Hoe de lsmeans-instructie in sas te gebruiken (met voorbeeld)
Een eenrichtings-ANOVA wordt gebruikt om te bepalen of er al dan niet een statistisch significant verschil bestaat tussen de gemiddelden van drie of meer onafhankelijke groepen.
Als de totale p-waarde van de ANOVA-tabel onder een bepaald significantieniveau ligt, hebben we voldoende bewijs om te zeggen dat ten minste één van de groepsgemiddelden verschilt van de andere.
Om er precies achter te komen welke groepsgemiddelden verschillend zijn, moeten we eenpost-hoctest uitvoeren.
U kunt de LSMEANS -instructie in SAS gebruiken om verschillende post-hoc-tests uit te voeren.
Het volgende voorbeeld laat zien hoe u de LSMEANS- instructie in de praktijk kunt gebruiken.
Voorbeeld: hoe u de LSMEANS-instructie in SAS gebruikt
Stel dat een onderzoeker 30 studenten recruteert om aan een onderzoek deel te nemen. Studenten worden willekeurig toegewezen om een van de drie studiemethoden te gebruiken ter voorbereiding op een examen.
Hieronder vindt u de examenresultaten per student:
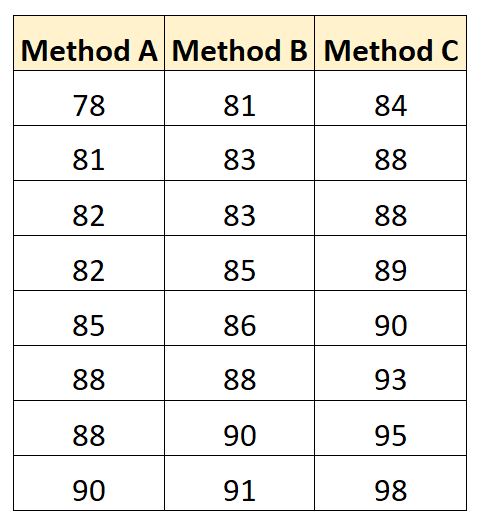
We kunnen de volgende code gebruiken om deze gegevensset in SAS te maken:
/*create dataset*/
data my_data;
input Method $Score;
datalines ;
At 78
At 81
At 82
At 82
At 85
At 88
At 88
At 90
B 81
B 83
B 83
B85
B 86
B 88
B90
B91
C 84
C 88
C 88
C 89
C 90
C 93
C 95
C 98
;
run ;
Vervolgens zullen we proc ANOVA gebruiken om de eenrichtings-ANOVA uit te voeren:
/*perform one-way ANOVA*/
proc ANOVA data =my_data;
classMethod ;
modelScore = Method;
run ;
Dit levert de volgende ANOVA-tabel op:
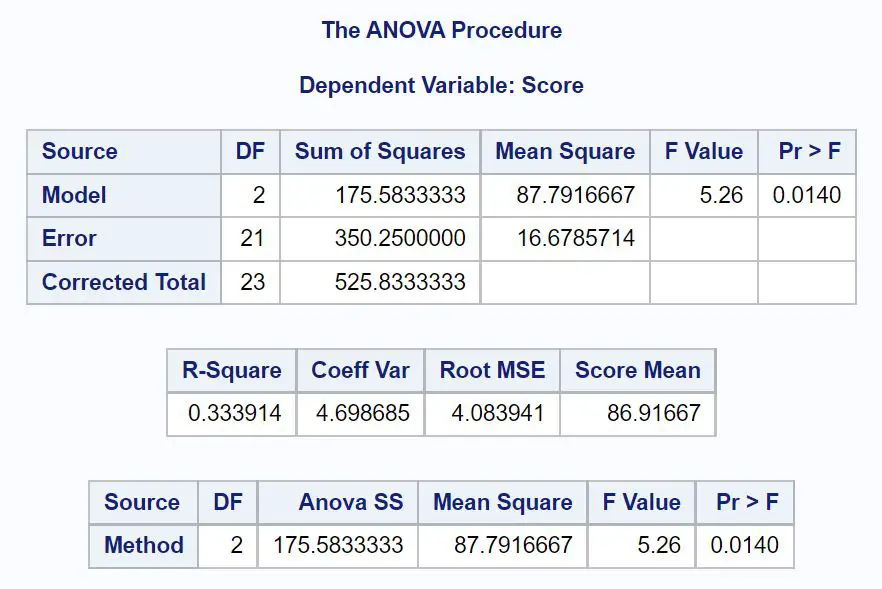
Uit deze tabel kunnen we zien:
- Totale F-waarde: 5,26
- De bijbehorende p-waarde: 0,0140
Bedenk dat een eenrichtings-ANOVA de volgende nul- en alternatieve hypothesen gebruikt:
- H 0 : Alle groepsgemiddelden zijn gelijk.
- H A : Minstens één groepsgemiddelde is anders rest.
Omdat de p-waarde van de ANOVA-tabel ( 0,0140 ) kleiner is dan α = 0,05, verwerpen we de nulhypothese.
Dit vertelt ons dat de gemiddelde examenscore niet gelijk is over de drie studievormen.
Om precies te bepalen welke groepsgemiddelden verschillend zijn, kunnen we de PROC GLIMMIX- instructie gebruiken met de LSMEANS- instructie en de ADJUST=TUKEY- optie om de post-hoc-tests van Tukey uit te voeren:
/*perform Tukey post-hoc comparisons*/
proc glimmix data =my_data;
classMethod ;
modelScore = Method;
lsmeans Method / adjust =tukey alpha = .05 ;
run ;
De laatste resultatentabel toont de resultaten van Tukey’s post-hocvergelijkingen:

We kunnen naar de kolom Adj P kijken om de p-waarden te bekijken, aangepast voor het verschil in groepsgemiddelden.
In deze kolom kunnen we zien dat er slechts één rij is met een aangepaste p-waarde kleiner dan 0,05: de rij die het gemiddelde verschil tussen groep A en groep C vergelijkt.
Dit vertelt ons dat er een statistisch significant verschil is in de gemiddelde examenscores tussen Groep A en Groep C.
Concreet kunnen we zien:
- Het verschil tussen de gemiddelde examenscores van groep A-studenten en groep B-studenten was – 6,375 . (dwz studenten in groep A hadden een gemiddelde examenscore die 6,375 punten lager was dan studenten in groep C)
- De aangepaste p-waarde voor het verschil in gemiddelden is 0,0137 .
- Het aangepaste 95%-betrouwbaarheidsinterval voor het werkelijke verschil in gemiddelde examenscores tussen deze twee groepen is [-11,5219, -1,2281] .
Er zijn geen statistisch significante verschillen tussen de gemiddelden van de andere groepen.
Opmerking : in dit voorbeeld hebben we ADJUST=TUKEY gebruikt om post-hoc-vergelijkingen van Tukey uit te voeren, maar u kunt ook BON , BUNNET , NELSON , SCHEFFE , SIDAK en SMM opgeven om andere typen post-hoc-vergelijkingen uit te voeren.
Gerelateerd: Tukey vs. Bonferroni vs. Scheffe: Welke test moet u gebruiken?
Aanvullende bronnen
De volgende tutorials bieden aanvullende informatie over ANOVA-modellen:
Een handleiding voor het gebruik van post-hoctesten met ANOVA
Eenrichtings-ANOVA uitvoeren in SAS
Hoe u tweerichtings-ANOVA uitvoert in SAS
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder