Hoe de indexc-functie in sas te gebruiken
U kunt de INDEXC- functie in SAS gebruiken om de positie te retourneren van de eerste keer dat een afzonderlijk teken in een tekenreeks voorkomt.
Deze functie gebruikt de volgende basissyntaxis:
INDEXC(bron, uittreksel)
Goud:
- bron : het kanaal dat moet worden geanalyseerd
- extract : De tekenreeks waarnaar in de bron moet worden gezocht
Het volgende voorbeeld laat zien hoe u deze functie in de praktijk kunt gebruiken.
Voorbeeld: gebruik van de INDEXC-functie in SAS
Stel dat we de volgende gegevensset in SAS hebben die een kolom met namen bevat:
/*create dataset*/
data original_data;
input name $25.;
datalines ;
Andy Lincoln Bernard
Michael Smith
Chad Simpson Arnolds
Derrick Smith Henrys
Eric Millerton Smith
Frank Giovanni Goode
;
run ;
/*view dataset*/
proc print data = original_data;
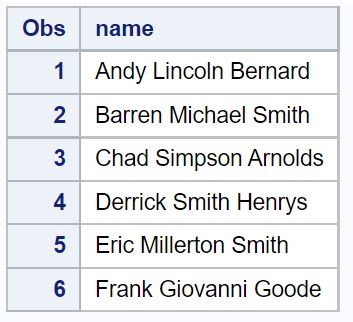
We kunnen de INDEXC- functie gebruiken om de positie te vinden van de eerste keer dat de tekens x , y of z voorkomen:
/*find position of first occurrence of either x, y or z in name*/
data new_data;
set original_data;
first_xyz = indexc (name, 'xyz');
run ;
/*view results*/
proc print data = new_data;
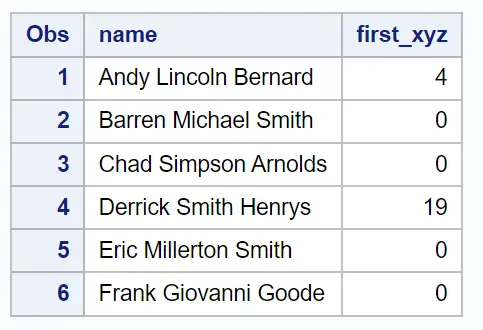
De nieuwe kolom genaamd first_xyz geeft de positie weer van de eerste keer dat de tekens x , y of z voorkomen in de naamkolom .
Als geen van deze drie tekens in de naamkolom voorkomt, retourneert de functie INDEXC eenvoudigweg de waarde 0 .
Uit het resultaat kunnen we bijvoorbeeld zien:
De positie van het eerste voorkomen van x, y of z in de eerste rij is positie 4 . We kunnen zien dat het teken op positie 4 in de eerste regel a y is.
De positie van de eerste keer dat x, y of z in de tweede rij voorkomt, is 0 , omdat geen van deze drie letters voorkomt in de naam van de tweede rij.
Enzovoort.
Het verschil tussen INDEX- en INDEXC-functies
De INDEX- functie in SAS retourneert de positie van de eerste keer dat een bepaalde subtekenreeks in een andere tekenreeks voorkomt.
Het volgende voorbeeld illustreert het verschil tussen de INDEX- en INDEXC- functies:
/*create new dataset*/
data new_data;
set original_data;
index_smith = index (name, 'Smith');
indexc_smith = indexc (name, 'Smith');
run ;
/*view new dataset*/
proc print data =new_data;
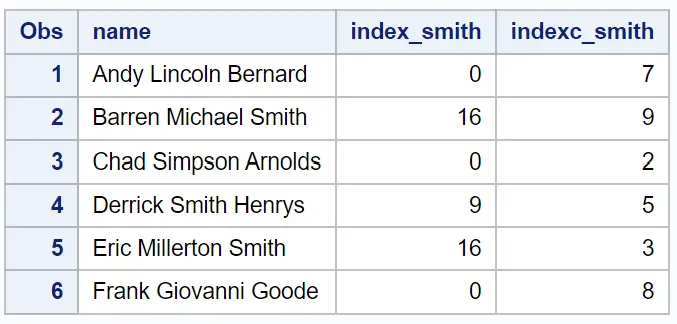
De kolom index_smith geeft de positie weer van het eerste exemplaar van de substring ‚Smith‘ in de naamkolom .
De kolom indexc_smith geeft de positie weer van de eerste keer dat de letters s , m , i , t of h voorkomen in de naamkolom .
Uit het resultaat kunnen we bijvoorbeeld zien:
De subtekenreeks ‚Smith‘ verschijnt nooit in de voornaam, dus index_smith retourneert een waarde van 0 .
De letter i verschijnt op de 7e positie van de voornaam, dus indexc_smith retourneert een waarde van 7 .
Enzovoort.
Aanvullende bronnen
In de volgende zelfstudies wordt uitgelegd hoe u andere veelvoorkomende functies in SAS kunt gebruiken:
Hoe de SUBSTR-functie in SAS te gebruiken
Hoe de COMPRESS-functie in SAS te gebruiken
Hoe de FIND-functie in SAS te gebruiken
Hoe de COALESCE-functie in SAS te gebruiken
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder