Dotplot en histogram: wat is het verschil?
Twee veelgebruikte plots om de verdeling van waarden in een dataset te visualiseren zijn puntplots en histogrammen .
Een puntplot geeft individuele gegevenswaarden weer langs de x-as en gebruikt punten om de frequenties van elke individuele waarde weer te geven.
Een histogram geeft gegevensbereiken weer langs de x-as en gebruikt rechthoekige balken om de frequenties weer te geven van waarden die tot elk bereik behoren.
In het volgende voorbeeld ziet u hoe u een puntendiagram en een histogram voor dezelfde gegevensset maakt.
Voorbeeld: een puntdiagram en histogram maken voor dezelfde gegevensset
Stel dat we de volgende dataset hebben met 18 waarden:
Gegevens: 1, 1, 1, 1, 2, 2, 2, 3, 4, 5, 5, 6, 6, 6, 6, 7, 8, 10
Hier ziet u hoe een puntendiagram voor deze dataset eruit zou zien:
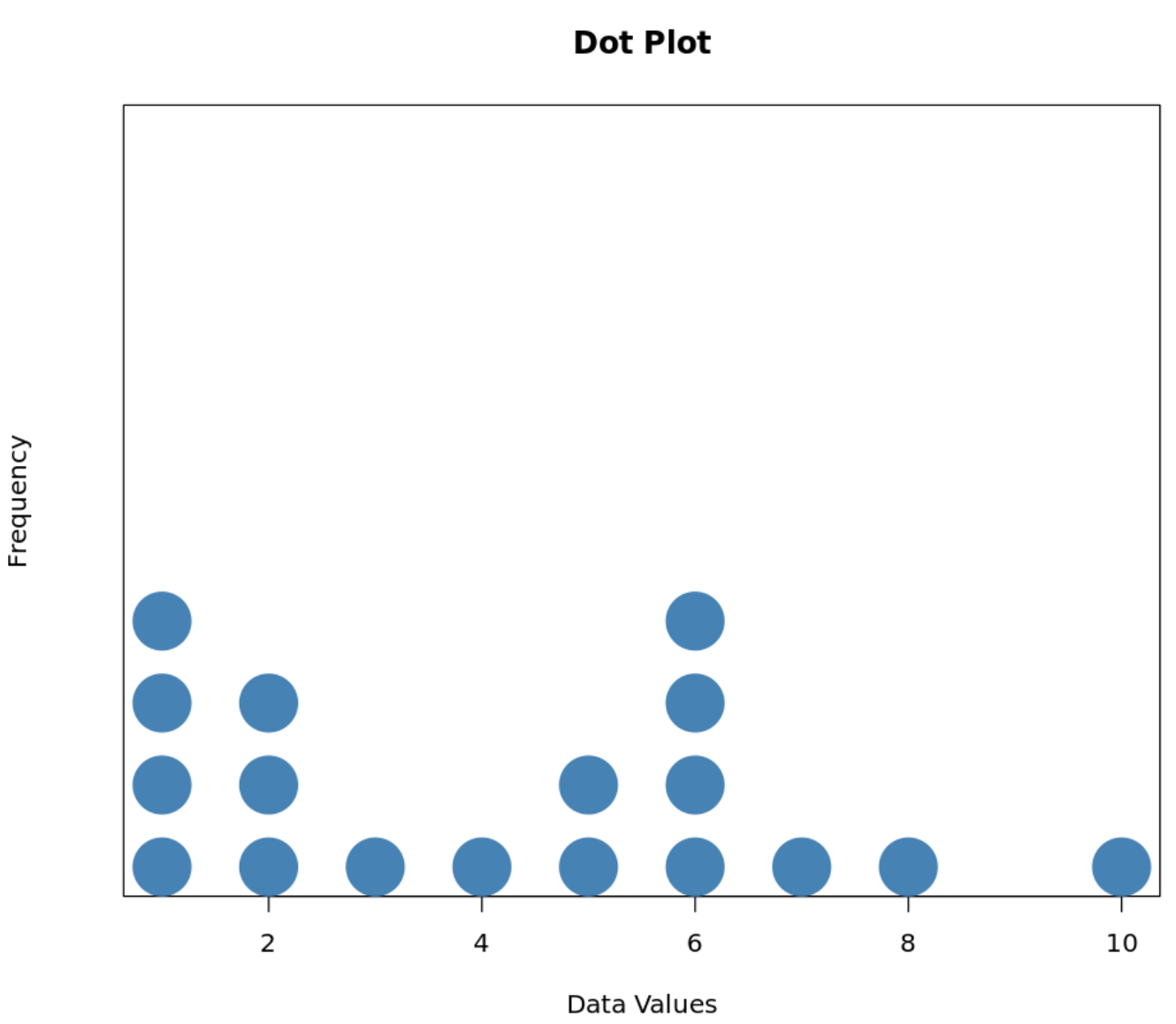
De x-as toont individuele gegevenswaarden en de y-as toont de frequentie van elke waarde.
We kunnen bijvoorbeeld zien dat de waarde „2“ drie keer in de dataset voorkomt, omdat er drie punten boven staan. Op dezelfde manier kunnen we zien dat de waarde „3“ slechts één keer voorkomt omdat er maar één punt erboven staat.
En dit is hoe een histogram voor deze dataset eruit zou zien:
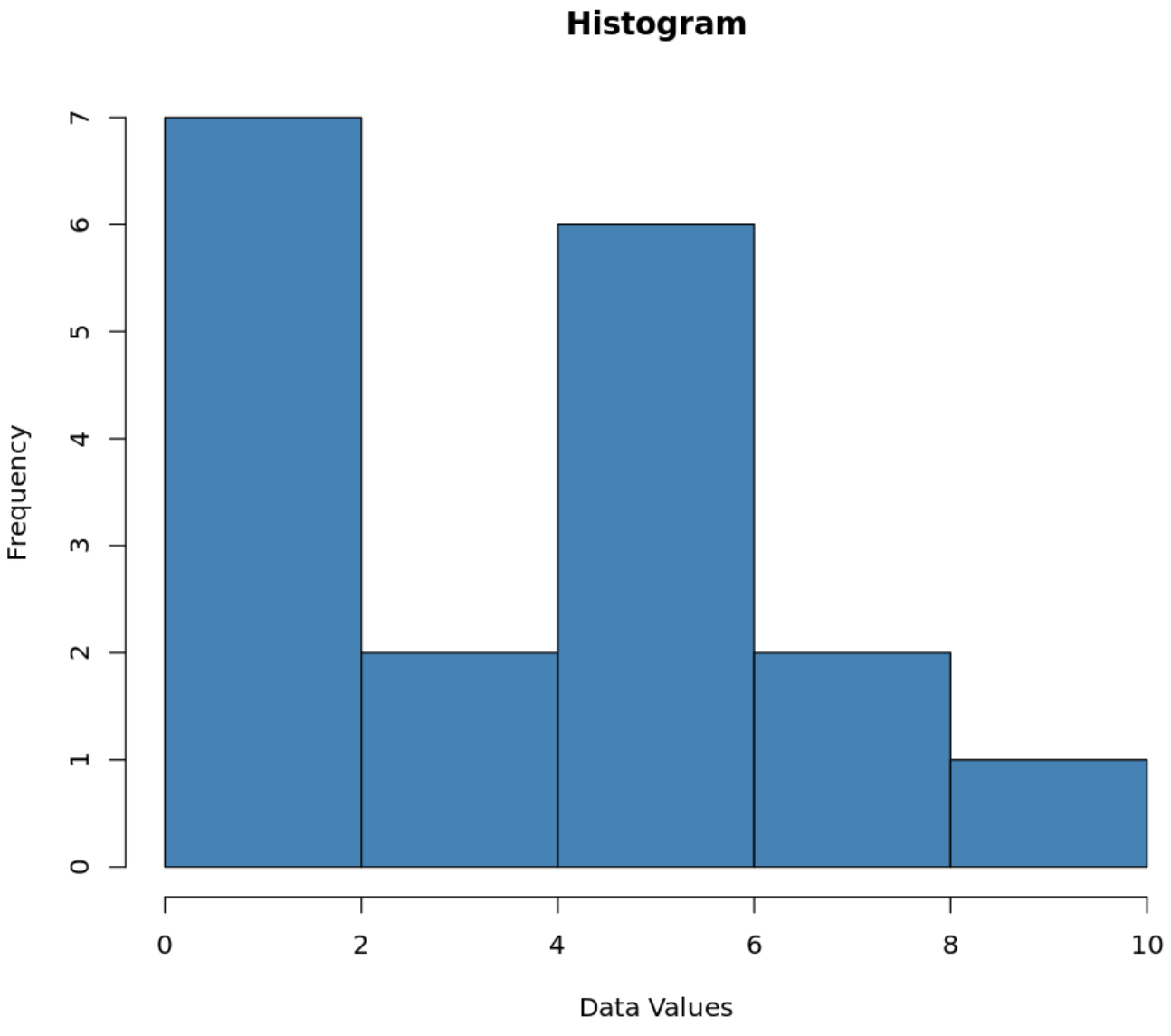
De nette.
We kunnen bijvoorbeeld zien dat zeven waarden tussen 0 en 2 liggen, twee waarden tussen 2 en 4, enzovoort.
Bonus : voor degenen die nieuwsgierig zijn, hebben we de volgende R-code gebruikt om de hierboven weergegeven puntenplot en histogram te maken:
#define dataset data <- c(1, 1, 1, 1, 2, 2, 2, 3, 4, 5, 5, 6, 6, 6, 6, 7, 8, 10) #create dot plot stripchart(data, method = "stack", offset = .5, at = 0, pch = 19, cex=5, col = "steelblue", main = "Dot Plot", xlab = "Data Values", ylab="Frequency") #create histogram hist(data, col='steelblue', main='Histogram', xlab='Data Values')
Puntplot of histogram: welke moet u gebruiken?
Zoals eerder vermeld kunnen een dotplot en histogram worden gebruikt om de verdeling van waarden in een dataset te visualiseren.
Als vuistregel gebruiken we meestal puntplots als onze dataset klein is, omdat we hierdoor precies kunnen zien hoe vaak elke individuele waarde voorkomt.
Omgekeerd gebruiken we doorgaans histogrammen als onze dataset groot is, omdat het vervelend is om een punt te creëren om elke individuele waarde in een grote dataset weer te geven.
Houd er rekening mee dat het enige nadeel van het gebruik van een histogram is dat we niet precies kunnen zeggen hoe vaak elke afzonderlijke waarde voorkomt.
In het vorige histogram zagen we bijvoorbeeld dat zeven waarden tussen 0 en 2 lagen, maar we weten niet precies hoeveel waarden 1 waren en hoeveel waarden 2 waren.
Als we alleen de algemene ‘vorm’ van een verdeling willen begrijpen, dan maakt het over het algemeen niet uit als we de individuele waarden van een dataset niet kennen.
Houd er ook rekening mee dat we de exacte mediaan of het exacte gemiddelde niet kunnen berekenen door alleen maar naar een histogram te kijken, omdat we de individuele waarden niet kennen.
Aanvullende bronnen
De volgende zelfstudies bieden aanvullende informatie over histogrammen:
Hoe u de gemiddelde en mediaanhistogrammen kunt schatten
Hoe de vorm van histogrammen te beschrijven
Histogrammen maken in R
Hoe u een histogram maakt in Python
De volgende tutorials bieden aanvullende informatie over puntplots:
Hoe u het midden en de spreiding van een puntendiagram kunt vinden
Hoe u een puntplot maakt in Google Spreadsheets
Hoe u een puntplot maakt in Excel
Een puntplot maken in R
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder