Wat is de normaliteitsaanname in de statistiek?
Veel statistische tests zijn gebaseerd op wat de normaliteitsaanname wordt genoemd.
Deze hypothese stelt dat als we veel onafhankelijke willekeurige steekproeven uit een populatie verzamelen en een interessante waarde berekenen (zoals het steekproefgemiddelde ), en vervolgens een histogram maken om de verdeling van de steekproefgemiddelden te visualiseren, we een perfecte belcurve zouden moeten waarnemen.
Veel statistische technieken gaan uit van deze aanname over gegevens, waaronder:
1. Eén steekproef-t-test : er wordt aangenomen dat de steekproefgegevens normaal verdeeld zijn.
2. T-test met twee steekproeven : er wordt aangenomen dat de twee steekproeven normaal verdeeld zijn.
3. ANOVA : Er wordt aangenomen dat de modelresiduen normaal verdeeld zijn.
4. Lineaire regressie : Er wordt aangenomen dat de modelresiduen normaal verdeeld zijn.
Als niet aan deze veronderstelling wordt voldaan, worden de resultaten van deze tests onbetrouwbaar en kunnen we onze conclusies uit de gegevensmonsters niet met vertrouwen generaliseren naar de totale populatie . Daarom is het belangrijk om te controleren of aan deze hypothese wordt voldaan.
Er zijn twee gebruikelijke manieren om te controleren of aan deze normaliteitsaanname wordt voldaan:
1. Visualiseer normaliteit
2. Voer een formele statistische test uit
In de volgende secties worden de specifieke grafieken uitgelegd die u kunt maken en de specifieke statistische tests die u kunt uitvoeren om te controleren op normaliteit.
Visualiseer normaliteit
Een snelle en informele manier om te controleren of een dataset normaal verdeeld is, is door een histogram of QQ-plot te maken.
1. Histogram
Als het histogram van een gegevensset grofweg klokvormig is, is het waarschijnlijk dat de gegevens normaal verdeeld zijn.
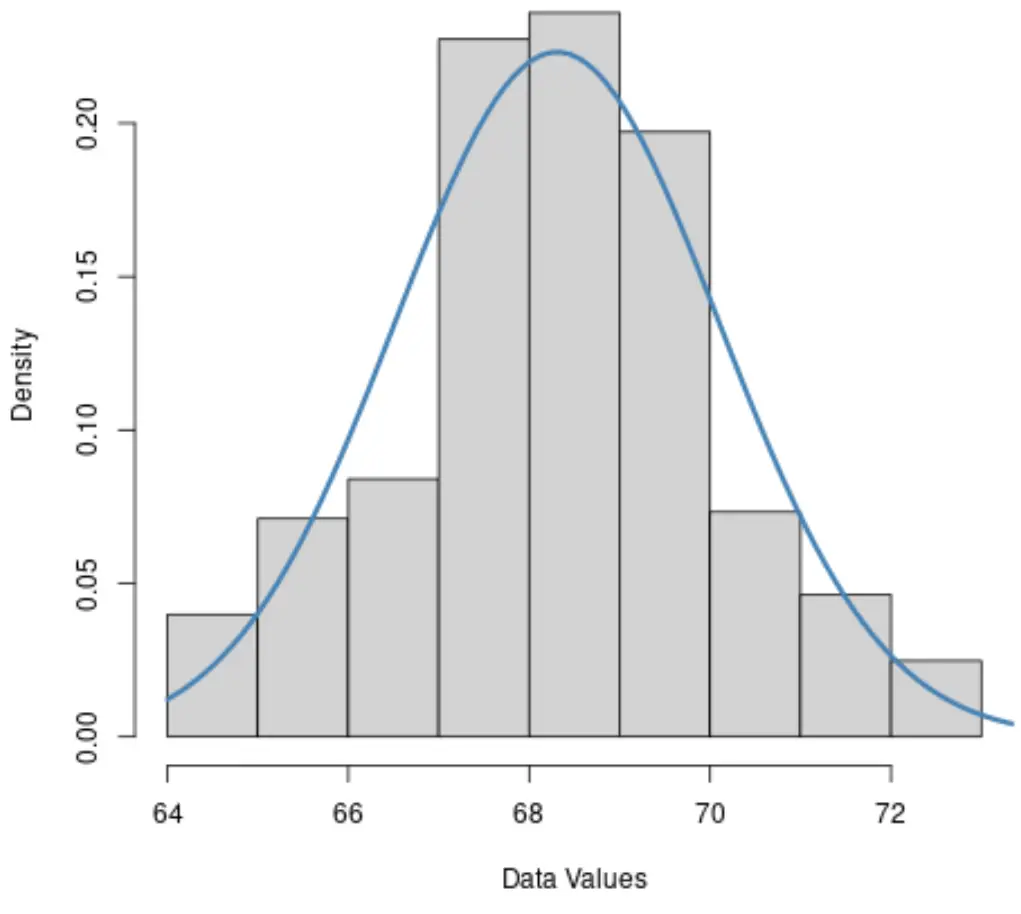
2. QQLand
Een QQ-plot, een afkorting van ‚quantile-quantile‘, is een type plot dat theoretische kwantielen langs de x-as weergeeft (dat wil zeggen waar uw gegevens zich zouden bevinden als deze een normale verdeling zouden volgen) en kwantielen van monsters langs de y-as. (dwz waar uw gegevens zich daadwerkelijk bevinden).
Als de gegevenswaarden een min of meer rechte lijn volgen die een hoek van 45 graden vormt, wordt aangenomen dat de gegevens normaal verdeeld zijn.
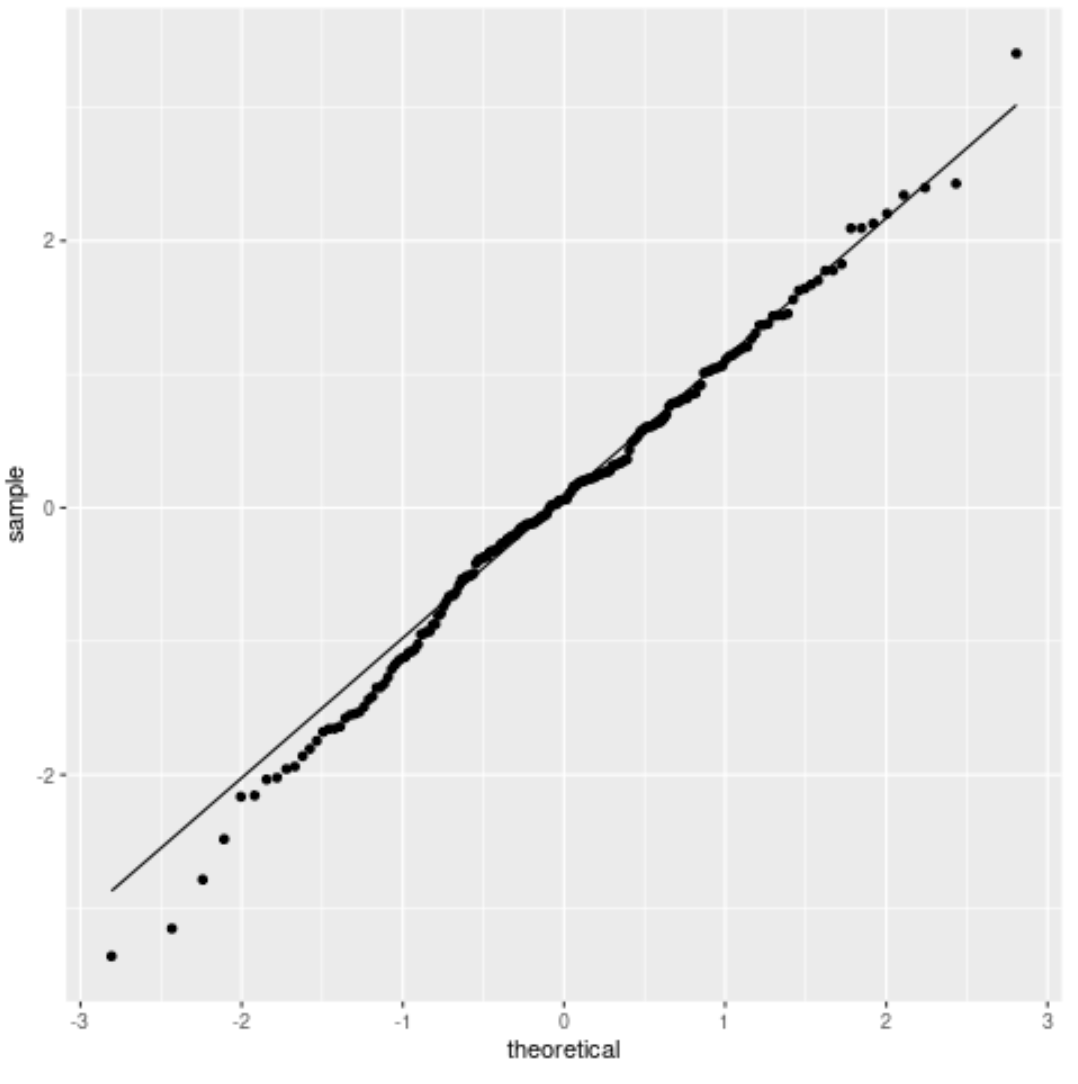
Voer een formele statistische test uit
U kunt ook een formele statistische test uitvoeren om te bepalen of een dataset normaal verdeeld is.
Als de p-waarde van de test onder een bepaald significantieniveau ligt (zoals α = 0,05), dan heb je voldoende bewijs om te zeggen dat de gegevens niet normaal verdeeld zijn.
Er zijn drie statistische tests die vaak worden gebruikt om de normaliteit te testen:
1. De Jarque-Bera-test
- Hoe u een Jarque-Bera-test uitvoert in Excel
- Een Jarque-Bera-test uitvoeren in R
- Hoe u een Jarque-Bera-test uitvoert in Python
2. De Shapiro-Wilk-test
3. De Kolmogorov-Smirnov-test
- Hoe u een Kolmogorov-Smirnov-test uitvoert in Excel
- Hoe een Kolmogorov-Smirnov-test uit te voeren in R
- Hoe u een Kolmogorov-Smirnov-test uitvoert in Python
Wat te doen als de aanname van normaliteit wordt geschonden
Als blijkt dat uw gegevens niet normaal verdeeld zijn, heeft u twee opties:
1. Transformeer de gegevens.
Eén optie is om de gegevens eenvoudigweg te transformeren , zodat deze normaler verdeeld zijn. Veel voorkomende transformaties zijn onder meer:
- Logboektransformatie: transformeer gegevens van y naar log(y) .
- Vierkantsworteltransformatie: transformeer gegevens van y naar √y
- Derdemachtsworteltransformatie: gegevens transformeren van y naar y 1/3
- Box-Cox-transformatie: Transformeer gegevens met behulp van een Box-Cox-procedure
Door deze transformaties uit te voeren wordt de verdeling van datawaarden over het algemeen normaler verdeeld.
2. Voer een niet-parametrische test uit
Statistische tests die uitgaan van normaliteit worden parametrische tests genoemd. Maar er is ook een familie van zogenaamde niet-parametrische tests die deze veronderstelling van normaliteit niet hanteren.
Als blijkt dat uw gegevens niet normaal verdeeld zijn, kunt u eenvoudig een niet-parametrische test uitvoeren. Hier zijn enkele niet-parametrische versies van veelgebruikte statistische tests:
| Parametrisch testen | Niet-parametrisch equivalent |
|---|---|
| Een voorbeeld-t-test | Een voorbeeld van een door Wilcoxon ondertekende rangtest |
| T-test met twee steekproeven | Mann-Whitney U-test |
| Gepaarde monsters t-test | Twee monsters van Wilcoxon ondertekenden een rangtest |
| ANOVA in één richting | Kruskal-Wallis-test |
Elk van deze niet-parametrische tests maakt het mogelijk een statistische test uit te voeren zonder aan de normaliteitsaanname te voldoen.
Aanvullende bronnen
De vier hypothesen geformuleerd in een T-test
De vier aannames van lineaire regressie
De vier hypothesen van ANOVA
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder