Hoe de logest-functie in google spreadsheets te gebruiken (met voorbeeld)
U kunt de LOGEST- functie in Google Spreadsheets gebruiken om de formule te berekenen voor een exponentiële curve die bij uw gegevens past.
De vergelijking van de curve zal de volgende vorm aannemen:
y = b* mx
Deze functie gebruikt de volgende basissyntaxis:
= LOGEST ( known_data_y, [known_data_x], [b], [verbose] )
Goud:
- bekende_data_y : Een array met bekende y-waarden
- bekende_data_x : een array met bekende x-waarden
- b : Optioneel argument. Indien WAAR, wordt constante b normaal verwerkt. Indien ONWAAR, wordt constante b ingesteld op 1.
- verbose : optioneel argument. Indien TRUE worden aanvullende regressiestatistieken geretourneerd. Als FALSE worden er geen aanvullende regressiestatistieken geretourneerd.
Het volgende stap-voor-stap voorbeeld laat zien hoe u deze functie in de praktijk kunt gebruiken.
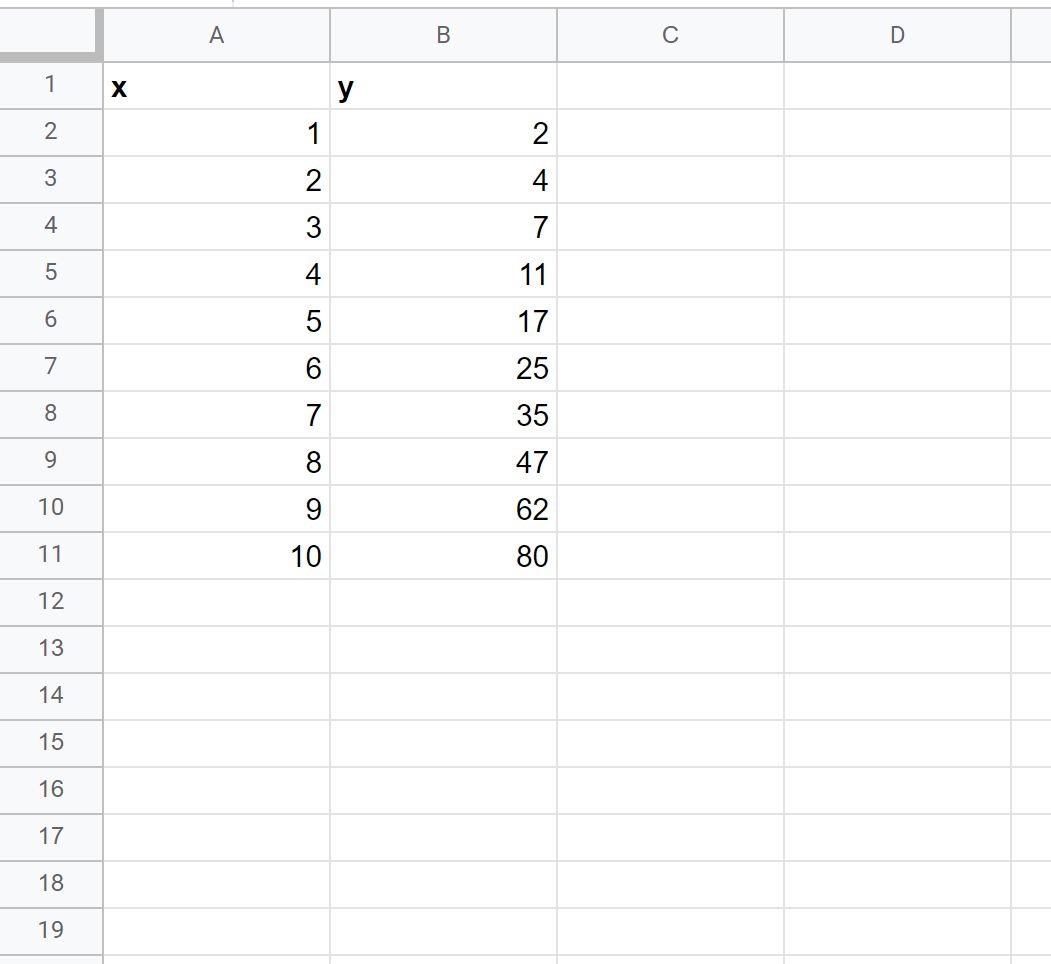
Stap 1: Voer de gegevens in
Laten we eerst de volgende gegevensset in Google Spreadsheets invoeren:
Stap 2: Visualiseer de gegevens
Laten we vervolgens een snelle spreidingsdiagram maken van x versus y om te verifiëren dat de gegevens daadwerkelijk een exponentiële curve volgen:
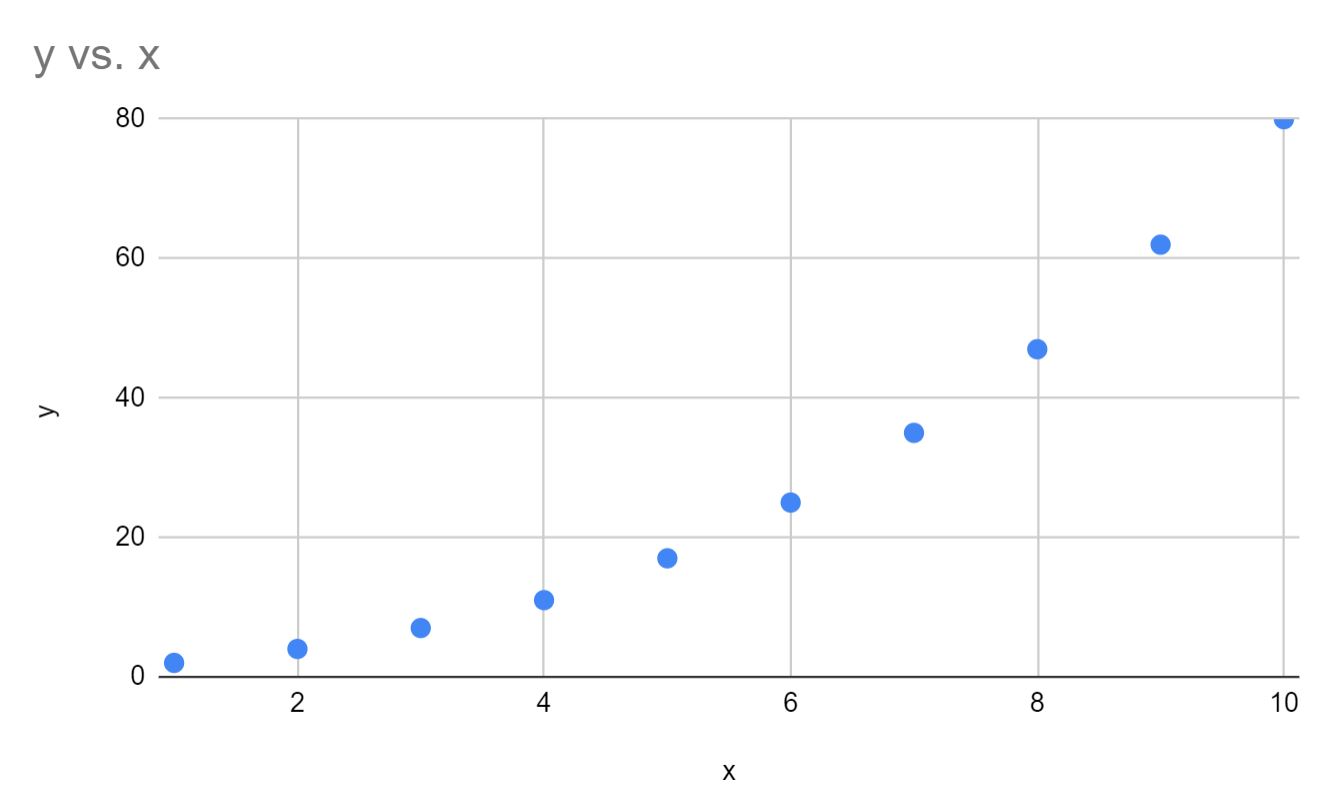
We kunnen zien dat de gegevens inderdaad een exponentiële curve volgen.
Stap 3: Gebruik LOGEST om de formule voor de exponentiële curve te vinden
Vervolgens kunnen we de volgende formule in elke cel typen om de exponentiële curve-formule te berekenen:
=LOGEST( B2:B11 , A2:A11 )
De volgende schermafbeelding laat zien hoe u deze formule in de praktijk kunt gebruiken:
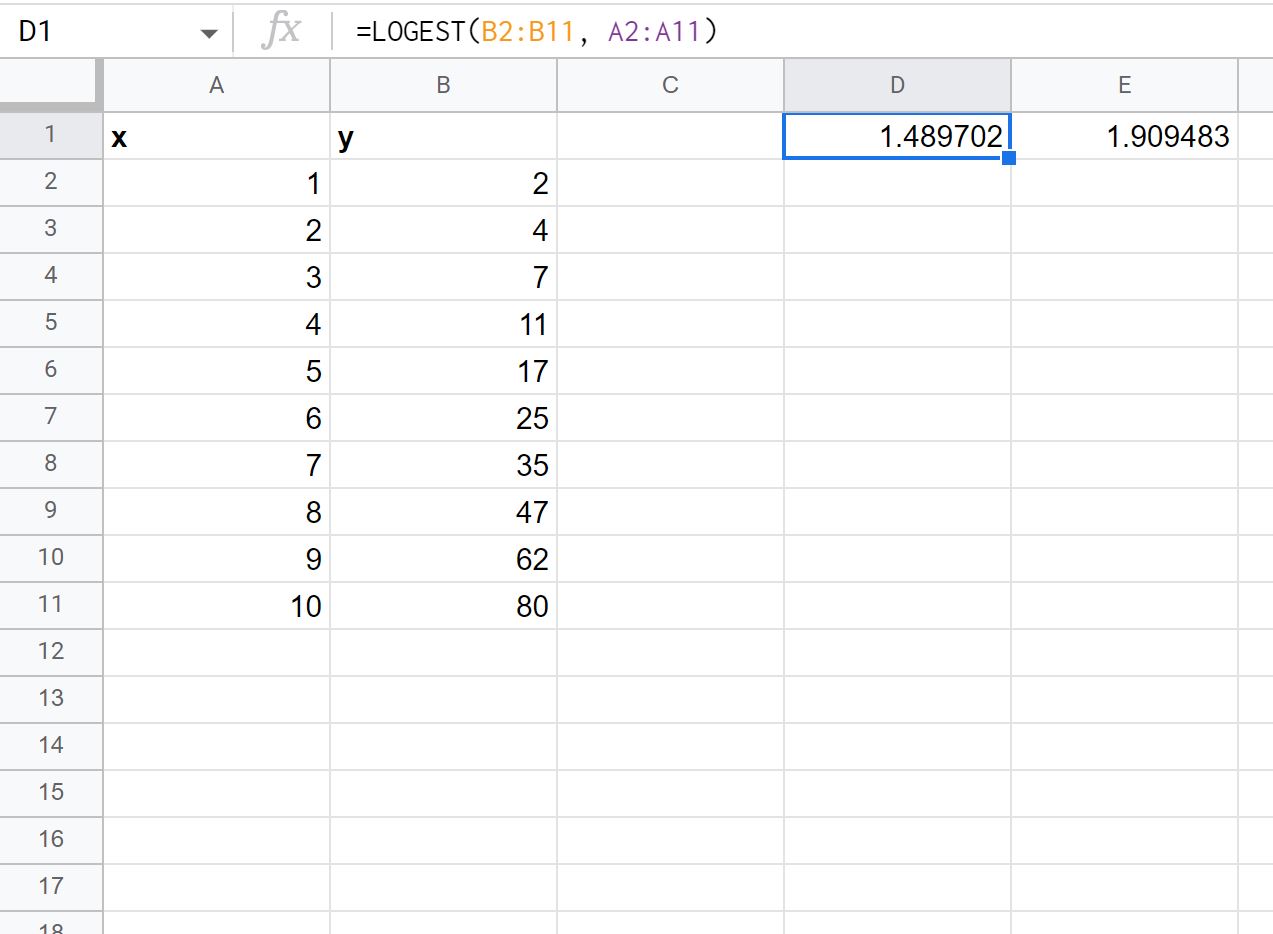
De eerste waarde van de uitvoer vertegenwoordigt de waarde van m en de tweede waarde van de uitvoer vertegenwoordigt de waarde van b in de vergelijking:
y = b* mx
We zouden deze exponentiële curve-formule dus als volgt schrijven:
y = 1,909483 * 1,489702x
We zouden deze formule dan kunnen gebruiken om de waarden van y te voorspellen op basis van de waarde van x.
Als xa bijvoorbeeld een waarde van 8 heeft, voorspellen we dat y een waarde van 46,31 heeft:
j = 1,909483 * 1,489702 8 = 46,31
Stap 4 (Optioneel): Bekijk aanvullende regressiestatistieken
We kunnen de gedetailleerde argumentwaarde in de LOGEST- functie gelijk stellen aan TRUE om aanvullende regressiestatistieken weer te geven voor de aangepaste regressievergelijking:
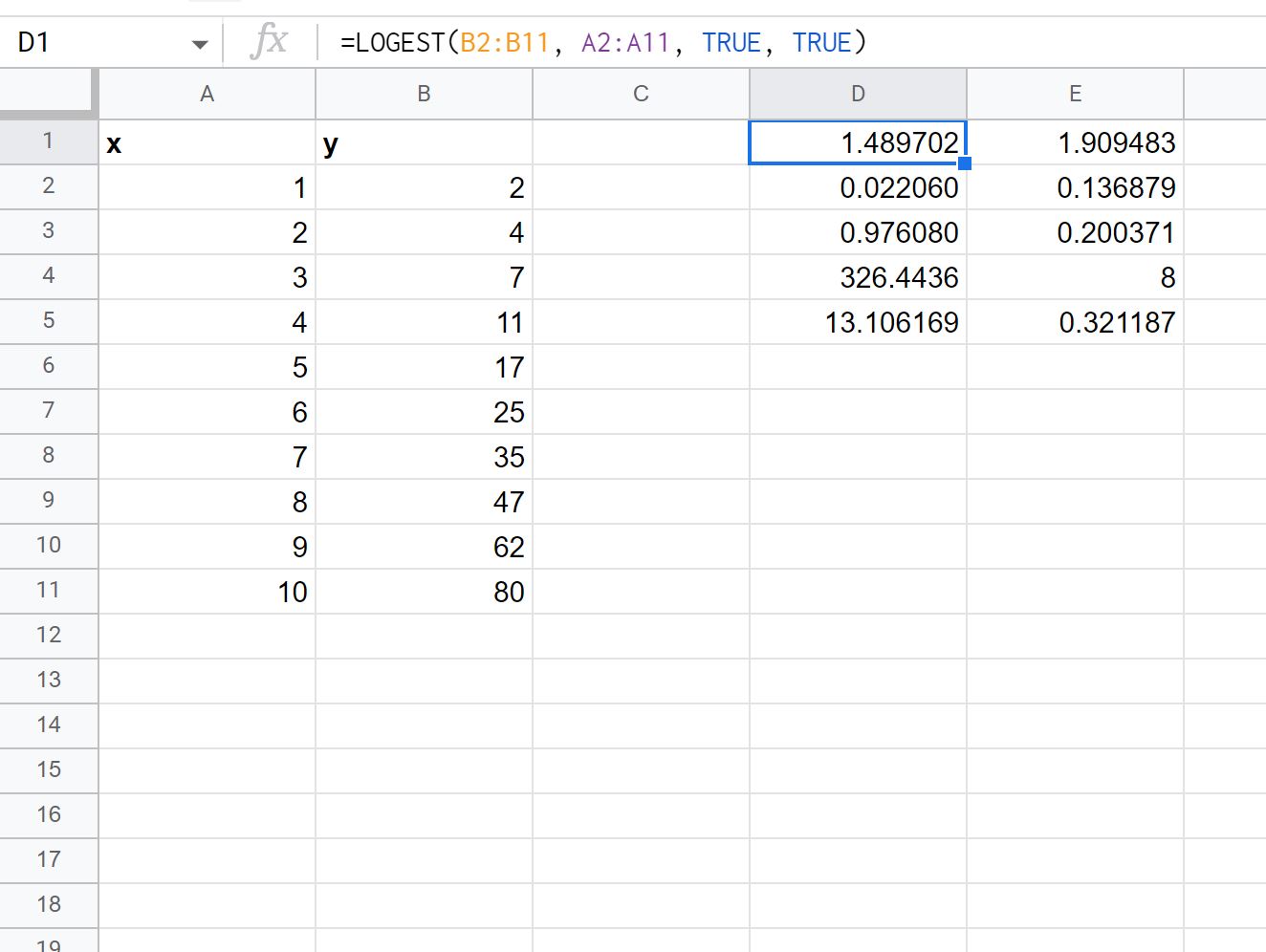
Zo interpreteert u elke waarde in het resultaat:
- De standaardfout voor m is 0,02206 .
- De standaardfout voor b is 0,136879 .
- De R 2 van het model is .97608 .
- De standaardfout voor y is .200371 .
- De F-statistiek is 326,4436 .
- De vrijheidsgraden zijn 8 .
- De regressiesom van de kwadraten is 13,106169 .
- De resterende kwadratensom is .321187 .
Over het algemeen is de maatstaf die in deze aanvullende statistieken het meest interessant is, de R2- waarde, die het deel van de variantie in de responsvariabele vertegenwoordigt dat kan worden verklaard door de voorspellende variabele.
De waarde van R2 kan variëren van 0 tot 1.
Omdat de R 2 van dit specifieke model dicht bij 1 ligt, vertelt dit ons dat de voorspellende variabele x de waarde van de responsvariabele y goed voorspelt.
Gerelateerd: Wat is een goede R-kwadraatwaarde?
Aanvullende bronnen
In de volgende tutorials wordt uitgelegd hoe u andere veelvoorkomende dingen in Google Spreadsheets kunt doen:
Lineaire regressie uitvoeren in Google Spreadsheets
Hoe polynomiale regressie uit te voeren in Google Spreadsheets
Hoe R-kwadraat te berekenen in Google Spreadsheets
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder