervallen. We zullen hieronder zien wat de toepassingen zijn van dit type kansverdeling.
Student’s t-verdeling
De Student’s t-verdeling is een kansverdeling die veel wordt gebruikt in de statistiek. Concreet wordt de Student’s t-verdeling gebruikt in de Student’s t-test om het verschil tussen de gemiddelden van twee steekproeven te bepalen en om betrouwbaarheidsintervallen vast te stellen.
De Student’s t-verdeling werd in 1908 ontwikkeld door statisticus William Sealy Gosset onder het pseudoniem „Student“.
De t-verdeling van de Student wordt gedefinieerd door het aantal vrijheidsgraden, verkregen door één eenheid af te trekken van het totale aantal waarnemingen. Daarom is de formule voor het bepalen van de vrijheidsgraden van een Student’s t-verdeling v=n-1 .
![\begin{array}{c}\nu=n-1\\[2ex]X\sim t_\nu\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-1c805dc2d6ca050feb70dad99de53402_l3.png "Rendered by QuickLaTeX.com")
Snedecor F-distributie
De Snedecor F-verdeling , ook wel de Fisher-Snedecor F-verdeling of eenvoudigweg F-verdeling genoemd, is een continue kansverdeling die wordt gebruikt bij statistische gevolgtrekkingen, vooral bij variantieanalyse.
Een van de eigenschappen van de Snedecor F-verdeling is dat deze wordt gedefinieerd door de waarde van twee reële parameters, m en n , die de vrijheidsgraden aangeven. Het symbool voor de Snedecor-verdeling F is dus Fm ,n , waarbij m en n de parameters zijn die de verdeling definiëren.
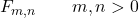
![\left.\begin{array}{c} X\sim \chi_m^2\\[2ex] Y\sim \chi_n^2\end{array}\right\}\color{orange}\bm{\longrightarrow}\color{black}\ F_{m,n}= \cfrac{X/m}{Y/n}](https://statorials.org/wp-content/ql-cache/quicklatex.com-d407869e61ca4357ffbcb40df3bd83ab_l3.png "Rendered by QuickLaTeX.com")
De Fisher-Snedecor F-verdeling dankt zijn naam aan de Engelse statisticus Ronald Fisher en de Amerikaanse statisticus George Snedecor.
In de statistieken heeft de Fisher-Snedecor F-verdeling verschillende toepassingen. De Fisher-Snedecor F-verdeling wordt bijvoorbeeld gebruikt om verschillende lineaire regressiemodellen te vergelijken, en deze waarschijnlijkheidsverdeling wordt gebruikt bij variantieanalyse (ANOVA).
exponentiële verdeling
De exponentiële verdeling is een continue kansverdeling die wordt gebruikt om de wachttijd voor het optreden van een willekeurig fenomeen te modelleren.
Nauwkeuriger gezegd maakt de exponentiële verdeling het mogelijk om de wachttijd tussen twee verschijnselen te beschrijven die een Poisson-verdeling volgt. Daarom is de exponentiële verdeling nauw verwant aan de Poisson-verdeling.
De exponentiële verdeling heeft een karakteristieke parameter, weergegeven door de Griekse letter λ, en geeft aan hoe vaak de bestudeerde gebeurtenis naar verwachting zal plaatsvinden gedurende een bepaalde tijdsperiode.

Op dezelfde manier wordt de exponentiële verdeling ook gebruikt om de tijd te modelleren totdat er een storing optreedt. De exponentiële verdeling heeft daarom verschillende toepassingen in de betrouwbaarheids- en overlevingstheorie.
Bètadistributie
De bètaverdeling is een waarschijnlijkheidsverdeling gedefinieerd in het interval (0,1) en geparametriseerd door twee positieve parameters: α en β. Met andere woorden: de waarden van de bètaverdeling zijn afhankelijk van de parameters α en β.
Daarom wordt de bètaverdeling gebruikt om continue willekeurige variabelen te definiëren waarvan de waarde tussen 0 en 1 ligt.
Er zijn verschillende notaties die aangeven dat een continue willekeurige variabele wordt bepaald door een bètaverdeling. De meest voorkomende zijn:
![\begin{array}{c}X\sim B(\alpha,\beta)\\[2ex]X\sim Beta(\alpha,\beta)\\[2ex]X\sim \beta_{\alpha,\beta}\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-ee1d0d8a1624a017b8ef9ce8a67c694e_l3.png "Rendered by QuickLaTeX.com")
In de statistieken heeft de bètadistributie zeer uiteenlopende toepassingen. De bètaverdeling wordt bijvoorbeeld gebruikt om variaties in percentages in verschillende steekproeven te bestuderen. Op dezelfde manier wordt bij projectbeheer bètadistributie gebruikt om Pert-analyse uit te voeren.
Gamma-distributie
De gammaverdeling is een continue waarschijnlijkheidsverdeling die wordt gedefinieerd door twee karakteristieke parameters, α en λ. Met andere woorden, de gammaverdeling hangt af van de waarde van de twee parameters: α is de vormparameter en λ is de schaalparameter.
Het symbool voor de gammaverdeling is de Griekse hoofdletter Γ. Dus als een willekeurige variabele een gammaverdeling volgt, wordt deze als volgt geschreven:

De gammaverdeling kan ook worden geparametriseerd met behulp van de vormparameter k = α en de inverse schaalparameter θ = 1/λ. In alle gevallen zijn de twee parameters die de gammaverdeling bepalen positieve reële getallen.
Doorgaans wordt de gammaverdeling gebruikt om gegevenssets met een rechtse scheefheid te modelleren, zodat er een grotere concentratie van gegevens aan de linkerkant van de grafiek is. De gammaverdeling wordt bijvoorbeeld gebruikt om de betrouwbaarheid van elektrische componenten te modelleren.
Weibull-distributie
De Weibull-verdeling is een continue waarschijnlijkheidsverdeling die wordt gedefinieerd door twee karakteristieke parameters: de vormparameter α en de schaalparameter λ.
In de statistieken wordt de Weibull-verdeling voornamelijk gebruikt voor overlevingsanalyse. Op dezelfde manier heeft de Weibull-distributie veel toepassingen op verschillende gebieden.

Volgens de auteurs kan de Weibull-verdeling ook worden geparametriseerd met drie parameters. Vervolgens wordt een derde parameter, drempelwaarde genaamd, toegevoegd, die de abscis aangeeft waarop de verdelingsgrafiek begint.
De Weibull-verdeling is vernoemd naar de Zweed Waloddi Weibull, die deze in 1951 gedetailleerd beschreef. De Weibull-verdeling werd echter in 1927 ontdekt door Maurice Fréchet en voor het eerst toegepast door Rosin en Rammler in 1933.
Pareto-distributie
De Pareto-verdeling is een continue kansverdeling die in statistieken wordt gebruikt om het Pareto-principe te modelleren. Daarom is de Pareto-verdeling een kansverdeling die een paar waarden heeft waarvan de waarschijnlijkheid van voorkomen veel groter is dan de rest van de waarden.
Bedenk dat de wet van Pareto, ook wel de 80-20-regel genoemd, een statistisch principe is dat zegt dat het grootste deel van de oorzaak van een fenomeen te wijten is aan een klein deel van de bevolking.
De Pareto-verdeling heeft twee karakteristieke parameters: de schaalparameter x m en de vormparameter α.

Oorspronkelijk werd de Pareto-verdeling gebruikt om de verdeling van de rijkdom binnen de bevolking te beschrijven, omdat het grootste deel ervan te danken was aan een klein deel van de bevolking. Maar momenteel heeft de Pareto-verdeling vele toepassingen, bijvoorbeeld in de kwaliteitscontrole, in de economie, in de wetenschap, op sociaal gebied, enz.
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder