Regressie of classificatie: wat is het verschil?
Machine learning-algoritmen kunnen worden onderverdeeld in twee verschillende typen: begeleide en niet-gecontroleerde leeralgoritmen .

Algoritmen voor begeleid leren kunnen in twee typen worden ingedeeld:
1. Regressie: de responsvariabele is continu.
De responsvariabele zou bijvoorbeeld kunnen zijn:
- Gewicht
- Hoogte
- Prijs
- Tijd
- Totaal aantal eenheden
In elk geval probeert een regressiemodel een continue hoeveelheid te voorspellen.
Regressievoorbeeld:
Laten we zeggen dat we een dataset hebben met drie variabelen voor 100 verschillende huizen: vierkante meters, aantal badkamers en verkoopprijs.
We zouden een regressiemodel kunnen toepassen dat vierkante meters en het aantal badkamers gebruikt als verklarende variabelen en de verkoopprijs als responsvariabele.
We zouden dit model vervolgens kunnen gebruiken om de verkoopprijs van een huis te voorspellen, op basis van de vierkante meters en het aantal badkamers.
Dit is een voorbeeld van een regressiemodel omdat de responsvariabele (verkoopprijs) continu is.
De meest gebruikelijke manier om de nauwkeurigheid van een regressiemodel te meten is door de root mean square error (RMSE) te berekenen, een metriek die ons vertelt hoe ver onze voorspelde waarden gemiddeld verwijderd zijn van onze waargenomen waarden in een model. Het wordt als volgt berekend:
RMSE = √ Σ(P ik – O ik ) 2 / n
Goud:
- Σ is een mooi symbool dat ‘som’ betekent
- Pi is de voorspelde waarde voor de i- de waarneming
- O i is de waargenomen waarde voor de i- de waarneming
- n is de steekproefomvang
Hoe kleiner de RMSE, hoe beter een regressiemodel bij de gegevens kan passen.
2. Classificatie: De responsvariabele is categorisch.
De responsvariabele kan bijvoorbeeld de volgende waarden aannemen:
- Man of vrouw
- Slagen of mislukken
- Laag, gemiddeld of hoog
In elk geval probeert een classificatiemodel een klassenlabel te voorspellen.
Voorbeeld van classificatie:
Laten we zeggen dat we een dataset hebben met drie variabelen voor 100 verschillende universiteitsbasketbalspelers: het gemiddelde aantal punten per wedstrijd, het niveau van de divisie en of ze wel of niet zijn opgeroepen voor de NBA.
We zouden een classificatiemodel kunnen aanpassen dat gemiddelde punten per spel en per divisieniveau gebruikt als verklarende variabelen en ‘opgesteld’ als de responsvariabele.
We kunnen dit model vervolgens gebruiken om te voorspellen of een bepaalde speler wel of niet wordt opgenomen in de NBA op basis van het aantal punten per wedstrijd en het divisieniveau.
Dit is een voorbeeld van een classificatiemodel omdat de responsvariabele (“geschreven”) categorisch is. Met andere woorden, het kan alleen waarden aannemen in twee verschillende categorieën: ‘Geschreven’ of ‘Niet opgesteld’.
De meest gebruikelijke manier om de nauwkeurigheid van een classificatiemodel te meten, is eenvoudigweg door het percentage correcte classificaties van het model te berekenen:
Nauwkeurigheid = correctieclassificaties / totaal aantal classificatiepogingen * 100%
Als een model bijvoorbeeld correct identificeert of een speler 88 van de 100 keer wordt opgeroepen voor de NBA, dan is de nauwkeurigheid van het model:
Nauwkeurigheid = (88/100) * 100% = 88%
Hoe hoger de nauwkeurigheid, hoe beter een classificatiemodel resultaten kan voorspellen.
Overeenkomsten tussen regressie en classificatie
Regressie- en classificatie-algoritmen zijn op de volgende manieren vergelijkbaar:
- Beide zijn begeleide leeralgoritmen, dat wil zeggen dat ze allebei een responsvariabele bevatten.
- Beide gebruiken een of meer verklarende variabelen om modellen te creëren om een reactie te voorspellen.
- Beide kunnen worden gebruikt om te begrijpen hoe veranderingen in de waarden van verklarende variabelen de waarden van een responsvariabele beïnvloeden.
Verschillen tussen regressie en classificatie
Regressie- en classificatie-algoritmen verschillen op de volgende manieren:
- Regressie-algoritmen proberen een continue hoeveelheid te voorspellen en classificatie-algoritmen proberen een klassenlabel te voorspellen.
- Hoe we de nauwkeurigheid van regressie- en classificatiemodellen meten, verschilt.
Regressie omzetten in classificatie
Opgemerkt moet worden dat een regressieprobleem kan worden omgezet in een classificatieprobleem door de responsvariabele simpelweg in compartimenten te discretiseren .
Laten we bijvoorbeeld zeggen dat we een dataset hebben die drie variabelen bevat: vierkante meters, aantal badkamers en verkoopprijs.
We zouden een regressiemodel kunnen bouwen met behulp van vierkante meters en het aantal badkamers om de verkoopprijzen te voorspellen.
We kunnen de verkoopprijs echter in drie verschillende klassen verdelen:
- $80.000 – $160.000: “Lage verkoopprijs”
- $161.000 – $240.000: “Gemiddelde verkoopprijs”
- $241.000 – $320.000: “Hoge verkoopprijs”
We kunnen dan vierkante meters en het aantal badkamers gebruiken als verklarende variabelen om te voorspellen in welke klasse (laag, gemiddeld of hoog) de verkoopprijs van een bepaald huis zal vallen.
Dit zou een voorbeeld zijn van een classificatiemodel, aangezien we proberen elk huis in een klasse te plaatsen.
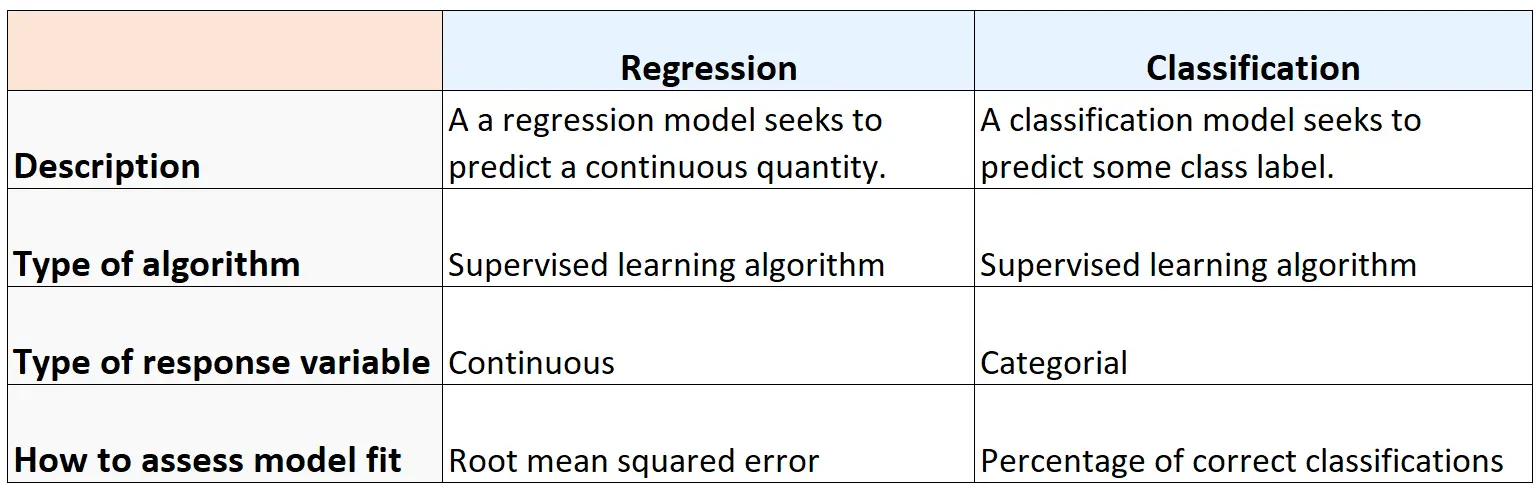
Samenvatting
De volgende tabel vat de overeenkomsten en verschillen tussen regressie- en classificatie-algoritmen samen:
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder