Hoe u een puntenwolk kunt maken op basis van een pandas dataframe
Er zijn twee manieren om een puntenwolk te maken met behulp van gegevens uit een Panda DataFrame:
1. Gebruik pandas.DataFrame.plot.scatter
Eén manier om een spreidingsdiagram te maken is door de ingebouwde functie plot.scatter() van panda’s te gebruiken:
import pandas as pd df. plot . scatter (x = ' x_column_name ', y = ' y_columnn_name ')
2. Gebruik matplotlib.pyplot.scatter
Een andere manier om een spreidingsdiagram te maken is door de Matplotlib pyplot.scatter() functie te gebruiken:
import matplotlib. pyplot as plt plt. scatter (df.x, df.y)
Deze zelfstudie geeft een voorbeeld van het gebruik van elk van deze methoden.
Voorbeeld 1: panda’s gebruiken
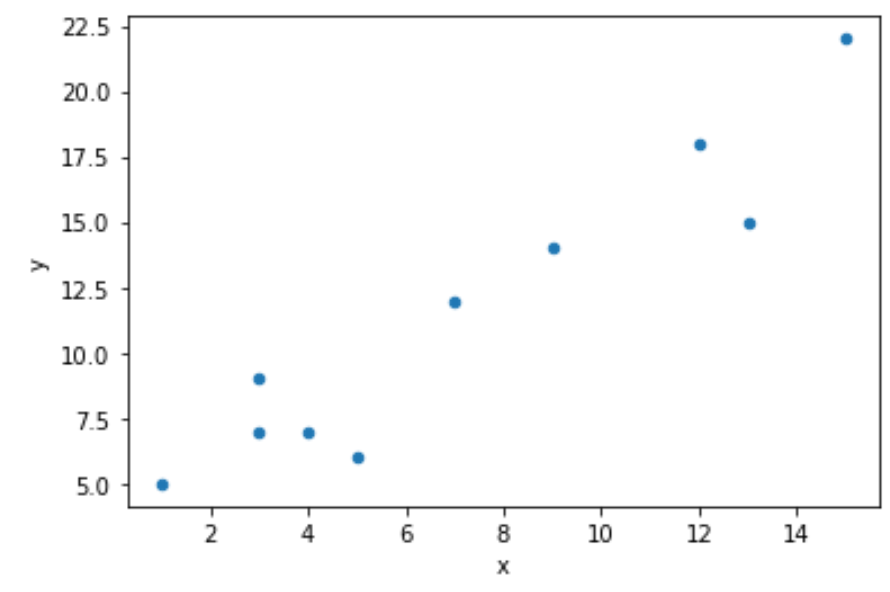
De volgende code laat zien hoe u de functie plot.scatter() gebruikt om een eenvoudig spreidingsdiagram te maken:
import pandas as pd #createDataFrame df = pd. DataFrame ({'x': [1, 3, 3, 4, 5, 7, 9, 12, 13, 15], 'y': [5, 7, 9, 7, 6, 12, 14, 18, 15, 22]}) #create scatterplot df. plot . scatter (x=' x ', y=' y ')
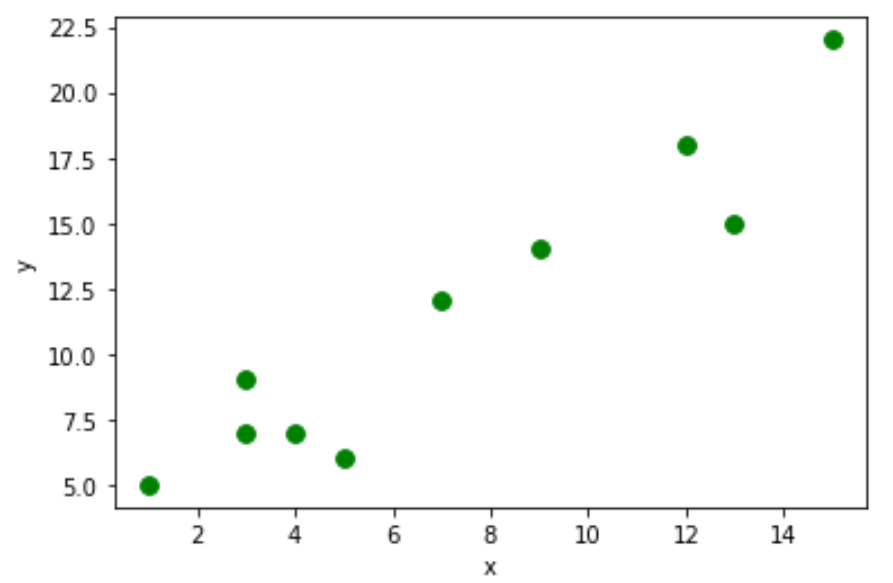
Merk op dat u de argumenten s en c kunt gebruiken om respectievelijk de grootte en kleur van de punten te wijzigen:
df. plot . scatter (x=' x ', y=' y ', s= 60 , c=' green ')
Voorbeeld 2: Matplotlib gebruiken
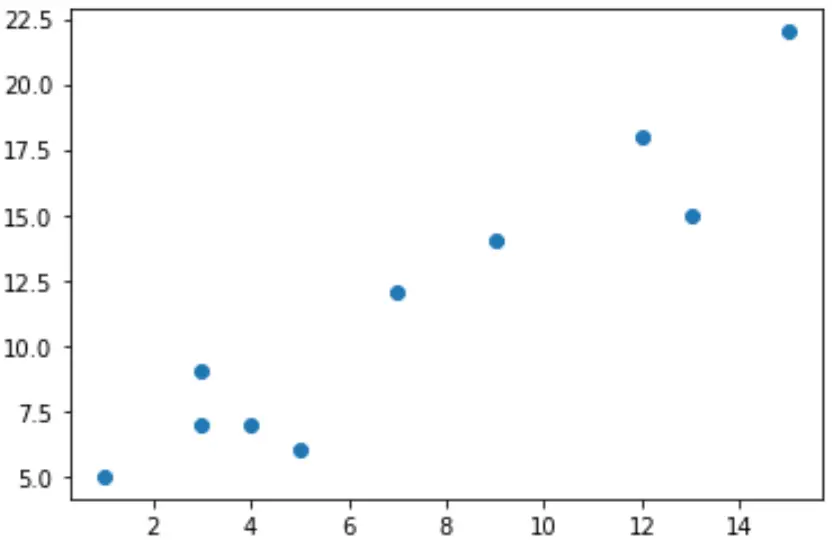
De volgende code laat zien hoe u de functie pyplot.scatter() gebruikt om een spreidingsdiagram te maken:
import pandas as pd import matplotlib. pyplot as plt #createDataFrame df = pd. DataFrame ({'x': [1, 3, 3, 4, 5, 7, 9, 12, 13, 15], 'y': [5, 7, 9, 7, 6, 12, 14, 18, 15, 22]}) #create scatterplot plt. scatter (df.x, df.y)
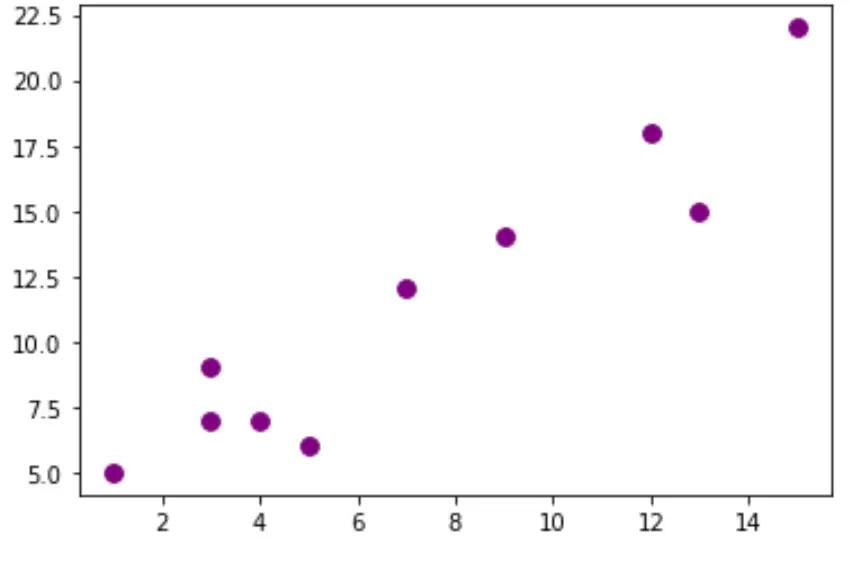
Merk op dat u de argumenten s en c kunt gebruiken om respectievelijk de grootte en kleur van de punten te wijzigen:
plt. scatter (df.x, df.y, s= 60 , c=' purple ')
Meer Python-tutorials vind je hier .
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder