Hoe u een voortschrijdend gemiddelde in panda's kunt berekenen
Een voortschrijdend gemiddelde is eenvoudigweg het gemiddelde van een aantal voorgaande perioden in een tijdreeks.
Om het voortschrijdend gemiddelde van een of meer kolommen in een Panda DataFrame te berekenen, kunnen we de volgende syntaxis gebruiken:
df[' column_name ']. rolling ( rolling_window ). mean ()
Deze tutorial biedt verschillende voorbeelden van praktisch gebruik van deze functie.
Voorbeeld: berekening van het voortschrijdend gemiddelde in panda’s
Stel dat we de volgende panda’s DataFrame hebben:
import numpy as np import pandas as pd #make this example reproducible n.p. random . seeds (0) #create dataset period = np. arange (1, 101, 1) leads = np. random . uniform (1, 20, 100) sales = 60 + 2*period + np. random . normal (loc=0, scale=.5*period, size=100) df = pd. DataFrame ({' period ': period, ' leads ': leads, ' sales ': sales}) #view first 10 rows df. head (10) period leads sales 0 1 11.427457 61.417425 1 2 14.588598 64.900826 2 3 12.452504 66.698494 3 4 11.352780 64.927513 4 5 9.049441 73.720630 5 6 13.271988 77.687668 6 7 9.314157 78.125728 7 8 17.943687 75.280301 8 9 19.309592 73.181613 9 10 8.285389 85.272259
We kunnen de volgende syntaxis gebruiken om een nieuwe kolom te maken met het voortschrijdend gemiddelde van „verkoop“ voor de voorgaande 5 perioden:
#find rolling mean of previous 5 sales periods df[' rolling_sales_5 '] = df[' sales ']. rolling (5). mean () #view first 10 rows df. head (10) period leads sales rolling_sales_5 0 1 11.427457 61.417425 NaN 1 2 14.588598 64.900826 NaN 2 3 12.452504 66.698494 NaN 3 4 11.352780 64.927513 NaN 4 5 9.049441 73.720630 66.332978 5 6 13.271988 77.687668 69.587026 6 7 9.314157 78.125728 72.232007 7 8 17.943687 75.280301 73.948368 8 9 19.309592 73.181613 75.599188 9 10 8.285389 85.272259 77.909514
We kunnen handmatig verifiëren dat het voortschrijdende verkoopgemiddelde dat voor periode 5 wordt weergegeven, het gemiddelde is van de voorgaande 5 perioden:
Voortschrijdend gemiddelde in periode 5: (61,417+64,900+66,698+64,927+73,720)/5 = 66,33
We kunnen een vergelijkbare syntaxis gebruiken om het voortschrijdend gemiddelde van meerdere kolommen te berekenen:
#find rolling mean of previous 5 leads periods df[' rolling_leads_5 '] = df[' leads ']. rolling (5). mean () #find rolling mean of previous 5 leads periods df[' rolling_sales_5 '] = df[' sales ']. rolling (5). mean () #view first 10 rows df. head (10) period leads sales rolling_sales_5 rolling_leads_5 0 1 11.427457 61.417425 NaN NaN 1 2 14.588598 64.900826 NaN NaN 2 3 12.452504 66.698494 NaN NaN 3 4 11.352780 64.927513 NaN NaN 4 5 9.049441 73.720630 66.332978 11.774156 5 6 13.271988 77.687668 69.587026 12.143062 6 7 9.314157 78.125728 72.232007 11.088174 7 8 17.943687 75.280301 73.948368 12.186411 8 9 19.309592 73.181613 75.599188 13.777773 9 10 8.285389 85.272259 77.909514 13.624963
We kunnen ook een snelle lijngrafiek maken met behulp van Matplotlib om de bruto-omzet versus het voortschrijdend verkoopgemiddelde te visualiseren:
import matplotlib. pyplot as plt
plt. plot (df[' rolling_sales_5 '], label=' Rolling Mean ')
plt. plot (df[' sales '], label=' Raw Data ')
plt. legend ()
plt. ylabel (' Sales ')
plt. xlabel (' Period ')
plt. show ()
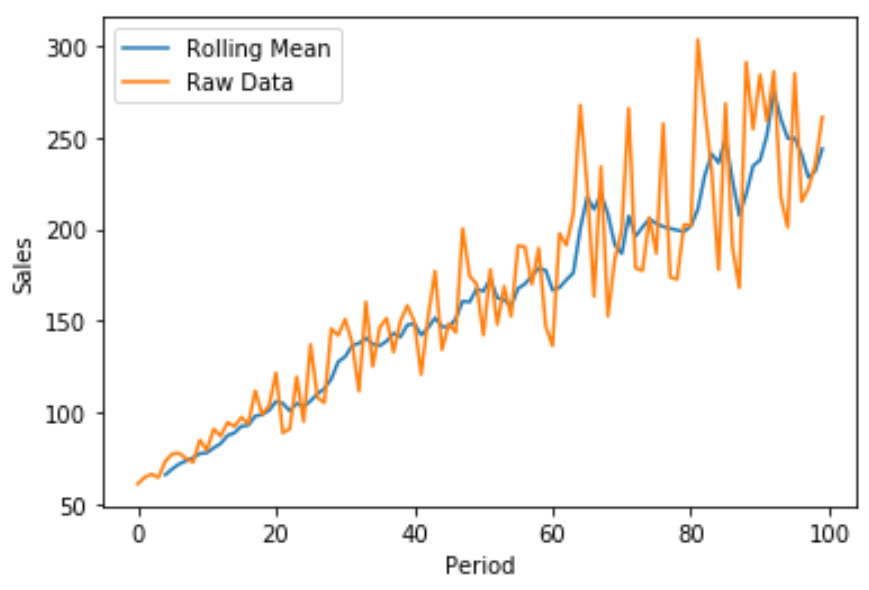
De blauwe lijn toont het voortschrijdend verkoopgemiddelde over vijf perioden en de oranje lijn toont de ruwe verkoopgegevens.
Aanvullende bronnen
In de volgende tutorials wordt uitgelegd hoe u andere veelvoorkomende taken in panda’s kunt uitvoeren:
Hoe de glijdende correlatie bij panda’s te berekenen
Hoe het gemiddelde van kolommen in Panda’s te berekenen
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder