A: hoe u het microbenchmarkpakket gebruikt om de uitvoeringstijd te meten
U kunt het microbenchmark- pakket in R gebruiken om de uitvoeringstijd van verschillende expressies te vergelijken.
U kunt hiervoor de volgende syntaxis gebruiken:
library (microbenchmark) #compare execution time of two different expressions microbenchmark( expression1, expression2) )
Het volgende voorbeeld laat zien hoe u deze syntaxis in de praktijk kunt gebruiken.
Voorbeeld: microbenchmark() gebruiken in R
Stel dat we het volgende dataframe in R hebben dat informatie bevat over de punten die zijn gescoord door spelers van verschillende basketbalteams:
#make this example reproducible
set. seed ( 1 )
#create data frame
df <- data. frame (team=rep(c(' A ', ' B '), each= 500 ),
points=rnorm( 1000 , mean= 20 ))
#view data frame
head(df)
team points
1 A 19.37355
2 A 20.18364
3 A 19.16437
4 A 21.59528
5 A 20.32951
6 A 19.17953
Stel nu dat we de gemiddelde punten die door spelers van elk team zijn gescoord, willen berekenen met behulp van twee verschillende methoden:
- Methode 1 : Gebruik Aggregate() van Base R
- Methode 2 : Gebruik group_by() en summarise_at() van dplyr
We kunnen de functie microbenchmark() gebruiken om de tijd te meten die nodig is om elk van deze expressies uit te voeren:
library (microbenchmark) library (dplyr) #time how long it takes to calculate mean value of points by team microbenchmark( aggregate(df$points, list(df$team), FUN=mean), df %>% group_by(team) %>% summarise_at(vars(points), list(name = mean)) ) Unit: milliseconds express aggregate(df$points, list(df$team), FUN = mean) df %>% group_by(team) %>% summarise_at(vars(points), list(name = mean)) min lq mean median uq max neval cld 1.307908 1.524078 1.852167 1.743568 2.093813 4.67408 100 a 6.788584 7.810932 9.946286 8.914692 10.239904 56.20928 100 b
De functie microbenchmark() voert elke expressie 100 keer uit en meet de volgende statistieken:
- min : Minimale tijd vereist voor uitvoering
- lq : onderste kwartiel (25e percentiel) van de tijd die nodig is om te voltooien
- Gemiddelde : gemiddelde tijd die nodig is voor uitvoering
- mediaan : Mediane uitvoeringstijd
- uq : bovenste kwartiel (75e percentiel) van de tijd die nodig is om uit te voeren
- max : maximale tijd die nodig is voor uitvoering
- neval : Aantal keren dat elke expressie is geëvalueerd
Meestal kijken we alleen naar de gemiddelde of mediane tijd die nodig is om elke expressie uit te voeren.
Uit het resultaat kunnen we zien:
- Het kostte een gemiddelde tijd van 1.852 milliseconden om het teampuntengemiddelde te berekenen met behulp van de R-gebaseerde methode.
- Het kostte gemiddeld 9,946 milliseconden om de gemiddelde punten per team te berekenen met behulp van de dplyr-methode.
Op basis van deze resultaten concluderen we dat de basis-R-methode aanzienlijk sneller is.
We kunnen ook de functie boxplot() gebruiken om de verdeling van de tijden te visualiseren die nodig zijn om elke expressie uit te voeren:
library (microbenchmark) library (dplyr) #time how long it takes to calculate mean value of points by team results <- microbenchmark( aggregate(df$points, list(df$team), FUN=mean), df %>% group_by(team) %>% summarise_at(vars(points), list(name = mean)) ) #create boxplot to visualize results boxplot(results, names=c(' Base R ', ' dplyr '))
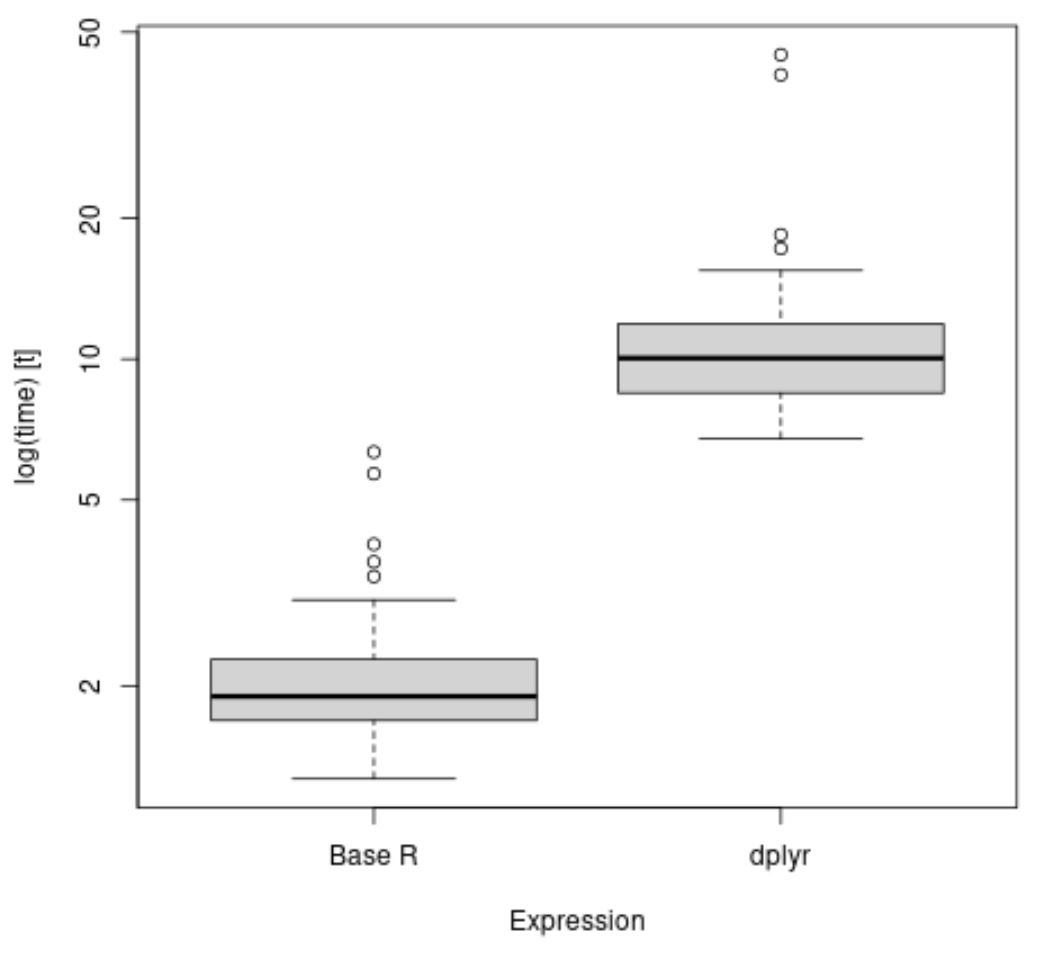
Uit de boxplots kunnen we zien dat de dplyr-methode er gemiddeld langer over doet om de gemiddelde puntenwaarde per team te berekenen.
Opmerking : in dit voorbeeld hebben we de functie microbenchmark() gebruikt om de uitvoeringstijd van twee verschillende expressies te vergelijken, maar in de praktijk kun je zoveel expressies vergelijken als je wilt.
Aanvullende bronnen
In de volgende tutorials wordt uitgelegd hoe u andere veelvoorkomende taken in R kunt uitvoeren:
Hoe de omgeving te wissen in R
Hoe alle plots in RStudio te wissen
Hoe meerdere pakketten in R te laden
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder