Hoe de volgorde van de staven in seaborn barplot te veranderen
U kunt de volgende methoden gebruiken om de volgorde van staven in een maritiem plot te wijzigen:
Methode 1: Sorteer staven in Barplot gemaakt op basis van onbewerkte gegevens
sns. barplot (x=' xvar ', y=' yvar ', data=df, order=df. sort_values (' yvar '). xvar )
Methode 2: Sorteer staven in Barplot gemaakt op basis van geaggregeerde gegevens
sns. barplot (x=' xvar ', y=' yvar ', data=df, order=df_agg[' xvar ']
De volgende voorbeelden laten zien hoe u elke methode in de praktijk kunt gebruiken.
Voorbeeld 1: Sorteer staven in een staafdiagram gemaakt op basis van onbewerkte gegevens
Stel dat we het volgende panda’s DataFrame hebben dat informatie bevat over de totale omzet van verschillende werknemers van een bedrijf:
import pandas as pd
#createDataFrame
df = pd. DataFrame ({' employee ': ['Andy', 'Bert', 'Chad', 'Doug', 'Eric', 'Frank'],
' sales ': [22, 14, 9, 7, 29, 20]})
#view DataFrame
print (df)
employee sales
0 Andy 22
1 Bert 14
2 Chad 9
3 Doug 7
4 Eric 29
5 Frank 20
We kunnen de volgende syntaxis gebruiken om een staafdiagram te maken waarin de staven in oplopende volgorde worden gesorteerd op basis van de verkoopwaarde :
import seaborn as sns #create barplot with bars sorted by sales values ascending sns. barplot (x=' employee ', y=' sales ', data=df, order=df. sort_values (' sales '). employee )
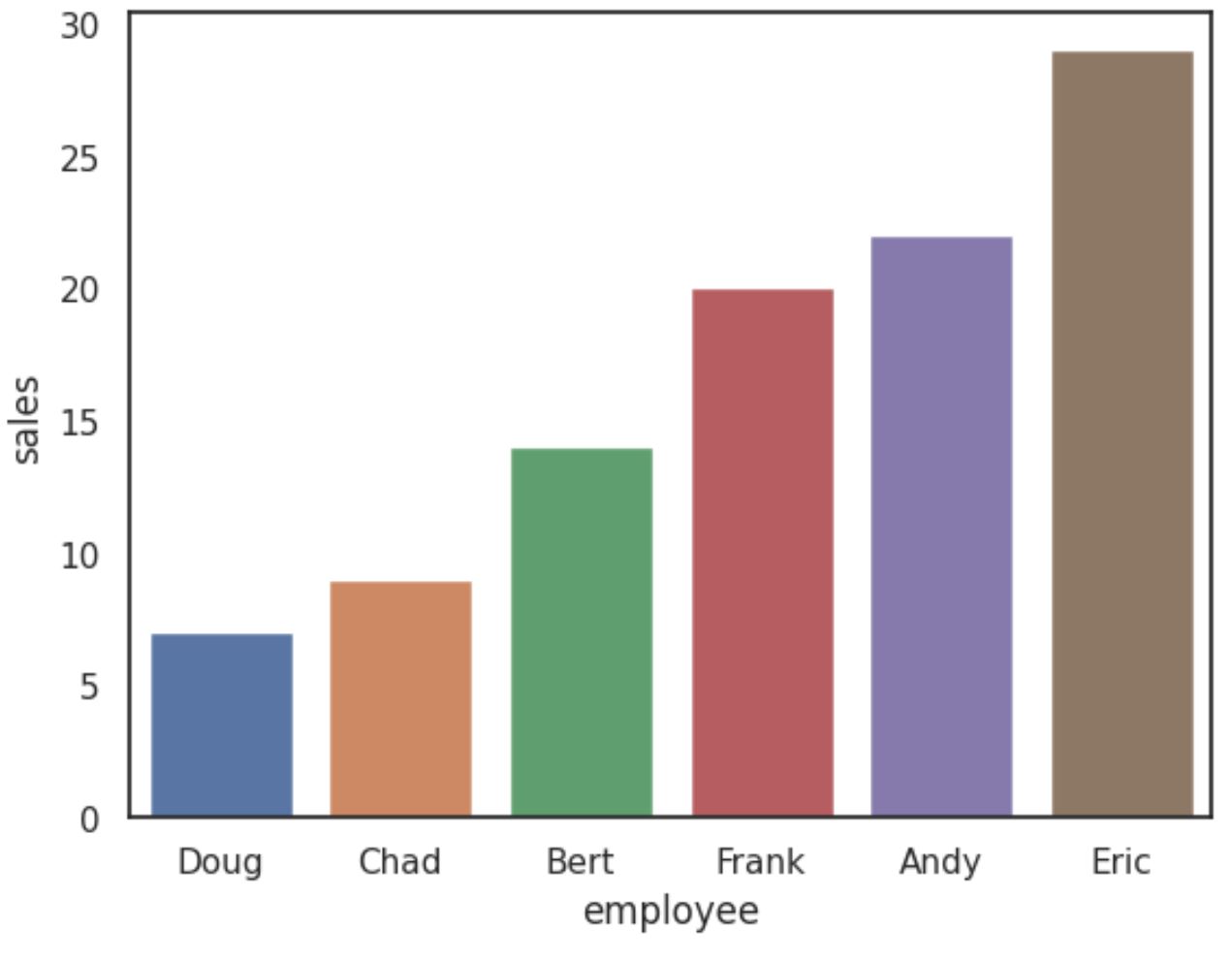
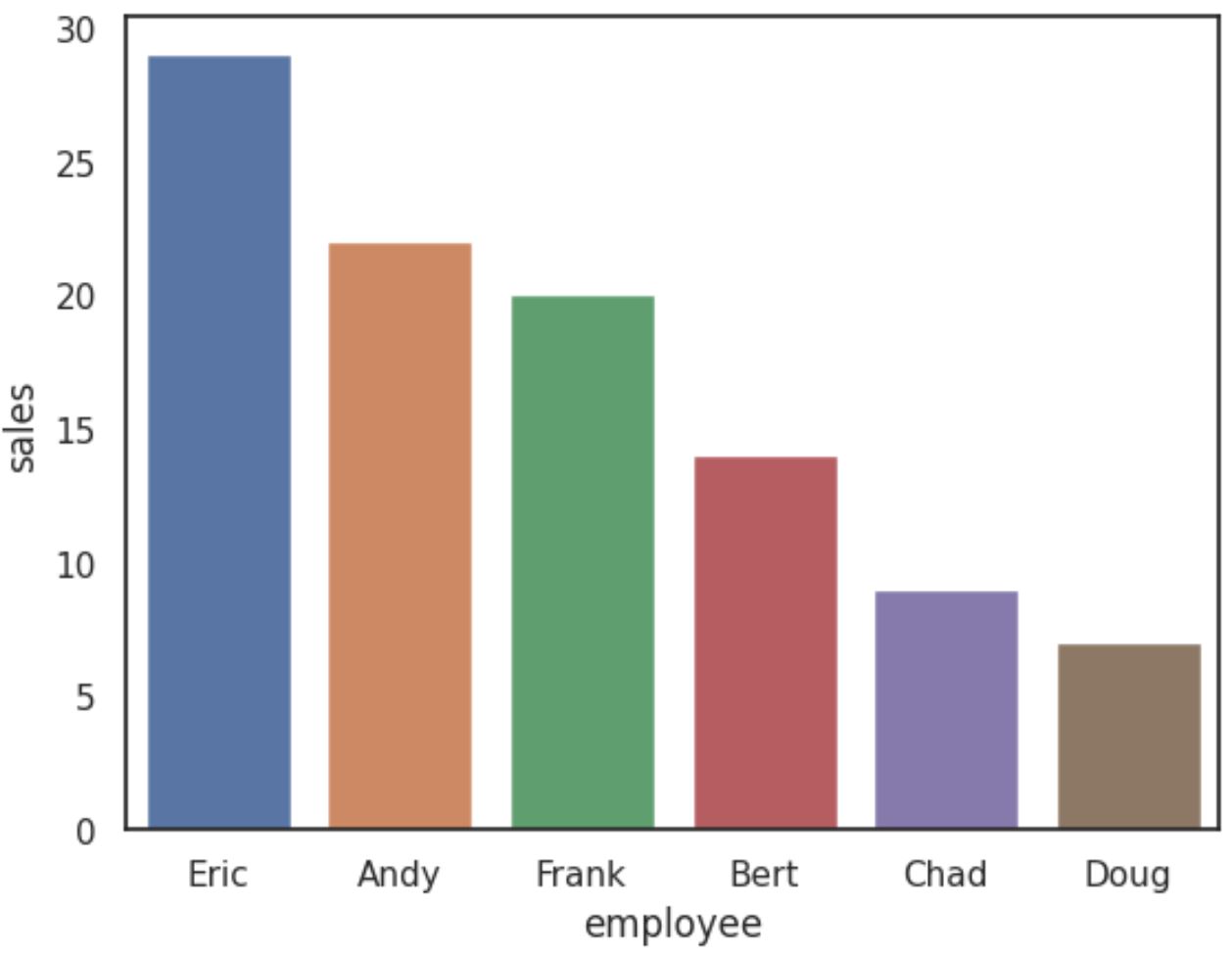
Om de staven in aflopende volgorde te sorteren, gebruikt u eenvoudigweg oplopend=False in de functie sort_values() :
import seaborn as sns #create barplot with bars sorted by sales values descending sns. barplot (x=' employee ', y=' sales ', data=df, order=df. sort_values (' sales ', ascending= False ). employee )
Voorbeeld 2: Sorteerstaven in een staafdiagram gemaakt op basis van geaggregeerde gegevens
Stel dat we het volgende panda’s DataFrame hebben dat informatie bevat over de totale omzet van verschillende werknemers van een bedrijf:
import pandas as pd
#createDataFrame
df = pd. DataFrame ({' employee ': ['A', 'A', 'A', 'B', 'B', 'B', 'C', 'C', 'C'],
' sales ': [24, 20, 25, 14, 19, 13, 30, 35, 28]})
#view DataFrame
print (df)
employee sales
0 to 24
1 to 20
2 to 25
3 B 14
4 B 19
5 B 13
6 C 30
7 C 35
8 C 28
We kunnen de volgende syntaxis gebruiken om de gemiddelde verkoopwaarde te berekenen, gegroepeerd per werknemer :
#calculate mean sales by employee df_agg = df. groupby ([' employee '])[' sales ']. mean (). reset_index (). sort_values (' sales ') #view aggregated data print (df_agg) employee sales 1 B 15.333333 0 to 23.000000 2 C 31.000000
We kunnen vervolgens de volgende syntaxis gebruiken om in Seaborn een staafdiagram te maken dat de gemiddelde omzet per werknemer weergeeft, waarbij de balken in oplopende volgorde worden weergegeven:
import seaborn as sns #create barplot with bars ordered in ascending order by mean sales sns. barplot (x=' employee ', y=' sales ', data=df, order=df_agg[' employee '], errorbar=(' ci ', False ))
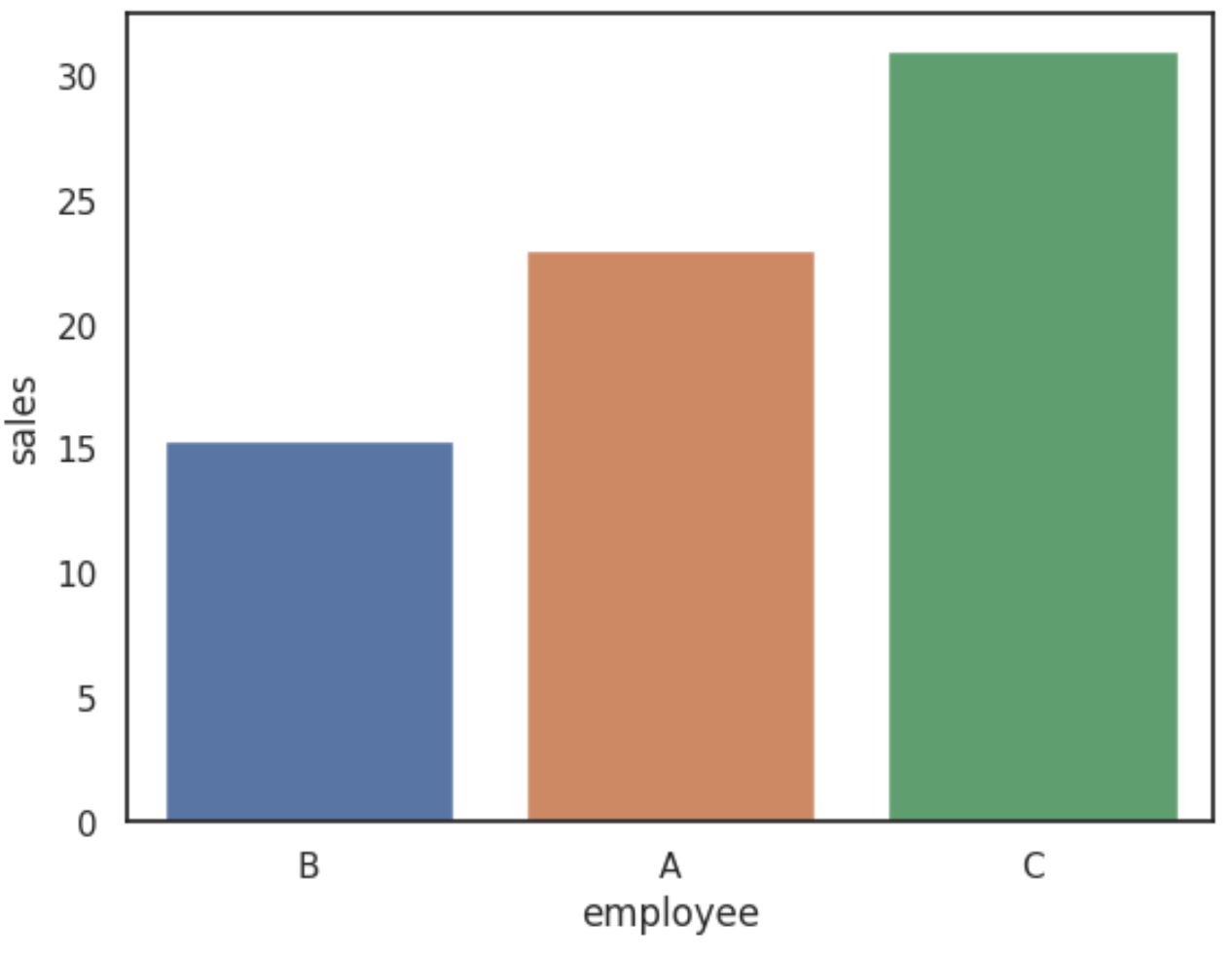
Op de X-as wordt de naam van de werknemer weergegeven en op de Y-as wordt de gemiddelde verkoopwaarde voor elke werknemer weergegeven.
Aanvullende bronnen
In de volgende tutorials wordt uitgelegd hoe u andere veelvoorkomende functies in Seaborn kunt uitvoeren:
Hoe waarden weer te geven op Seaborn Barplot
Hoe maak je een gegroepeerd barplot in Seaborn?
Hoe u de kleur van staven in een Seaborn-barplot instelt
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder