Hoe polynomiale regressie uit te voeren in python
Regressieanalyse wordt gebruikt om de relatie tussen een of meer verklarende variabelen en een responsvariabele te kwantificeren.
Het meest voorkomende type regressieanalyse iseenvoudige lineaire regressie , die wordt gebruikt wanneer een voorspellende variabele en een responsvariabele een lineair verband hebben.

Soms is de relatie tussen een voorspellende variabele en een responsvariabele echter niet-lineair.
De ware relatie kan bijvoorbeeld kwadratisch zijn:
Of het kan kubisch zijn:

In deze gevallen is het zinvol om polynomiale regressie te gebruiken, die de niet-lineaire relatie tussen variabelen kan verklaren.
In deze tutorial wordt uitgelegd hoe u polynomiale regressie in Python uitvoert.
Voorbeeld: polynomiale regressie in Python
Stel dat we de volgende voorspellende variabele (x) en responsvariabele (y) hebben in Python:
x = [2, 3, 4, 5, 6, 7, 7, 8, 9, 11, 12] y = [18, 16, 15, 17, 20, 23, 25, 28, 31, 30, 29]
Als we een eenvoudig spreidingsdiagram van deze gegevens maken, kunnen we zien dat de relatie tussen x en y duidelijk niet lineair is:
import matplotlib.pyplot as plt #create scatterplot plt.scatter(x, y)
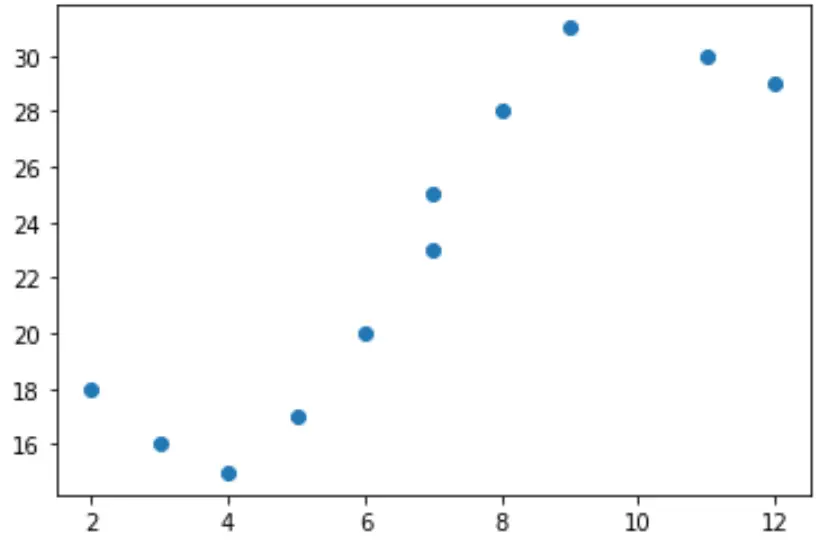
Het zou daarom geen zin hebben om een lineair regressiemodel op deze gegevens toe te passen. In plaats daarvan kunnen we proberen een polynoomregressiemodel met graad 3 te fitten met behulp van de numpy.polyfit() functie:
import numpy as np #polynomial fit with degree = 3 model = np.poly1d(np.polyfit(x, y, 3)) #add fitted polynomial line to scatterplot polyline = np.linspace(1, 12, 50) plt.scatter(x, y) plt.plot(polyline, model(polyline)) plt.show()
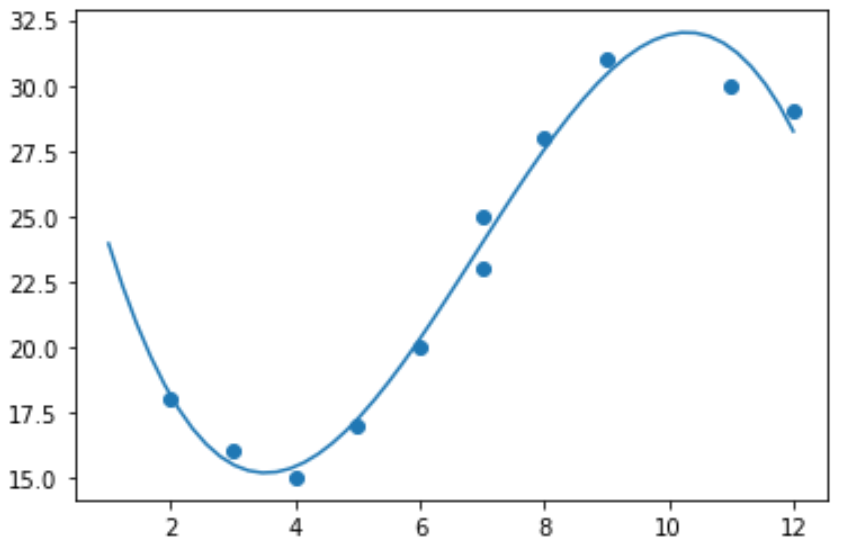
We kunnen de gepaste polynomiale regressievergelijking verkrijgen door de modelcoëfficiënten af te drukken:
print(model) poly1d([ -0.10889554, 2.25592957, -11.83877127, 33.62640038])
De aangepaste polynomiale regressievergelijking is:
y = -0,109x 3 + 2,256x 2 – 11,839x + 33,626
Deze vergelijking kan worden gebruikt om de verwachte waarde van de responsvariabele te vinden, gegeven een gegeven waarde van de verklarende variabele.
Stel bijvoorbeeld dat x = 4. De verwachte waarde voor de responsvariabele, y, zou zijn:
y = -0,109(4) 3 + 2,256(4) 2 – 11,839(4) + 33,626= 15,39 .
We kunnen ook een korte functie schrijven om het R-kwadraat van het model te verkrijgen, wat het deel van de variantie in de responsvariabele is dat kan worden verklaard door de voorspellende variabelen.
#define function to calculate r-squared def polyfit(x, y, degree): results = {} coeffs = numpy.polyfit(x, y, degree) p = numpy.poly1d(coeffs) #calculate r-squared yhat = p(x) ybar = numpy.sum(y)/len(y) ssreg = numpy.sum((yhat-ybar)**2) sstot = numpy.sum((y - ybar)**2) results['r_squared'] = ssreg / sstot return results #find r-squared of polynomial model with degree = 3 polyfit(x, y, 3) {'r_squared': 0.9841113454245183}
In dit voorbeeld is het R-kwadraat van het model 0,9841 .
Dit betekent dat 98,41% van de variatie in de responsvariabele kan worden verklaard door de voorspellende variabelen.
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder