Wat wordt beschouwd als ruwe data? (definitie & voorbeelden)
In de statistieken verwijzen ruwe gegevens naar gegevens die rechtstreeks uit een primaire bron zijn verzameld en op geen enkele manier zijn verwerkt.
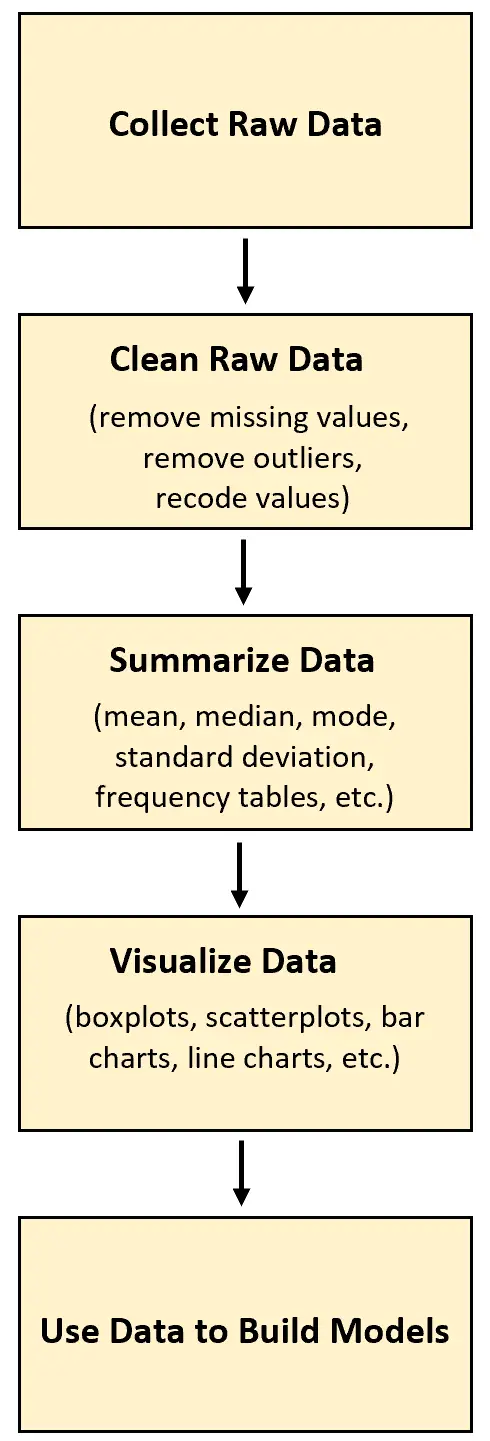
Bij elk type data-analyseproject is de eerste stap het verzamelen van onbewerkte gegevens. Zodra deze gegevens zijn verzameld, kunnen ze worden opgeschoond, getransformeerd, samengevat en gevisualiseerd.
Het voordeel van het verzamelen van ruwe data is dat je deze uiteindelijk kunt gebruiken om bepaalde fenomenen beter te begrijpen of om een soort voorspellend model te bouwen.
Het volgende voorbeeld illustreert hoe ruwe gegevens in het echte leven kunnen worden verzameld en gebruikt.
Voorbeeld: verzamelen en gebruiken van ruwe data
Sport is een gebied waar vaak ruwe data worden verzameld. Er kunnen bijvoorbeeld ruwe gegevens worden verzameld voor verschillende statistieken over professionele basketbalspelers.
Stap 1: Verzamel ruwe gegevens
Stel je voor dat een basketbalscout de volgende ruwe gegevens verzamelt voor 10 spelers van een professioneel basketbalteam: 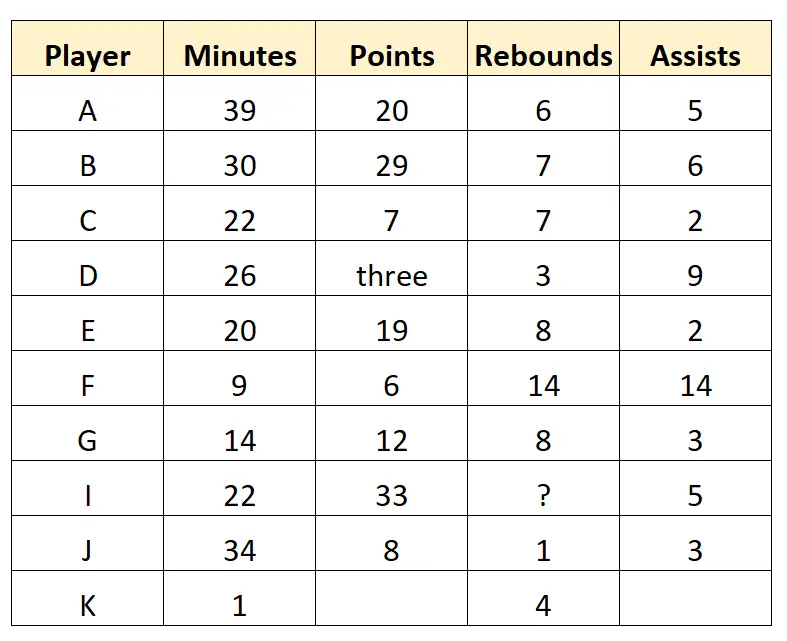
Deze dataset vertegenwoordigt de onbewerkte gegevens , aangezien deze rechtstreeks door de scout worden verzameld en op geen enkele manier zijn opgeschoond of verwerkt.
Stap 2: Reinig de onbewerkte gegevens
Voordat de scout deze gegevens gebruikt om samenvattende tabellen, grafieken of iets anders te maken, moet hij eerst eventuele ontbrekende waarden verwijderen en eventuele „vuile“ gegevenswaarden opruimen.
We kunnen bijvoorbeeld verschillende waarden in de dataset tegenkomen die moeten worden getransformeerd of verwijderd:
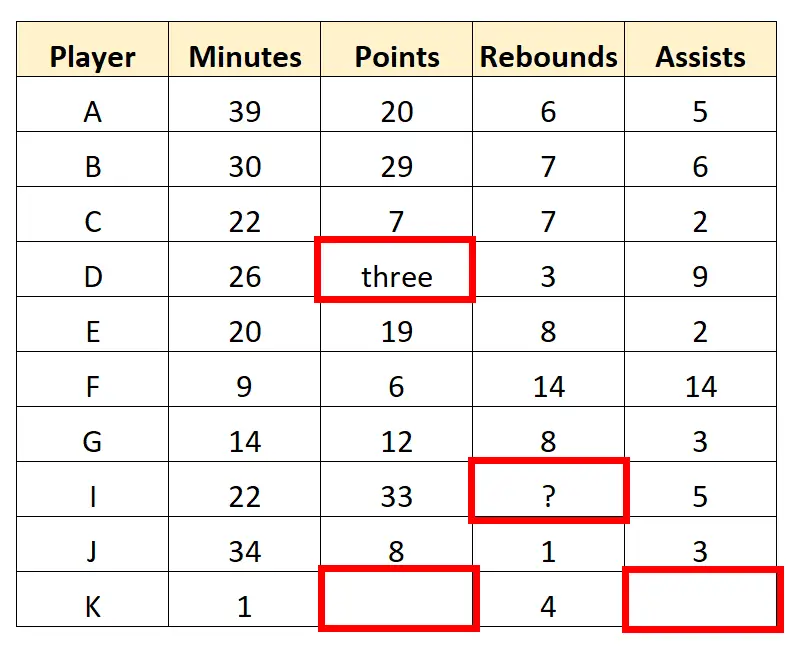
De verkenner kan besluiten de laatste rij geheel te verwijderen, omdat er meerdere ontbrekende waarden in staan. Vervolgens kan het de tekenwaarden in de dataset opschonen om de volgende „schone“ gegevens te verkrijgen:
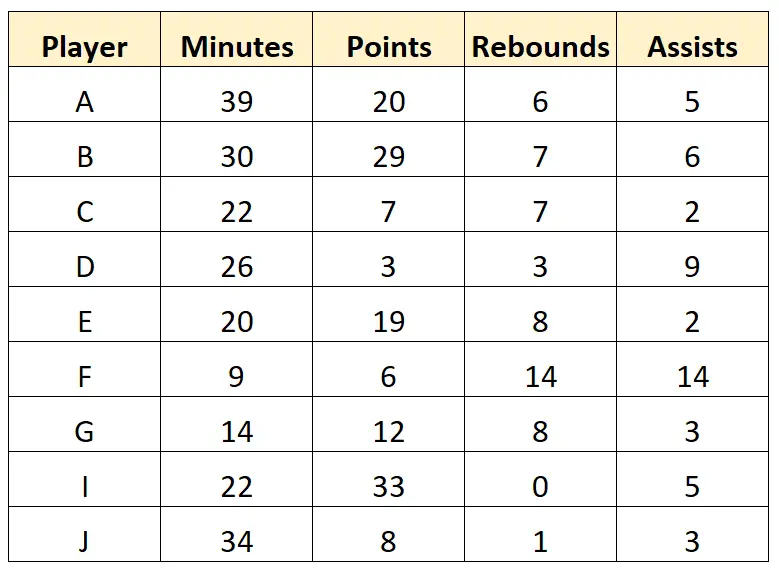
Stap 3: Vat de gegevens samen
Zodra de gegevens zijn opgeschoond, kan de verkenner elke variabele in de dataset samenvatten. Het kan bijvoorbeeld de volgende samenvattende statistieken voor de variabele ‚Minuten‘ berekenen:
- Gemiddeld : 24 minuten
- Mediaan : 22 minuten
- Standaardafwijking : 9,45 minuten
Stap 4: Visualiseer de gegevens
De verkenner kan vervolgens de variabelen in de dataset visualiseren om de datawaarden beter te begrijpen.
Hij zou bijvoorbeeld het volgende staafdiagram kunnen maken om het totale aantal gespeelde minuten van elke speler te visualiseren:
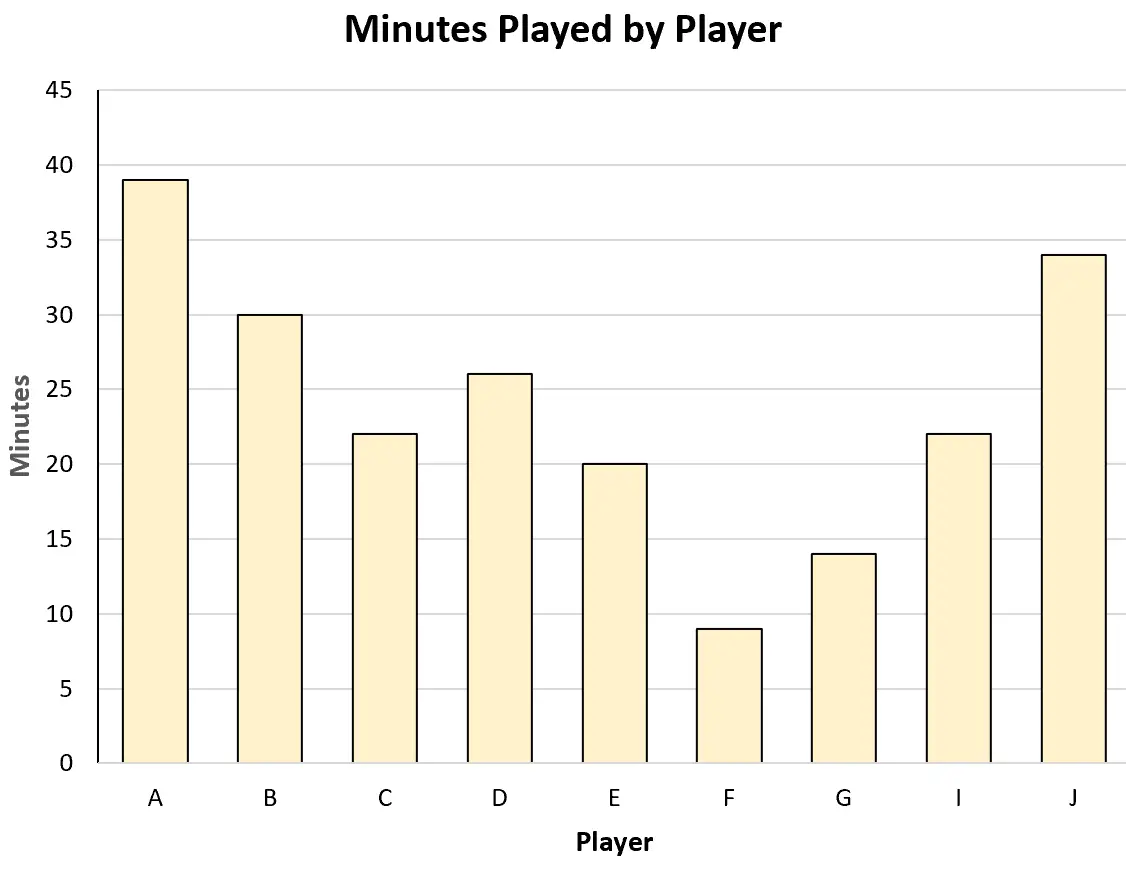
Of hij kan het volgende spreidingsdiagram maken om de relatie tussen gespeelde minuten en gescoorde punten te visualiseren:
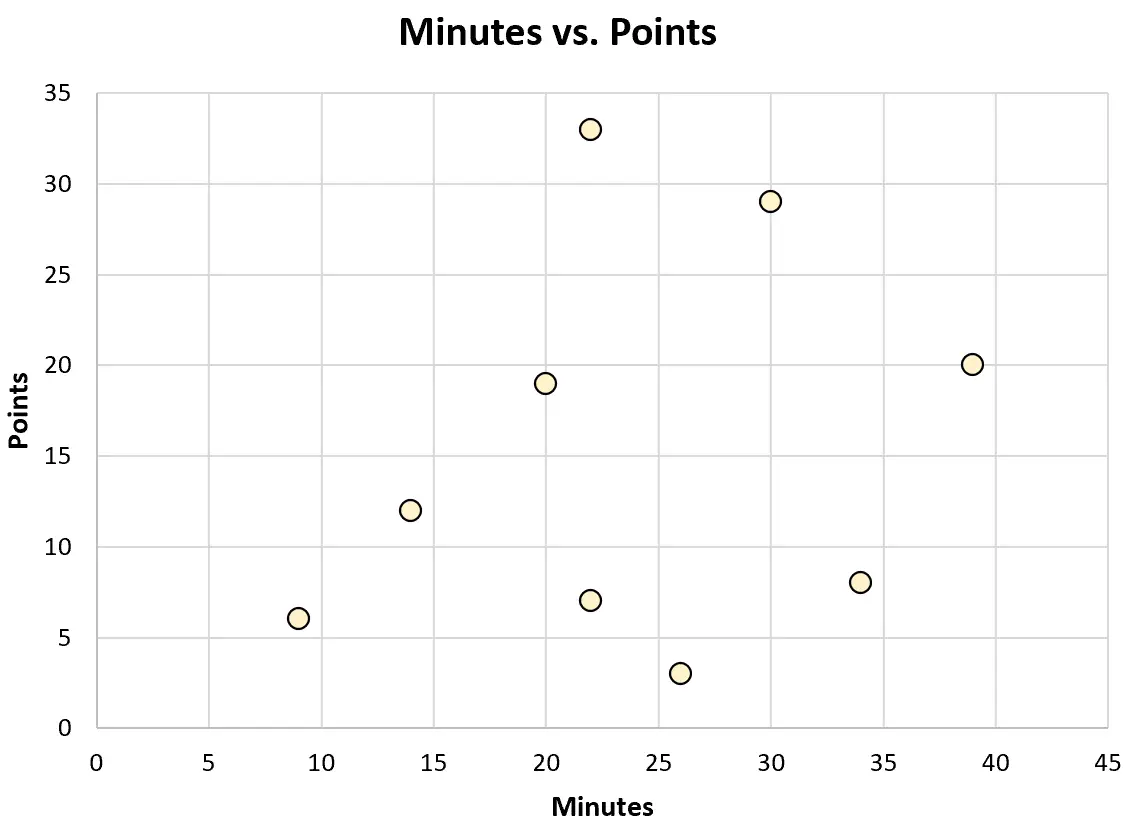
Elk van dit soort diagrammen kan hem helpen de gegevens beter te begrijpen.
Stap 5: Gebruik gegevens om een model te bouwen
Ten slotte kan de verkenner, zodra de gegevens zijn opgeschoond, besluiten een soort voorspellend model aan te passen.
Het kan bijvoorbeeld passen in een eenvoudig lineair regressiemodel en gespeelde minuten gebruiken om het totaal aantal punten te voorspellen dat door elke speler wordt gescoord.
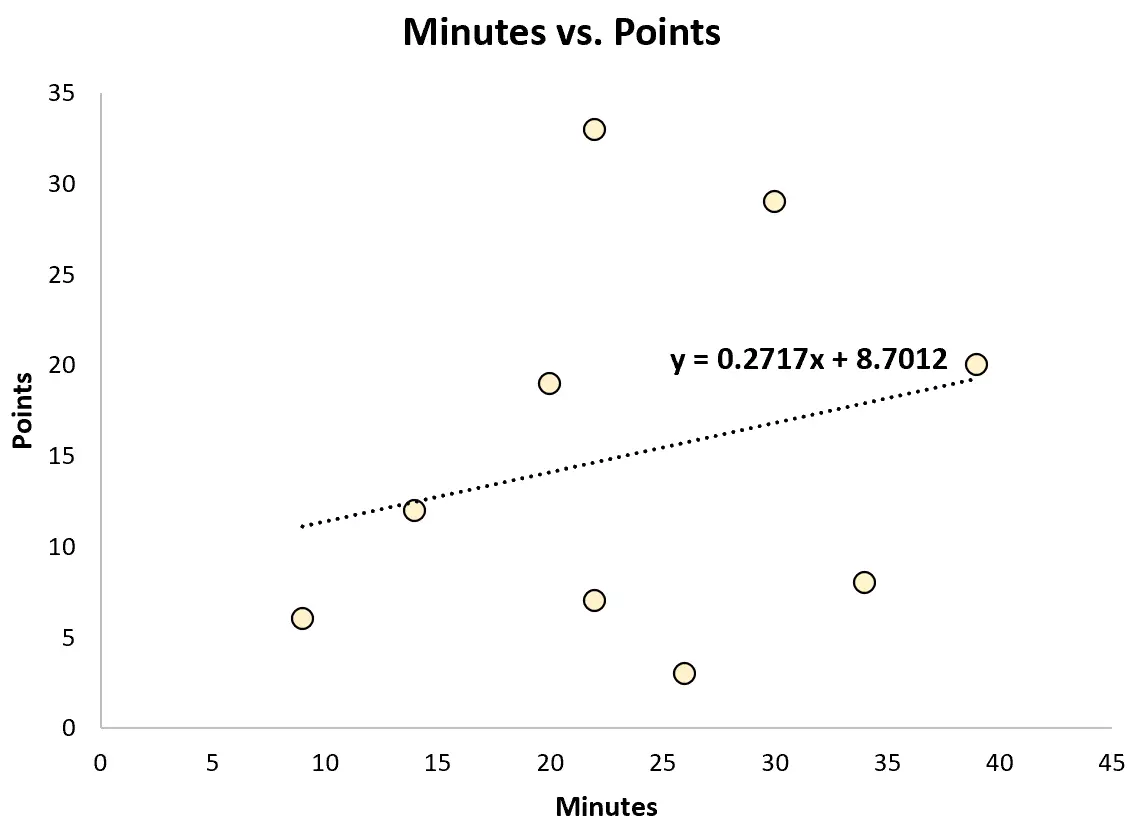
De aangepaste regressievergelijking is:
Punten = 8,7012 + 0,2717*(minuten)
De scout kan deze vergelijking vervolgens gebruiken om het aantal punten te voorspellen dat een speler zal scoren op basis van het aantal gespeelde minuten. Een atleet die bijvoorbeeld 30 minuten speelt, moet 16,85 punten scoren:
Punten = 8,7012 + 0,2717*(30) = 16,85
Aanvullende bronnen
Waarom zijn statistieken belangrijk?
Waarom is steekproefomvang belangrijk in statistieken?
Wat is een observatie in de statistiek?
Wat zijn tabelgegevens in statistieken?
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder