Niet-gegroepeerde frequentieverdeling: definitie en voorbeeld
Stel dat we een enquête houden waarbij we aan 15 huishoudens vragen hoeveel dieren ze in huis hebben. De resultaten zijn als volgt:
1, 1, 1, 1, 2, 2, 2, 3, 3, 4, 5, 5, 6, 7, 8
Eén manier om deze resultaten samen te vatten is door een frequentieverdeling te creëren, die ons vertelt hoe vaak verschillende waarden in een dataset voorkomen.
We maken vaak gebruik van geclusterde frequentieverdelingen , waarbij we groepen waarden creëren en vervolgens het aantal observaties in een dataset samenvatten die in die groepen vallen.
Hier is een voorbeeld van een gegroepeerde frequentieverdeling voor onze onderzoeksgegevens:
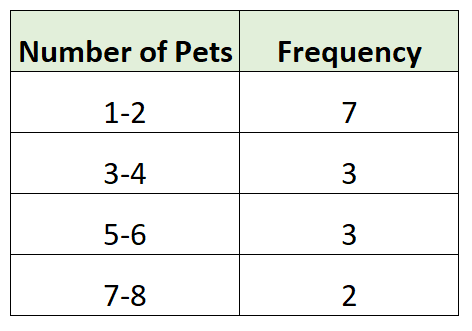
We hebben eerst groepen van grootte 2 gemaakt en vervolgens het aantal individuele waarnemingen uit de dataset geteld dat in elke groep viel. Bijvoorbeeld:
- 7 gezinnen hadden 1 of 2 dieren
- 3 gezinnen hadden 3 of 4 dieren
- 3 gezinnen hadden 5 of 6 dieren
- 2 gezinnen hadden 7 of 8 dieren
Een ander type frequentieverdeling dat we kunnen creëren is een niet-gegroepeerde frequentieverdeling , die de frequentie van elke individuele gegevenswaarde weergeeft in plaats van groepen gegevenswaarden.
Hier is een voorbeeld van een niet-geclusterde frequentieverdeling voor onze onderzoeksgegevens:
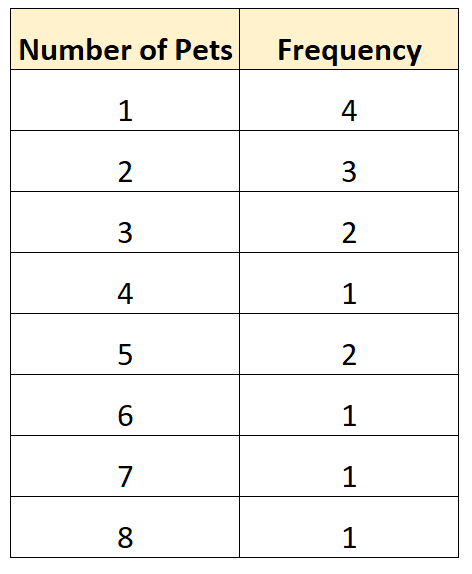
Met dit type frequentieverdeling kunnen we direct zien hoe vaak verschillende waarden in onze dataset voorkomen. Bijvoorbeeld:
- 4 gezinnen hadden 1 dier
- 3 gezinnen hadden 2 dieren
- 2 gezinnen hadden 3 dieren
- 1 gezin had 4 dieren
Enzovoort.
Wanneer moet u niet-gegroepeerde frequentieverdelingen gebruiken?
Niet-gegroepeerde frequentieverdelingen kunnen handig zijn als u wilt zien hoe vaak elke afzonderlijke waarde in een gegevensset voorkomt.
Houd er rekening mee dat niet-geclusterde frequentieverdelingen het beste werken met kleine gegevenssets waarin slechts enkele unieke waarden voorkomen.
In onze vorige onderzoeksgegevens waren er bijvoorbeeld slechts acht unieke waarden, dus het was logisch om een niet-geclusterde frequentieverdeling te creëren.
Als we echter een gegevensset van duizenden zouden hebben met honderden of unieke waarden, zou een niet-geclusterde frequentieverdeling ongelooflijk tijdrovend zijn en moeilijk om informatie uit te verzamelen.
Voor grotere datasets is het zinvol om gegroepeerde frequentieverdelingen te construeren.
Hoe ongegroepeerde frequentieverdelingen te visualiseren
De eenvoudigste manier om de waarden in een niet-gegroepeerde frequentieverdeling te visualiseren, is door een frequentiepolygoon te maken, die de frequenties van elke individuele waarde in een eenvoudige grafiek weergeeft.
Hier ziet u hoe een frequentiepolygoon eruit zou zien voor onze voorbeeldgegevens:
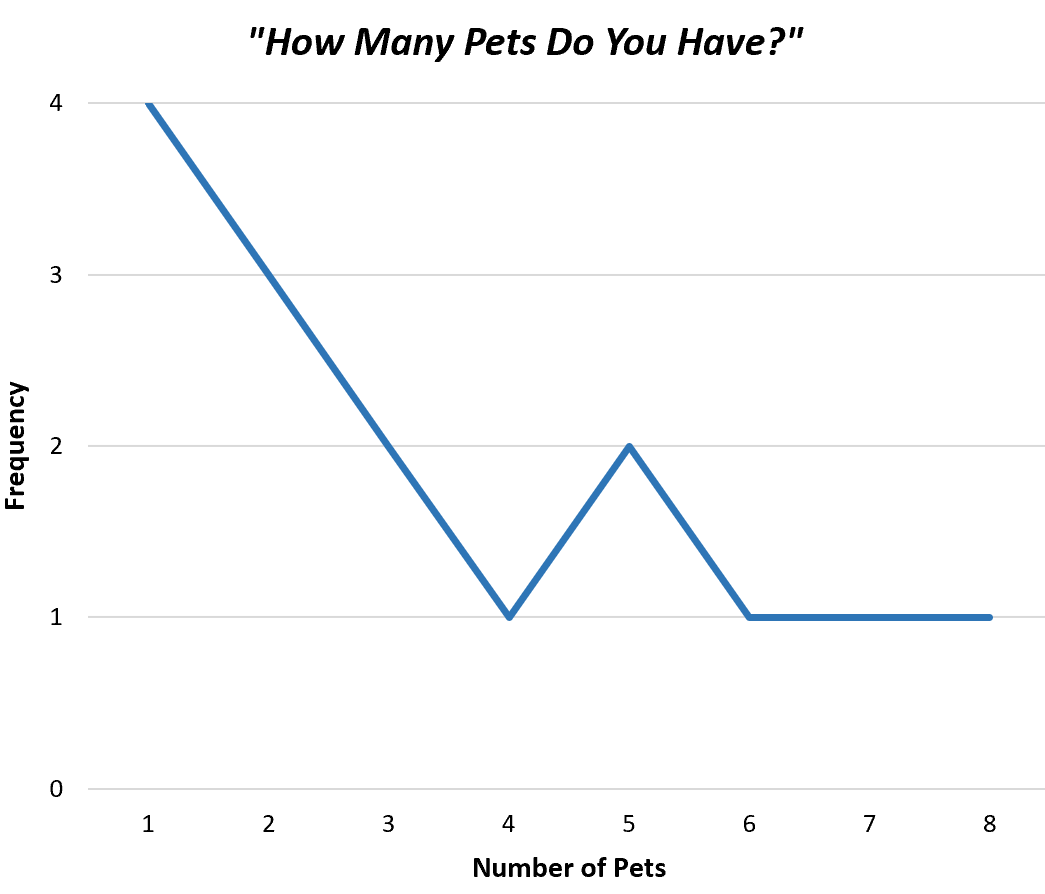
Hierdoor kunnen we snel begrijpen hoe vaak elke waarde in de dataset voorkomt.
Als alternatief kunnen we een staafdiagram maken om exact dezelfde gegevens weer te geven met behulp van staven in plaats van een enkele lijn:
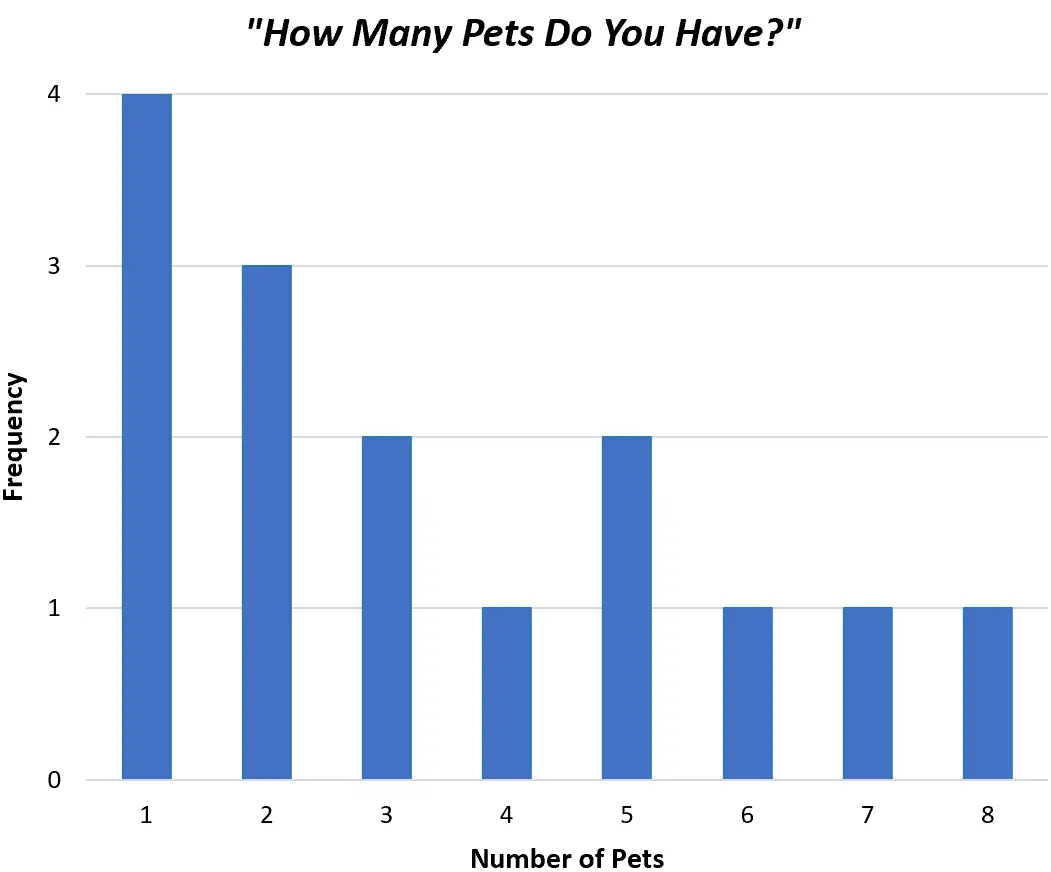
Met beide grafieken kunnen we snel de verdeling van waarden in onze dataset begrijpen.
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder