Panda's gebruiken koop dummies – pd.get_dummies
Vaak bevatten de datasets waarmee we werken in de statistiekcategorische variabelen .
Dit zijn variabelen die namen of labels aannemen. Voorbeelden zijn onder meer:
- Burgerlijke staat (“getrouwd”, “single”, “gescheiden”)
- Rookstatus (“roker”, “niet-roker”)
- Oogkleur (“blauw”, “groen”, “hazelnoot”)
- Opleidingsniveau (bijv. “middelbare school”, “bachelordiploma”, “masterdiploma”)
Bij het afstemmen van machine learning-algoritmen (zoals lineaire regressie , logistische regressie , willekeurige forests , enz.), zetten we categorische variabelen vaak om in dummy-variabelen . Dit zijn numerieke variabelen die worden gebruikt om categorische gegevens weer te geven.
Stel dat we bijvoorbeeld een gegevensset hebben die de categorische variabele Geslacht bevat. Om deze variabele als voorspeller in een regressiemodel te gebruiken, zou het eerst nodig zijn om deze naar een dummyvariabele te converteren.
Om deze dummyvariabele te maken, kunnen we een van de waarden („Male“) kiezen om 0 weer te geven en de andere waarde („Female“) om 1 weer te geven:
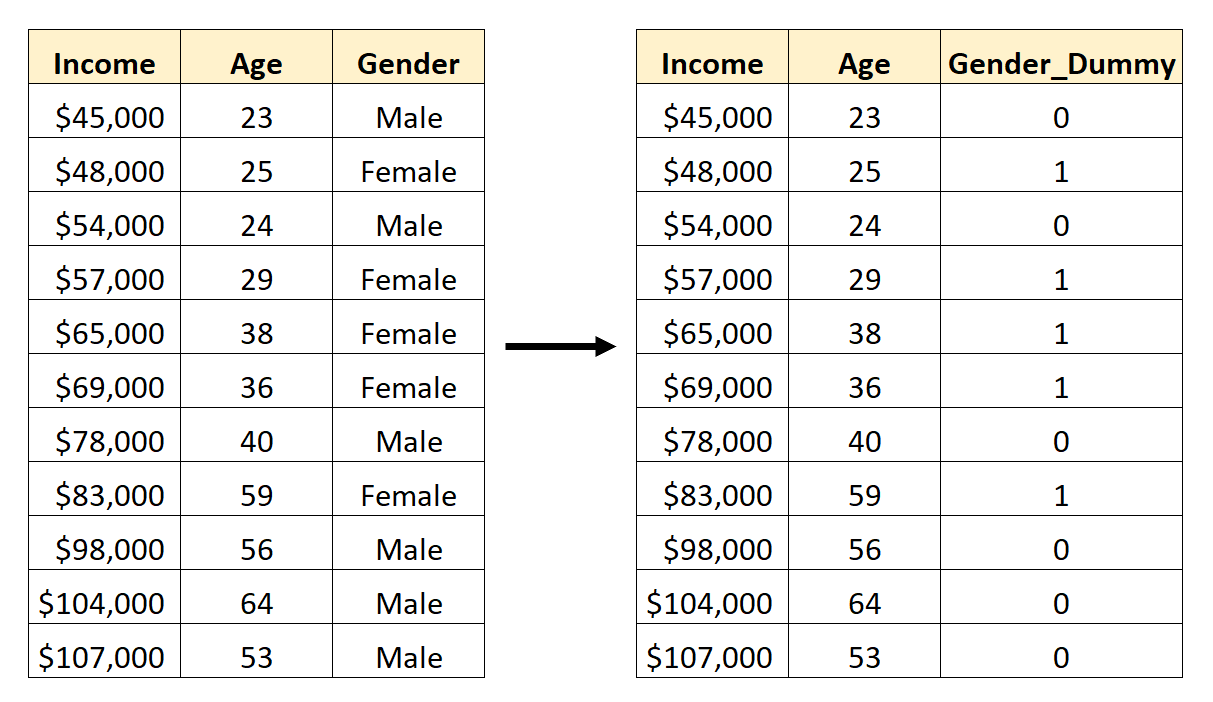
Hoe dummyvariabelen in Panda’s te maken
Om dummies te maken voor een variabele in een pandas DataFrame, kunnen we de functie pandas.get_dummies() gebruiken, die de volgende basissyntaxis gebruikt:
pandas.get_dummies(data, prefix=Geen, kolommen=Geen, drop_first=False)
Goud:
- data : De naam van het panda’s DataFrame
- prefix : een tekenreeks die moet worden toegevoegd aan het begin van de nieuwe dummyvariabelekolom
- kolommen : De naam van de kolom(men) die moet(en) worden omgezet in een dummyvariabele
- drop_first : of de eerste dummy-variabelekolom al dan niet moet worden verwijderd
De volgende voorbeelden laten zien hoe u deze functie in de praktijk kunt gebruiken.
Voorbeeld 1: Maak één dummyvariabele
Stel dat we de volgende panda’s DataFrame hebben:
import pandas as pd #createDataFrame df = pd. DataFrame ({' income ': [45, 48, 54, 57, 65, 69, 78], ' age ': [23, 25, 24, 29, 38, 36, 40], ' gender ': ['M', 'F', 'M', 'F', 'F', 'F', 'M']}) #view DataFrame df income age gender 0 45 23 M 1 48 25 F 2 54 24 M 3 57 29 F 4 65 38 F 5 69 36 F 6 78 40 M
We kunnen de functie pd.get_dummies() gebruiken om het geslacht in een dummyvariabele te veranderen:
#convert gender to dummy variable p.d. get_dummies (df, columns=[' gender '], drop_first= True ) income age gender_M 0 45 23 1 1 48 25 0 2 54 24 1 3 57 29 0 4 65 38 0 5 69 36 0 6 78 40 1
De geslachtskolom is nu een dummyvariabele waarbij:
- Een waarde van 0 staat voor ‘Vrouw’
- Een waarde van 1 staat voor “Man”
Voorbeeld 2: Maak meerdere dummyvariabelen
Stel dat we de volgende panda’s DataFrame hebben:
import pandas as pd #createDataFrame df = pd. DataFrame ({' income ': [45, 48, 54, 57, 65, 69, 78], ' age ': [23, 25, 24, 29, 38, 36, 40], ' gender ': ['M', 'F', 'M', 'F', 'F', 'F', 'M'], ' college ': ['Y', 'N', 'N', 'N', 'Y', 'Y', 'Y']}) #view DataFrame df income age gender college 0 45 23 M Y 1 48 25 F N 2 54 24 M N 3 57 29 F N 4 65 38 F Y 5 69 36 F Y 6 78 40 M Y
We kunnen de functie pd.get_dummies() gebruiken om geslacht en universiteit om te zetten in dummyvariabelen:
#convert gender to dummy variable p.d. get_dummies (df, columns=[' gender ', ' college '], drop_first= True ) income age gender_M college_Y 0 45 23 1 1 1 48 25 0 0 2 54 24 1 0 3 57 29 0 0 4 65 38 0 1 5 69 36 0 1 6 78 40 1 1
De geslachtskolom is nu een dummyvariabele waarbij:
- Een waarde van 0 staat voor ‘Vrouw’
- Een waarde van 1 staat voor “Man”
En de college-kolom is nu een dummyvariabele waarin:
- Een waarde van 0 staat voor “Nee” universiteit
- Een waarde van 1 staat voor “Ja” tegen de universiteit
Aanvullende bronnen
Hoe dummyvariabelen te gebruiken in regressieanalyse
Wat is de dummy-variabeleval?
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder