Een complete gids voor de diamantdataset in r
De diamantgegevensset is een gegevensset die is ingebouwd in het ggplot2- pakket in R.
Het bevat metingen van 10 verschillende variabelen (zoals prijs, kleur, helderheid, enz.) voor 53.940 verschillende diamanten.
In deze tutorial wordt uitgelegd hoe u de diamantdataset in R kunt verkennen, samenvatten en visualiseren.
Diamantgegevensset laden
Omdat de diamantdataset een ingebouwde dataset is in ggplot2, moeten we eerst het ggplot2-pakket installeren (als dat nog niet is gebeurd) en laden:
#install ggplot2 if not already installed
install. packages (' ggplot2 ')
#load ggplot2
library (ggplot2)
Nadat we ggplot2 hebben geladen, kunnen we de functie data() gebruiken om de diamantgegevensset te laden:
data(diamonds)
We kunnen de eerste zes rijen van de dataset bekijken met behulp van de head() functie:
#view first six rows of diamonds dataset
head(diamonds)
carat cut color clarity depth table price xyz
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
4 0.290 Premium I VS2 62.4 58 334 4.2 4.23 2.63
5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
Vat de diamantgegevensset samen
We kunnen de functie summary() gebruiken om elke variabele in de dataset snel samen te vatten:
#summarize diamonds dataset
summary(diamonds)
carat cut color clarity depth
Min. :0.2000 Fair: 1610 D: 6775 SI1:13065 Min. :43.00
1st Qu.:0.4000 Good: 4906 E: 9797 VS2:12258 1st Qu.:61.00
Median: 0.7000 Very Good: 12082 F: 9542 SI2: 9194 Median: 61.80
Mean: 0.7979 Premium: 13791 G: 11292 VS1: 8171 Mean: 61.75
3rd Qu.:1.0400 Ideal:21551 H:8304 VVS2:5066 3rd Qu.:62.50
Max. :5.0100 I: 5422 VVS1: 3655 Max. :79.00
D: 2808 (Other): 2531
table price xyz Min. :43.00 Min. : 326 Min. : 0.000 Min. : 0.000 Min. : 0.000
1st Qu.: 56.00 1st Qu.: 950 1st Qu.: 4.710 1st Qu.: 4.720 1st Qu.: 2.910
Median: 57.00 Median: 2401 Median: 5.700 Median: 5.710 Median: 3.530
Mean: 57.46 Mean: 3933 Mean: 5.731 Mean: 5.735 Mean: 3.539
3rd Qu.: 59.00 3rd Qu.: 5324 3rd Qu.: 6.540 3rd Qu.: 6.540 3rd Qu.: 4.040
Max. :95.00 Max. :18823 Max. :10,740 Max. :58,900 Max. :31,800
Voor elk van de numerieke variabelen kunnen we de volgende informatie zien:
- Min : De minimumwaarde.
- 1e Qu : de waarde van het eerste kwartiel (25e percentiel).
- Mediaan : de mediaanwaarde.
- Gemiddelde : de gemiddelde waarde.
- 3e Qu : de waarde van het derde kwartiel (75e percentiel).
- Max : de maximale waarde.
Voor de categorische variabelen in de dataset (uitsnede, kleur en helderheid) zien we een frequentietelling van elke waarde.
Voor de snijvariabele bijvoorbeeld:
- Redelijk : deze waarde verschijnt 1.610 keer.
- Goed : deze waarde verschijnt 4.906 keer.
- Zeer goed : deze waarde verschijnt 12.082 keer.
- Premium : deze waarde verschijnt 13.791 keer.
- Ideaal : deze waarde verschijnt 21.551 keer.
We kunnen de functie dim() gebruiken om de afmetingen van de dataset te verkrijgen in termen van het aantal rijen en kolommen:
#display rows and columns
dim(diamonds)
[1] 53940 10
We kunnen zien dat de dataset 53.940 rijen en 10 kolommen heeft.
We kunnen ook de functie namen() gebruiken om de kolomnamen van het dataframe weer te geven:
#display column names
names(diamonds)
[1] "carat" "cut" "color" "clarity" "depth" "table" "price" "x"
[9] “y” “z”
Visualiseer de Diamonds-gegevensset
We kunnen ook plots maken om de waarden van de dataset te visualiseren.
We kunnen bijvoorbeeld de functie geom_histogram() gebruiken om een histogram te maken van de waarden van een bepaalde variabele:
#create histogram of values for price
ggplot(data=diamonds, aes (x=price)) +
geom_histogram(fill=" steelblue ", color=" black ") +
ggtitle(" Histogram of Price Values ")
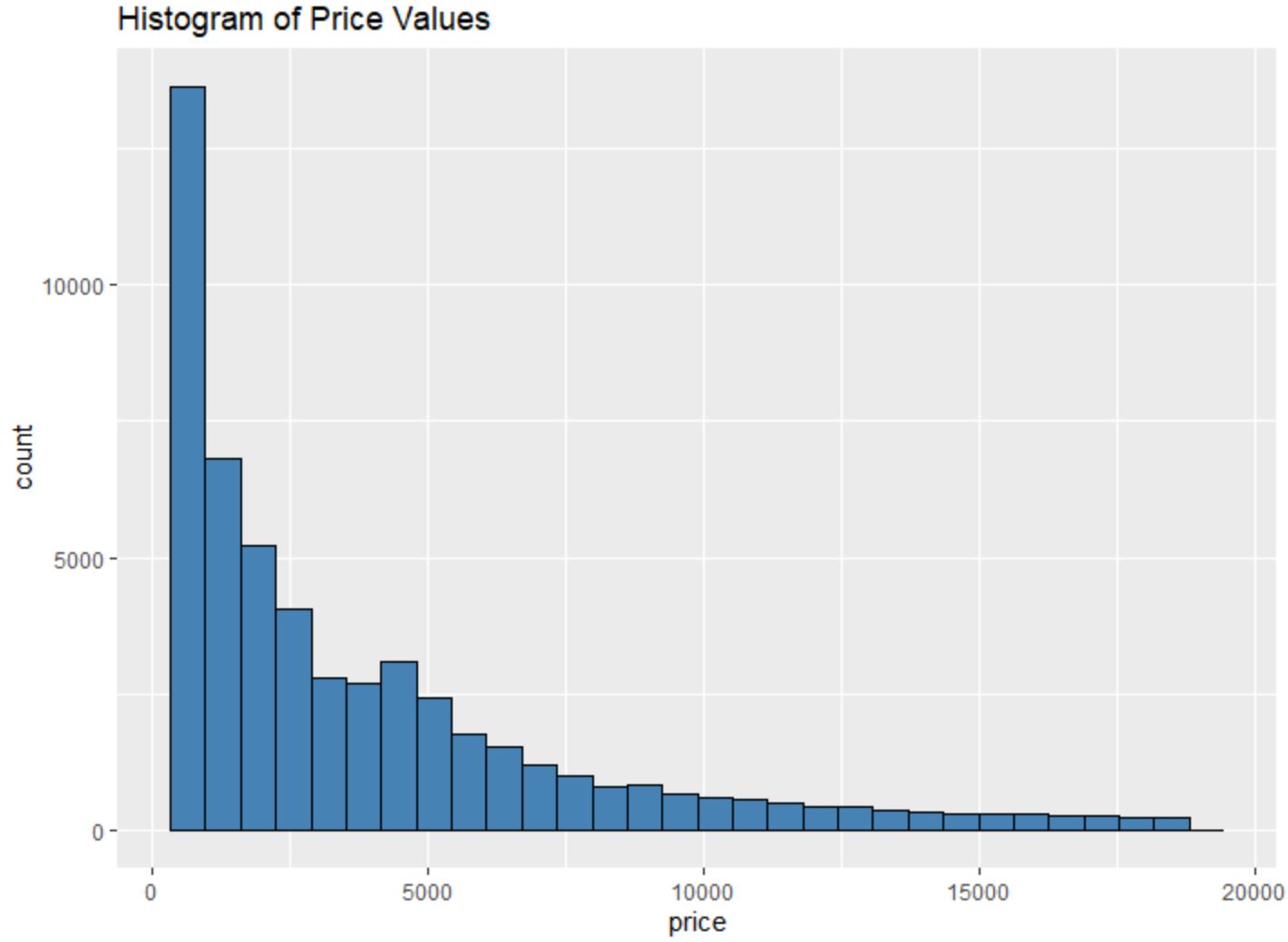
We kunnen ook de functie geom_point() gebruiken om een puntenwolk te maken van elke paarsgewijze combinatie van variabelen:
#create scatterplot of carat vs. price, using cut as color variable
ggplot(data=diamonds, aes (x=carat, y=price, color=cut)) +
geom_point()
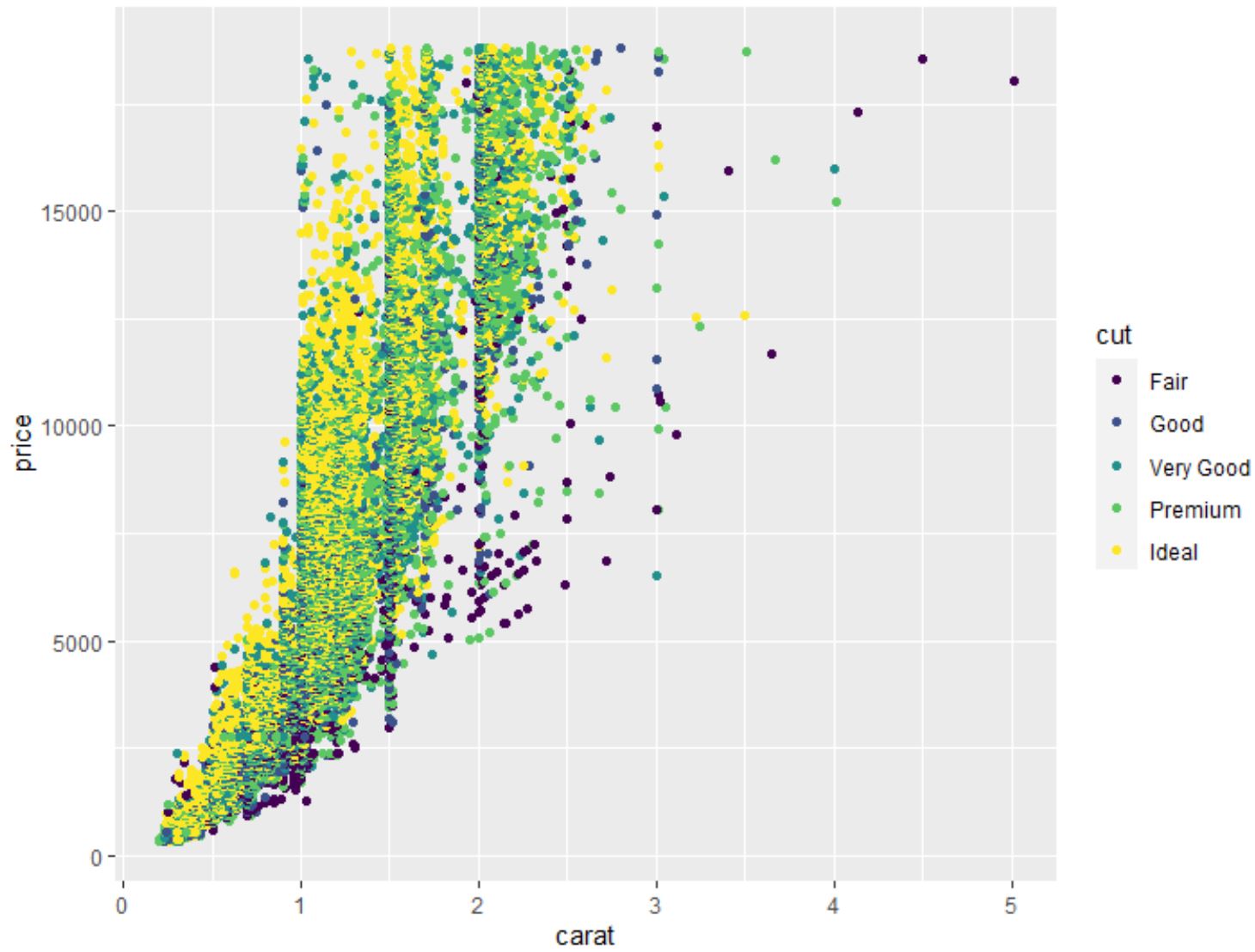
We kunnen ook de functie geom_boxplot() gebruiken om een boxplot te maken van een variabele gegroepeerd door een andere variabele:
#create scatterplot of price, grouped by cut
ggplot(data=diamonds, aes (x=cut, y=price)) +
geom_boxplot(fill=" steelblue ")
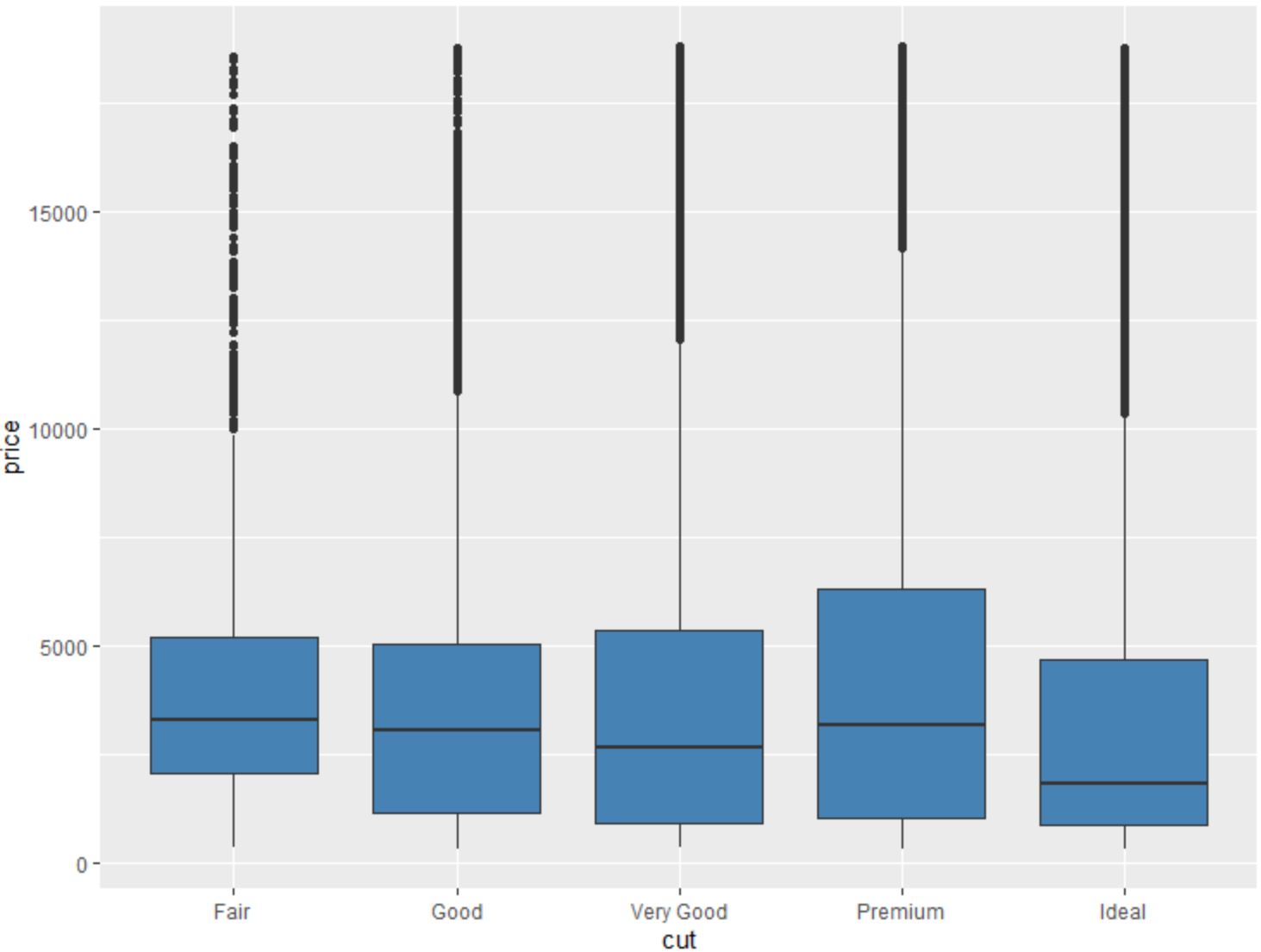
Met behulp van deze ggplot2-functies kunnen we veel leren over de variabelen in de diamantgegevensset .
Aanvullende bronnen
In de volgende zelfstudies wordt uitgelegd hoe u andere gegevenssets in R kunt verkennen:
Een complete gids voor de Iris-dataset in R
Een complete gids voor de mtcars-dataset in R
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder