Hoe betrouwbaarheidsintervallen in sas te berekenen
Een betrouwbaarheidsinterval is een reeks waarden die waarschijnlijk een populatieparameter met een bepaald betrouwbaarheidsniveau bevatten.
In deze tutorial wordt uitgelegd hoe u de volgende betrouwbaarheidsintervallen in R kunt berekenen:
1. Betrouwbaarheidsinterval voor een populatiegemiddelde
2. Betrouwbaarheidsinterval voor een verschil in populatiegemiddelden
Laten we gaan!
Voorbeeld 1: Betrouwbaarheidsinterval voor het populatiegemiddelde in SAS
Stel dat we de volgende gegevensset hebben met de hoogte (in inches) van een willekeurige steekproef van 12 planten die allemaal tot dezelfde soort behoren:
/*create dataset*/ data my_data; inputHeight ; datalines ; 14 14 16 13 12 17 15 14 15 13 15 14 ; run ; /*view dataset*/ proc print data =my_data;
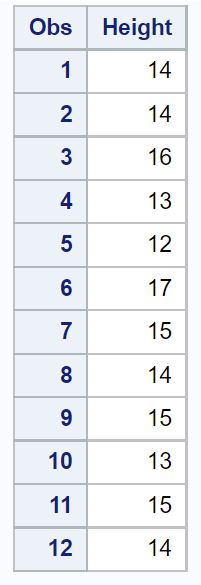
Stel dat we een betrouwbaarheidsniveau van 95% willen berekenen voor de werkelijke gemiddelde populatiegrootte van deze soort.
We kunnen hiervoor de volgende code in SAS gebruiken:
/*generate 95% confidence interval for population mean*/ proc ttest data =my_data alpha = 0.05 ; varHeight ; run ;
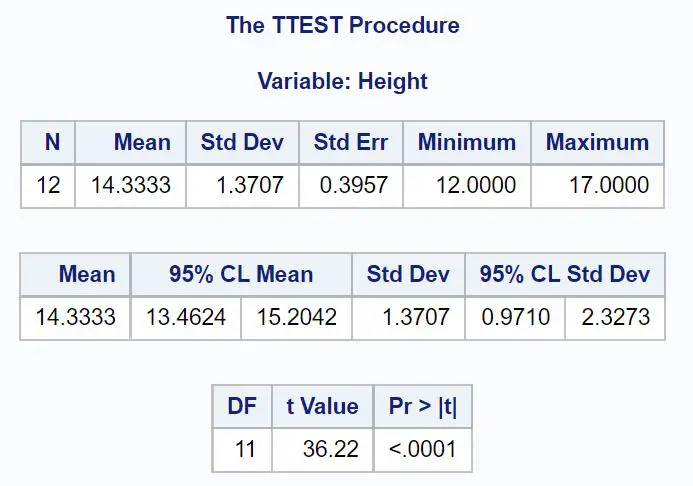
De waarde van Mean geeft het steekproefgemiddelde aan, en waarden kleiner dan 95% CL Mean tonen het 95% betrouwbaarheidsinterval voor het populatiegemiddelde.
Uit de resultaten kunnen we zien dat het 95% betrouwbaarheidsinterval voor het gemiddelde plantgewicht van deze populatie [13,4624 inch, 15,2042 inch] is.
Voorbeeld 2: Betrouwbaarheidsinterval voor het verschil in populatiegemiddelden in SAS
Stel dat we de volgende gegevensset hebben met de hoogte (in inches) van een willekeurige steekproef van planten die tot twee verschillende soorten behoren:
/*create dataset*/
data my_data2;
input Species $Height;
datalines ;
At 14
At 14
At 16
At 13
AT 12
At 17
At 15
At 14
At 15
At 13
B15
B14
B 19
B 19
B17
B 18
B20
B 19
B17
B15
;
run ;
/*view dataset*/
proc print data =my_data2;
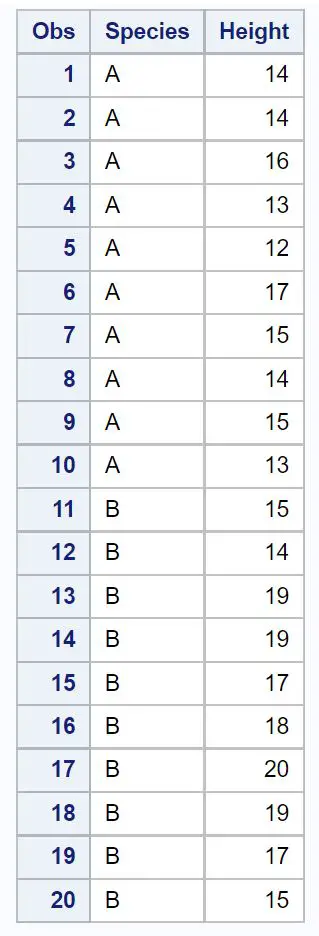
Stel dat we een betrouwbaarheidsniveau van 95% willen berekenen voor het verschil in gemiddelde populatiegrootte tussen soort A en soort B.
We kunnen hiervoor de volgende code in SAS gebruiken:
/*sort data by Species to ensure confidence interval is calculated correctly*/
proc sort data =my_data2;
by Species;
run ;
/*generate 95% confidence interval for difference in population means*/
proc ttest data =my_data2 alpha = 0.05 ;
class Species;
varHeight ;
run ;
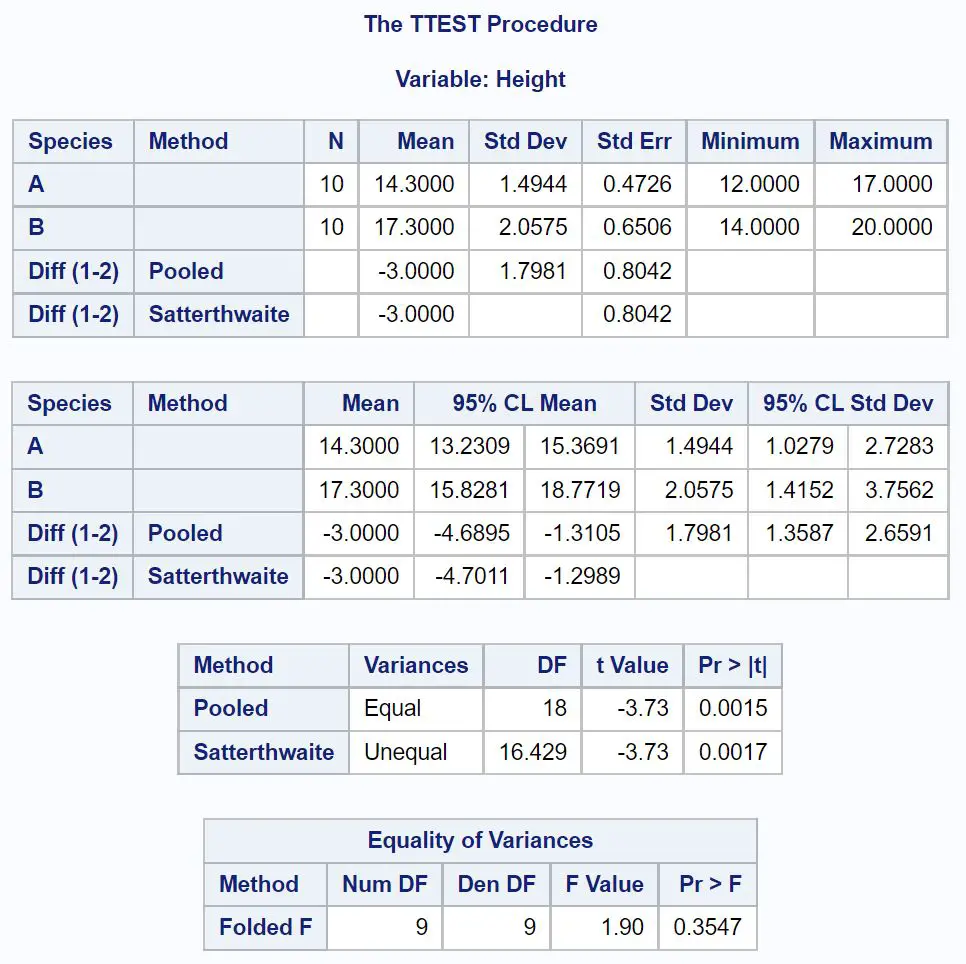
De eerste tabel waar we in het resultaat naar moeten kijken is Equality of Variances , waarin wordt getest of de variantie tussen elke steekproef gelijk is of niet.
Omdat de p-waarde in deze tabel niet kleiner is dan 0,05, kunnen we ervan uitgaan dat de verschillen tussen de twee groepen gelijk zijn.
We kunnen dus naar de lijn kijken die de gepoolde variantie gebruikt om het 95% betrouwbaarheidsinterval voor het verschil in de populatiegemiddelden te vinden.
Uit het resultaat kunnen we zien dat het 95% betrouwbaarheidsinterval voor het verschil tussen de populatiegemiddelden [-4,6895 inches, -1,1305 inches] is.
Dit vertelt ons dat we er 95% zeker van kunnen zijn dat het werkelijke verschil tussen de gemiddelde planthoogte van soort A en soort B tussen -4,6895 inch en -1,1305 inch ligt.
Omdat 0 niet in dit betrouwbaarheidsinterval ligt , geeft dit aan dat er een statistisch significant verschil bestaat tussen de gemiddelden van de twee populaties.
Aanvullende bronnen
In de volgende zelfstudies wordt uitgelegd hoe u andere veelvoorkomende taken in SAS kunt uitvoeren:
Hoe u een t-test met één monster uitvoert in SAS
Hoe u een t-test met twee steekproeven uitvoert in SAS
Een t-test met gepaarde monsters uitvoeren in SAS
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder