Wat is een open distributie?
In de statistieken is een open distributie een frequentieverdeling waarin een of meer klassen (of „bakken“) open zijn.
De volgende frequentieverdeling vertegenwoordigt bijvoorbeeld een open verdeling waarin de kleinste klasse open is:
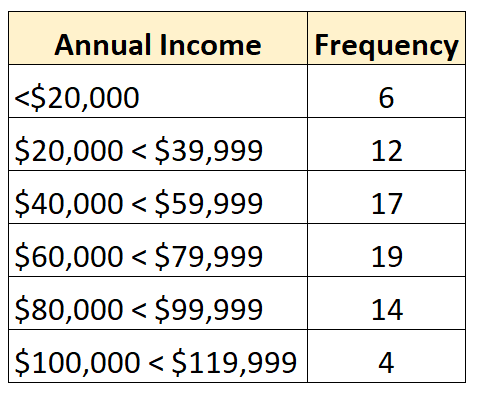
En de volgende frequentieverdeling laat een open verdeling zien waarbij de grootste klasse open is:
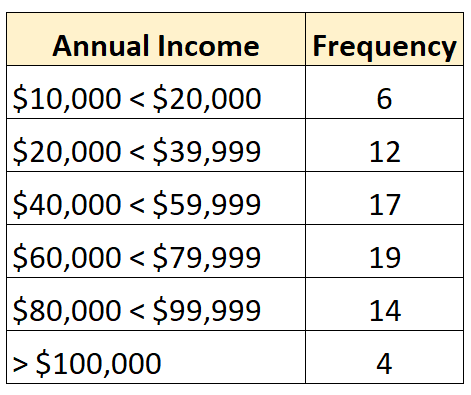
Omgekeerd is een gesloten distributie er een waarin elke klasse van de frequentieverdeling een boven- en ondergrens heeft, zoals de volgende:
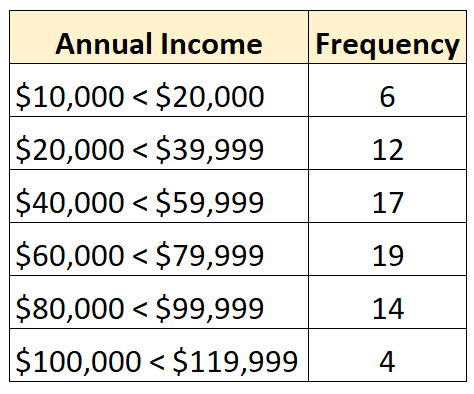
Wat veroorzaakt open distributies?
Open distributies zijn vaak het gevolg van het feit dat onderzoekers ervoor kiezen om data op zo’n manier te verzamelen dat een van de klassen uiteindelijk open is.
Stel bijvoorbeeld dat een onderzoeker inwoners van een bepaalde stad ondervraagt en hen vraagt naar hun jaarlijkse gezinsinkomen.
De onderzoeker kan ervoor kiezen om het breedst mogelijke antwoord van „>€100.000“ te geven, omdat hij of zij weet dat inwoners met een hoog inkomen het misschien niet prettig vinden om te delen hoeveel ze verdienen als dit aanzienlijk hoger is dan $100.000.
Omgekeerd kan de onderzoeker ervoor kiezen om het kortst mogelijke antwoord te geven, omdat hij of zij weet dat bewoners die heel weinig verdienen het ook niet prettig zullen vinden om het weinige dat ze verdienen te delen.
Kort gezegd nemen onderzoekers vaak open cursussen op in hun enquêtes, omdat ze het aantal mensen willen maximaliseren dat zich op hun gemak voelt bij het beantwoorden van enquêtevragen.
Het probleem met open distributies
Het probleem met open distributies is dat de echte gegevens worden gecensureerd . Met andere woorden: we kunnen het aantal mensen kennen dat in een bepaalde stad meer dan $100.000 verdient, maar we weten eigenlijk niet wat hun exacte jaarinkomen is.
Het is mogelijk dat sommige mensen $150.000, $250.000, $500.000 of zelfs meer verdienen, maar we hebben geen idee, aangezien elk van deze mensen in het onderzoek niet kan aangeven dat ze „>$100.000“ verdienen.
Omdat de gegevens in de open distributies worden gecensureerd, kunnen we ook niet het exacte gemiddelde en de standaardafwijking van de waarden in de dataset berekenen, omdat we geen toegang hebben tot alle waarden in de onbewerkte gegevens.
Hoe een open distributie te analyseren
Omdat we het exacte gemiddelde van een open verdeling niet kunnen berekenen, gebruiken we vaak de mediaan als maatstaf voor het ‘centrum’ van de dataset.
Bedenk dat de mediaan de middelste waarde van de dataset vertegenwoordigt.
Wanneer we met open verdelingen werken, kunnen we de volgende formule gebruiken om de beste schatting van de mediaan te vinden:
Beste schatting van de mediaan: L + ((n/2 – F) / f) * w
Goud:
- L: De ondergrens van de middengroep
- n: Het totale aantal waarnemingen
- F: De cumulatieve frequentie tot aan de middengroep
- f: De frequentie van de middengroep
- w: De breedte van de middelste groep
Stel dat we bijvoorbeeld de volgende open distributie hebben:
Er zijn in totaal 72 waarden in de dataset. We weten dus dat de mediaanwaarde tussen de 36e en 37e grootste waarden in de dataset zal liggen. Elk van deze waarden valt in de klasse ‘€60.000 – €79.999’, dus we weten dat het mediaaninkomen binnen dat bereik ligt.
Onze beste schatting van de mediaan zou zijn:
Mediaan: 60.000 + ((72/2 – 25) / 19) * 19.999 = $71.578
Deze waarde vertegenwoordigt onze beste schatting van het gemiddelde jaarinkomen van individuen in deze dataset.
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder