Panda's: importeer csv met een verschillend aantal kolommen per rij
U kunt de volgende basissyntaxis gebruiken om een CSV-bestand in panda’s te importeren als er een verschillend aantal kolommen per rij is:
df = pd. read_csv (' uneven_data.csv ', header= None , names=range( 4 ))
De waarde binnen de functie range() moet het aantal kolommen in de rij met het maximale aantal kolommen zijn.
Het volgende voorbeeld laat zien hoe u deze syntaxis in de praktijk kunt gebruiken.
Voorbeeld: importeer CSV in Panda’s met een verschillend aantal kolommen per rij
Laten we zeggen dat we het volgende CSV-bestand hebben met de naam ongelijke_data.csv :
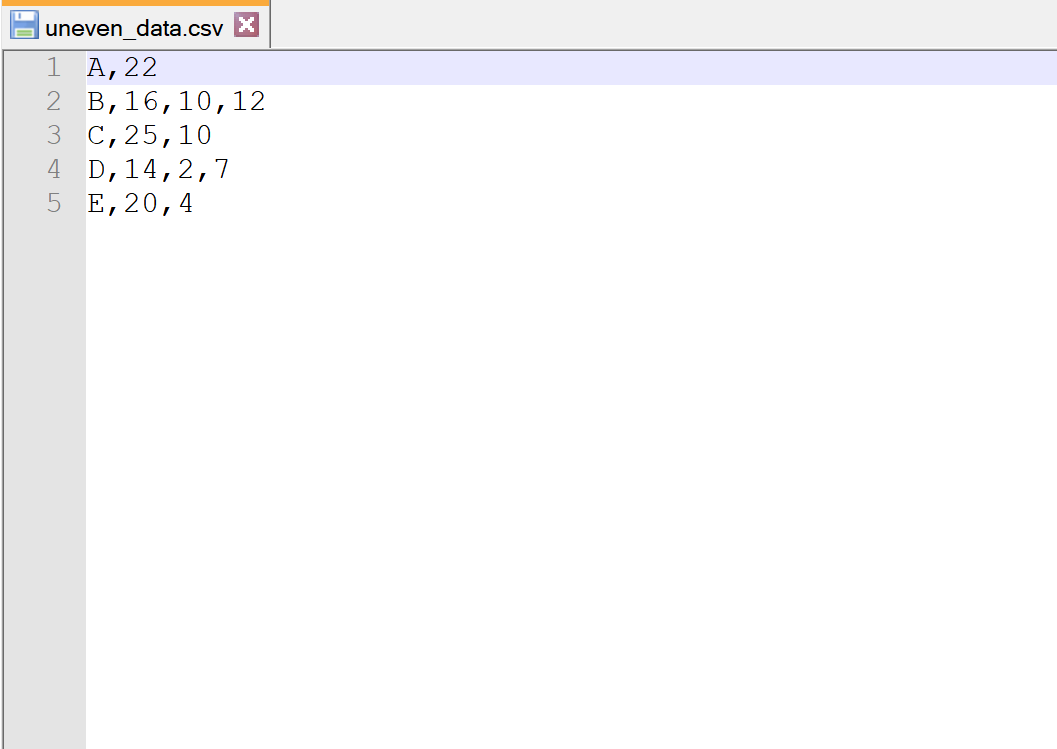
Houd er rekening mee dat elke rij niet hetzelfde aantal kolommen heeft.
Als we de functie read_csv() proberen te gebruiken om dit CSV-bestand in een Panda DataFrame te importeren, krijgen we een foutmelding:
import pandas as pd #attempt to import CSV file with differing number of columns per row df = pd. read_csv (' uneven_data.csv ', header= None ) ParserError: Error tokenizing data. C error: Expected 2 fields in line 2, saw 4
We ontvangen een ParserError die ons vertelt dat Panda’s 2 velden verwachtten (aangezien dat het aantal kolommen in de eerste rij was), maar er 4 zag.
Deze fout vertelt ons dat het maximale aantal kolommen in een bepaalde rij 4 is.
We kunnen dus het CSV-bestand importeren en een waarde van range(4) opgeven voor het argument namen :
import pandas as pd #import CSV file with differing number of columns per row df = pd. read_csv (' uneven_data.csv ', header= None , names=range( 4 ))) #view DataFrame print (df) 0 1 2 3 0 to 22 NaN NaN 1 B 16 10.0 12.0 2 C 25 10.0 NaN 3 D 14 2.0 7.0 4 E 20 4.0 NaN
Houd er rekening mee dat we het CSV-bestand zonder fouten in een Panda DataFrame kunnen importeren, omdat we Panda’s expliciet hebben verteld dat ze 4 kolommen mogen verwachten.
Standaard vult panda’s alle ontbrekende waarden in elke rij met NaN.
Als je ontbrekende waarden als nul wilt weergeven, kun je de functie fillna() als volgt gebruiken:
#fill NaN values with zeros df_new = df. fillna ( 0 ) #view new DataFrame print (df_new) 0 1 2 3 0 to 22 0.0 0.0 1 B 16 10.0 12.0 2 C 25 10.0 0.0 3 D 14 2.0 7.0 4 E 20 4.0 0.0
Elke NaN-waarde in het DataFrame is nu vervangen door een nul.
Opmerking : u kunt de volledige documentatie van de pandas read_csv() functie hier vinden.
Aanvullende bronnen
In de volgende tutorials wordt uitgelegd hoe u andere veelvoorkomende taken in Python kunt uitvoeren:
Panda’s: regels overslaan bij het lezen van een CSV-bestand
Panda’s: gegevens toevoegen aan een bestaand CSV-bestand
Panda’s: typen opgeven bij het importeren van een CSV-bestand
Panda’s: stel kolomnamen in bij het importeren van een CSV-bestand
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder