Hoe specifieke regels uit een csv-bestand in r te lezen
U kunt de volgende methoden gebruiken om specifieke regels uit een CSV-bestand in R te lezen:
Methode 1: Importeer een CSV-bestand uit een specifieke rij
df <- read. csv (" my_data.csv ", skip= 2 )
In dit specifieke voorbeeld worden de eerste twee regels van het CSV-bestand overgeslagen en worden alle andere regels van het bestand geïmporteerd, te beginnen met de derde regel.
Methode 2: Importeer een CSV-bestand waarvan de rijen aan de voorwaarde voldoen
library (sqldf) df <- read. csv . sql (" my_data.csv ", sql = " select * from file where `points` > 90 ", eol = " \n ")
In dit specifieke voorbeeld worden alleen rijen uit het CSV-bestand geïmporteerd waarvan de waarde in de kolom ‚punten‘ groter is dan 90.
De volgende voorbeelden laten zien hoe u elk van deze methoden in de praktijk kunt gebruiken met het volgende CSV-bestand met de naam my_data.csv :
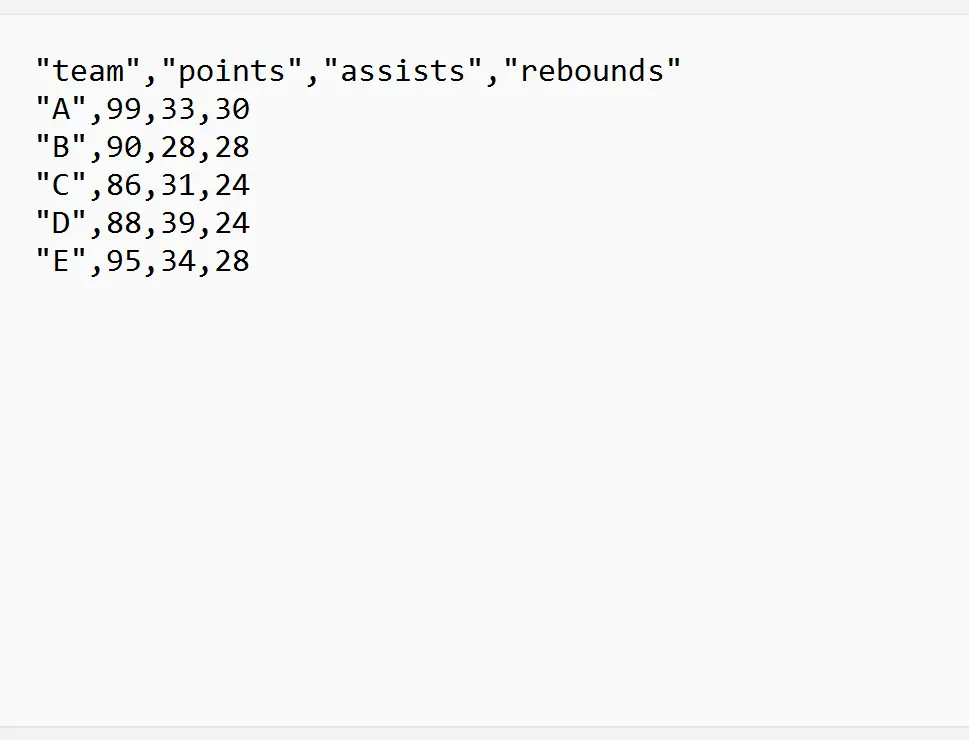
Voorbeeld 1: Importeer een CSV-bestand uit een specifieke rij
De volgende code laat zien hoe u het CSV-bestand importeert en de eerste twee regels van het bestand negeert:
#import data frame and skip first two rows
df <- read. csv (' my_data.csv ', skip= 2 )
#view data frame
df
B X90 X28 X28.1
1 C 86 31 24
2 D 88 39 24
3 E 95 34 28
Merk op dat de eerste twee regels (met teams A en B) werden genegeerd bij het importeren van het CSV-bestand.
Standaard probeert R de waarden van de volgende beschikbare rij als kolomnamen te gebruiken.
Om kolommen te hernoemen, kunt u de functie name() als volgt gebruiken:
#rename columns
names(df) <- c(' team ', ' points ', ' assists ', ' rebounds ')
#view updated data frame
df
team points assists rebounds
1 C 86 31 24
2 D 88 39 24
3 E 95 34 28
Voorbeeld 2: Importeer een CSV-bestand waarvan de rijen aan de voorwaarde voldoen
Stel dat we alleen die rijen uit het CSV-bestand willen importeren waarvan de waarde in de puntenkolom groter is dan 90.
We kunnen hiervoor de functie read.csv.sql uit het sqldf- pakket gebruiken:
library (sqldf)
#only import rows where points > 90
df <- read. csv . sql (" my_data.csv ",
sql = " select * from file where `points` > 90 ", eol = " \n ")
#view data frame
df
team points assists rebounds
1 “A” 99 33 30
2 “E” 95 34 28
Houd er rekening mee dat alleen de twee regels van het CSV-bestand waarvan de waarde in de kolom “punten” groter is dan 90 zijn geïmporteerd.
Opmerking #1 : In dit voorbeeld hebben we het eol- argument gebruikt om aan te geven dat het „einde van de regel“ in het bestand wordt aangegeven met \n , wat een nieuwe regel vertegenwoordigt.
Opmerking 2: In dit voorbeeld hebben we een eenvoudige SQL-query gebruikt, maar u kunt complexere query’s schrijven om rijen op nog meer voorwaarden te filteren.
Aanvullende bronnen
In de volgende tutorials wordt uitgelegd hoe u andere veelvoorkomende taken in R kunt uitvoeren:
Hoe een CSV van een URL in R te lezen
Hoe meerdere CSV-bestanden samen te voegen in R
Een dataframe exporteren naar een CSV-bestand in R
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder