Hoe u de verdeling van kolomwaarden in panda's kunt plotten
U kunt de volgende methoden gebruiken om een verdeling van kolomwaarden in een Panda DataFrame te plotten:
Methode 1: Zet de verdeling van waarden in een kolom
df[' my_column ']. plot (kind=' kde ')
Methode 2: Teken de verdeling van waarden in één kolom, gegroepeerd in een andere kolom
df. groupby (' group_column ')[' values_column ']. plot (kind=' kde ')
De volgende voorbeelden laten zien hoe u elke methode in de praktijk kunt gebruiken met de volgende panda’s DataFrame:
import pandas as pd #createDataFrame df = pd. DataFrame ({' team ': ['A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B'], ' points ': [3, 3, 4, 5, 4, 7, 7, 7, 10, 11, 8, 7, 8, 9, 12, 12, 12, 14, 15, 17]}) #view DataFrame print (df) team points 0 to 3 1 to 3 2 to 4 3 to 5 4 to 4 5 TO 7 6 to 7 7 to 7 8 to 10 9 to 11 10 B 8 11 B 7 12 B 8 13 B 9 14 B 12 15 B 12 16 B 12 17 B 14 18 B 15 19 B 17
Voorbeeld 1: Zet de verdeling van waarden in een kolom
De volgende code laat zien hoe u de verdeling van waarden in de puntenkolom kunt plotten:
#plot distribution of values in points column df[' points ']. plot (kind=' kde ')
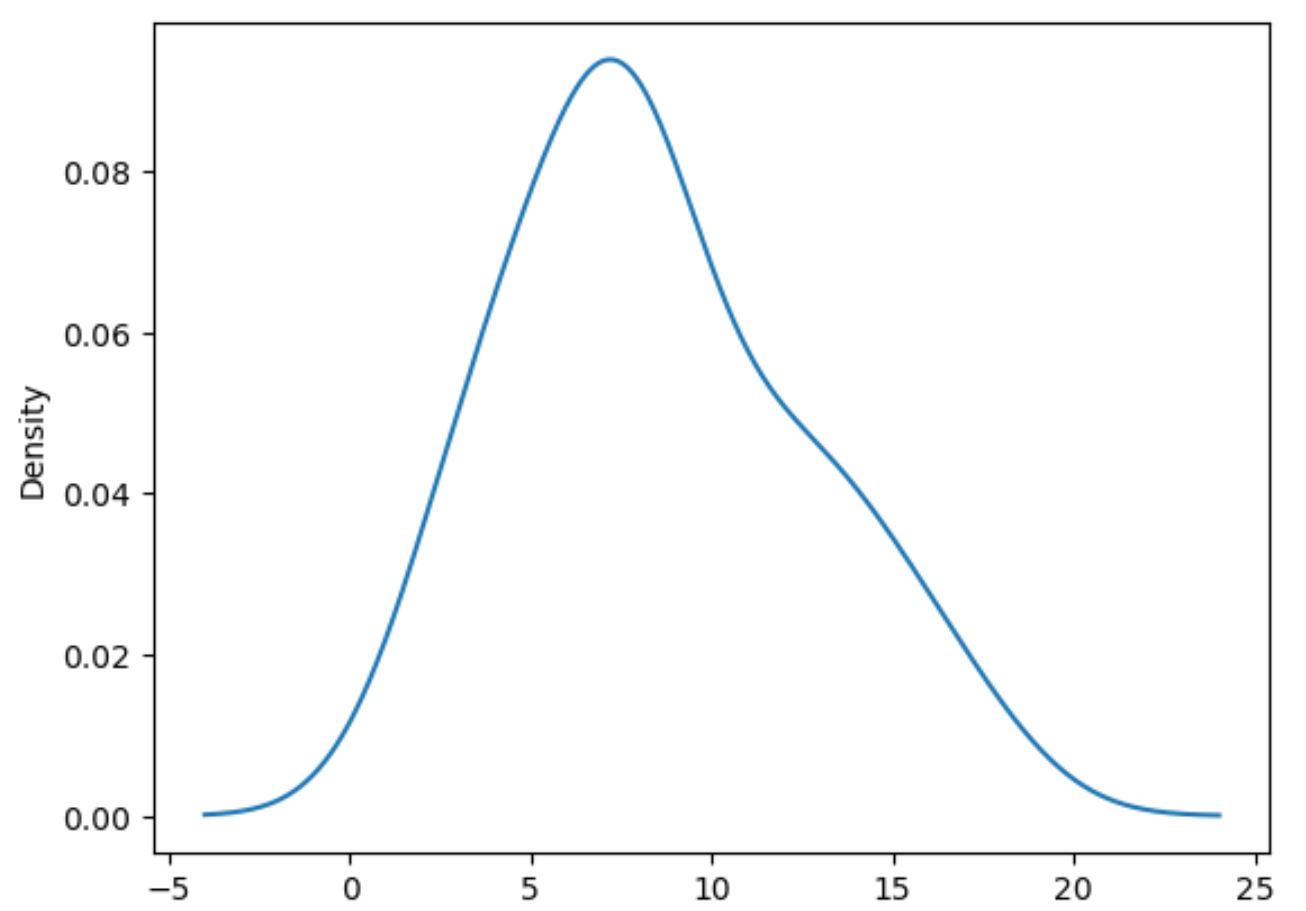
Merk op dat kind=’kde‘ panda’s vertelt om kernel density estimation te gebruiken, wat een vloeiende curve oplevert die de verdeling van de waarden van een variabele samenvat.
Als u in plaats daarvan een histogram wilt maken, kunt u kind=’hist‘ als volgt opgeven:
#plot distribution of values in points column using histogram df[' points ']. plot (kind=' hist ', edgecolor=' black ')
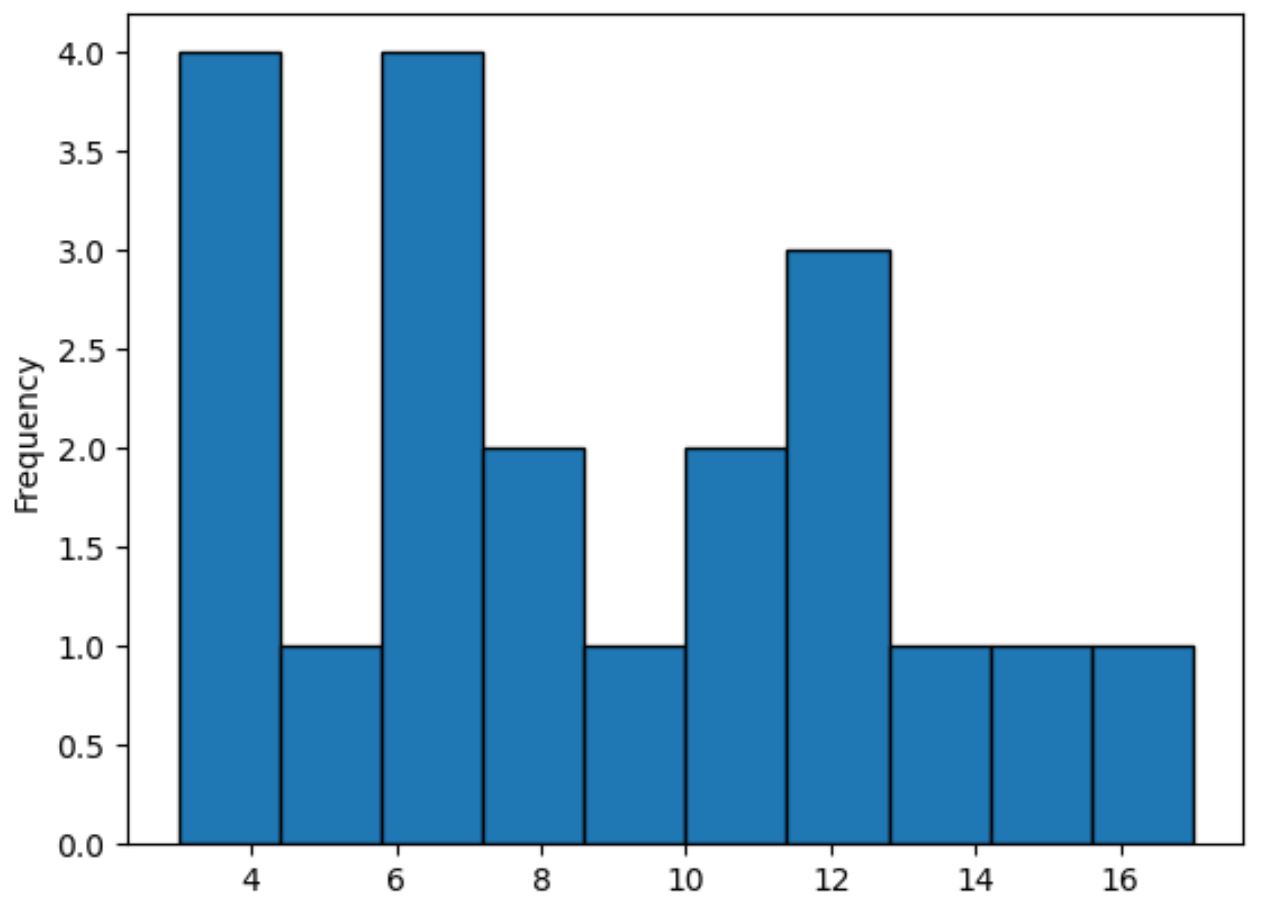
Deze methode maakt gebruik van balken om de frequenties van waarden in de kolom met punten weer te geven, in tegenstelling tot een vloeiende lijn die de vorm van de verdeling samenvat.
Voorbeeld 2: Teken de verdeling van waarden in één kolom, gegroepeerd in een andere kolom
De volgende code laat zien hoe u de verdeling van waarden in de puntenkolom kunt plotten, gegroepeerd op de teamkolom :
import matplotlib.pyplot as plt #plot distribution of points by team df. groupby (' team ')[' points ']. plot (kind=' kde ') #add legend plt. legend ([' A ',' B '], title=' Team ') #add x-axis label plt. xlabel (' Points ')
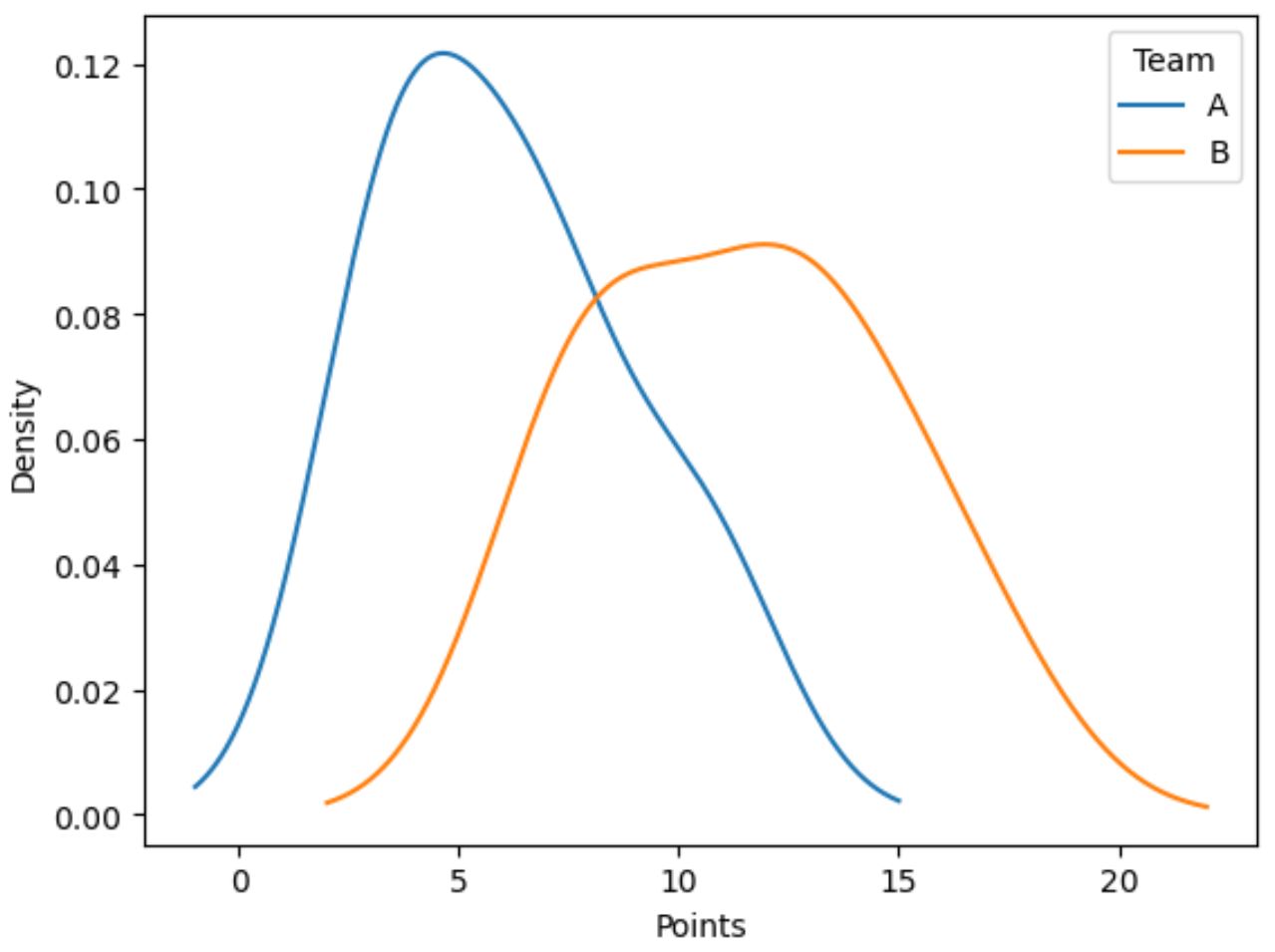
De blauwe lijn toont de puntenverdeling van spelers van team A, terwijl de oranje lijn de puntenverdeling van spelers van team B toont.
Aanvullende bronnen
In de volgende tutorials wordt uitgelegd hoe u andere veelvoorkomende taken in panda’s kunt uitvoeren:
Hoe titels aan plots in Pandas toe te voegen
Hoe u de figuurgrootte van een panda-plot kunt aanpassen
Hoe u meerdere Panda’s DataFrames in subplots kunt plotten
Hoe u plotlegenda’s in Panda’s kunt maken en aanpassen
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder