Proc cluster gebruiken in sas (met voorbeeld)
Clustering is een machine learning-techniek die probeert groepen observaties binnen een dataset te vinden.
Het doel is om clusters zo te vinden dat waarnemingen binnen elke cluster behoorlijk op elkaar lijken, terwijl waarnemingen in verschillende clusters behoorlijk van elkaar verschillen.
De eenvoudigste manier om te clusteren in SAS is door PROC CLUSTER te gebruiken.
Het volgende voorbeeld laat zien hoe u PROC CLUSTER in de praktijk kunt gebruiken.
Voorbeeld: PROC CLUSTER gebruiken in SAS
Laten we zeggen dat we de volgende dataset hebben met informatie over punten, assists en rebounds voor 20 verschillende basketbalspelers:
/*create dataset*/
data my_data;
input points assists rebounds;
datalines ;
18 3 15
20 3 14
19 4 14
14 5 10
14 4 8
15 7 14
20 8 13
28 7 9
30 6 5
31 9 4
35 12 11
33 14 6
29 9 5
25 9 5
25 4 3
27 3 8
29 4 12
30 12 7
19 5 6
23 11 5
;
run ;
/*view dataset*/
proc print data =my_data;
Laten we zeggen dat we een groepering willen uitvoeren om te proberen ‚clusters‘ van spelers met vergelijkbare statistieken te identificeren.
De volgende code laat zien hoe u PROC CLUSTER in SAS gebruikt om clustering uit te voeren:
/*perform clustering using points, assists and rebounds variables*/
proc cluster data =my_data method =average;
var points assists rebounds;
run ;
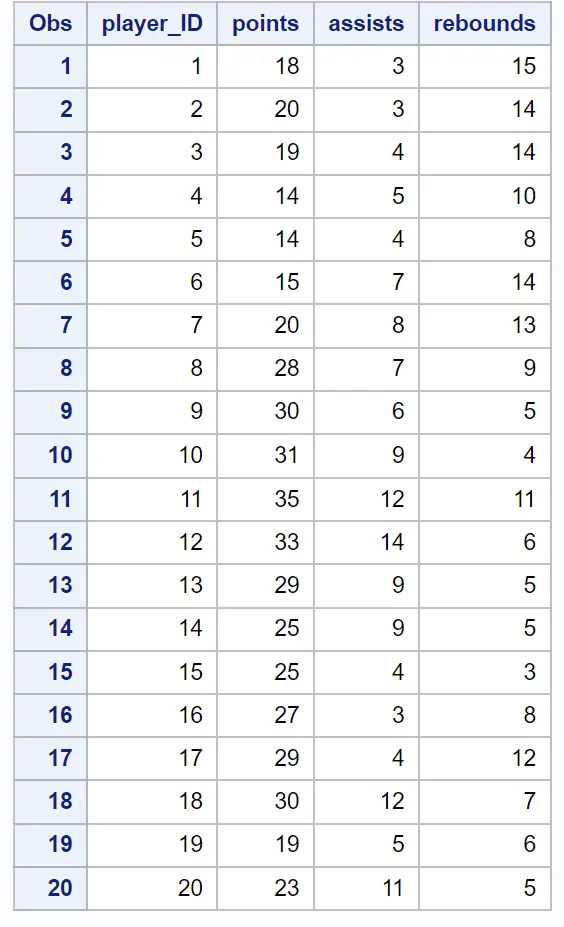
De eerste tabellen met het resultaat geven informatie over hoe de clustering werd uitgevoerd:
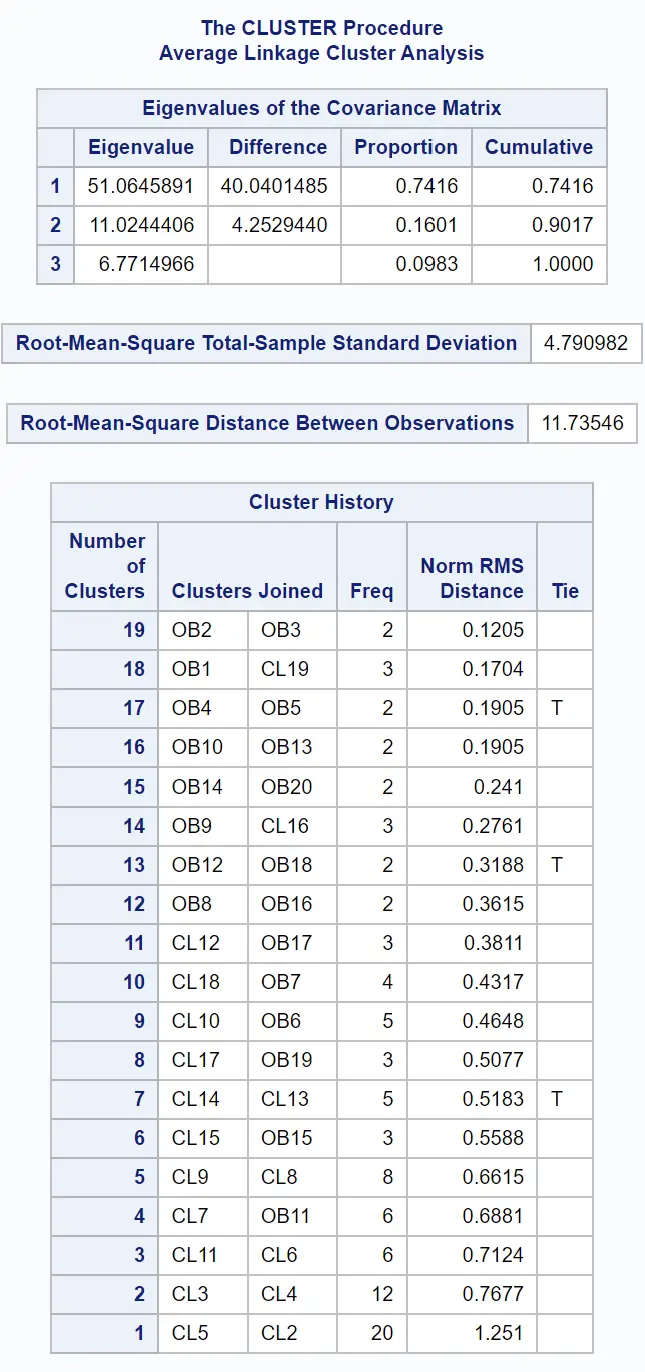
Er wordt ook een dendrogram gemaakt, zodat we de gelijkenis tussen waarnemingen in de dataset visueel kunnen inspecteren:
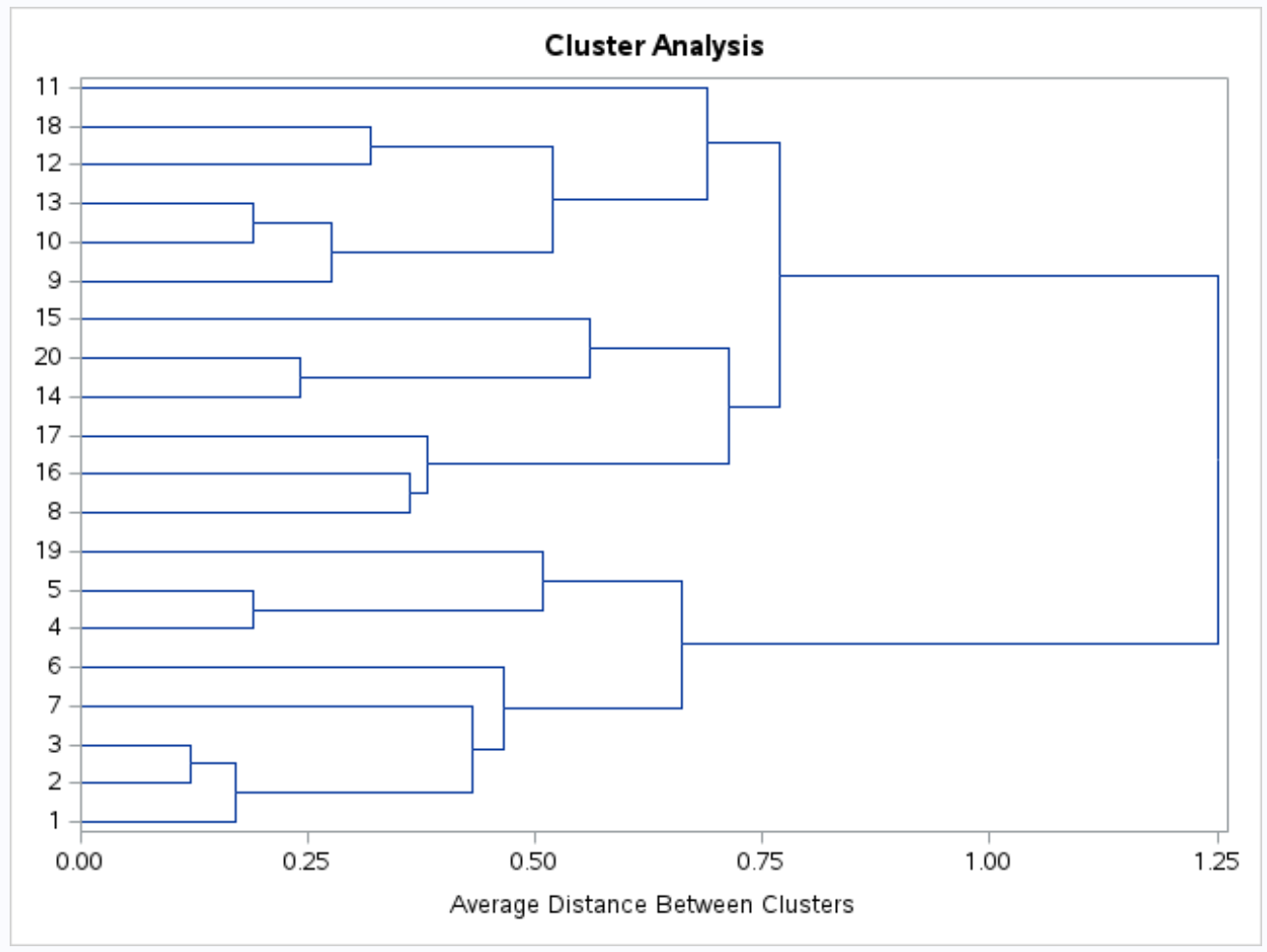
De y-as toont individuele waarnemingen en de x-as toont de gemiddelde afstand tussen clusters.
Als we naar dit dendrogram kijken, lijkt het erop dat de waarnemingen uiteraard in drie groepen vallen:
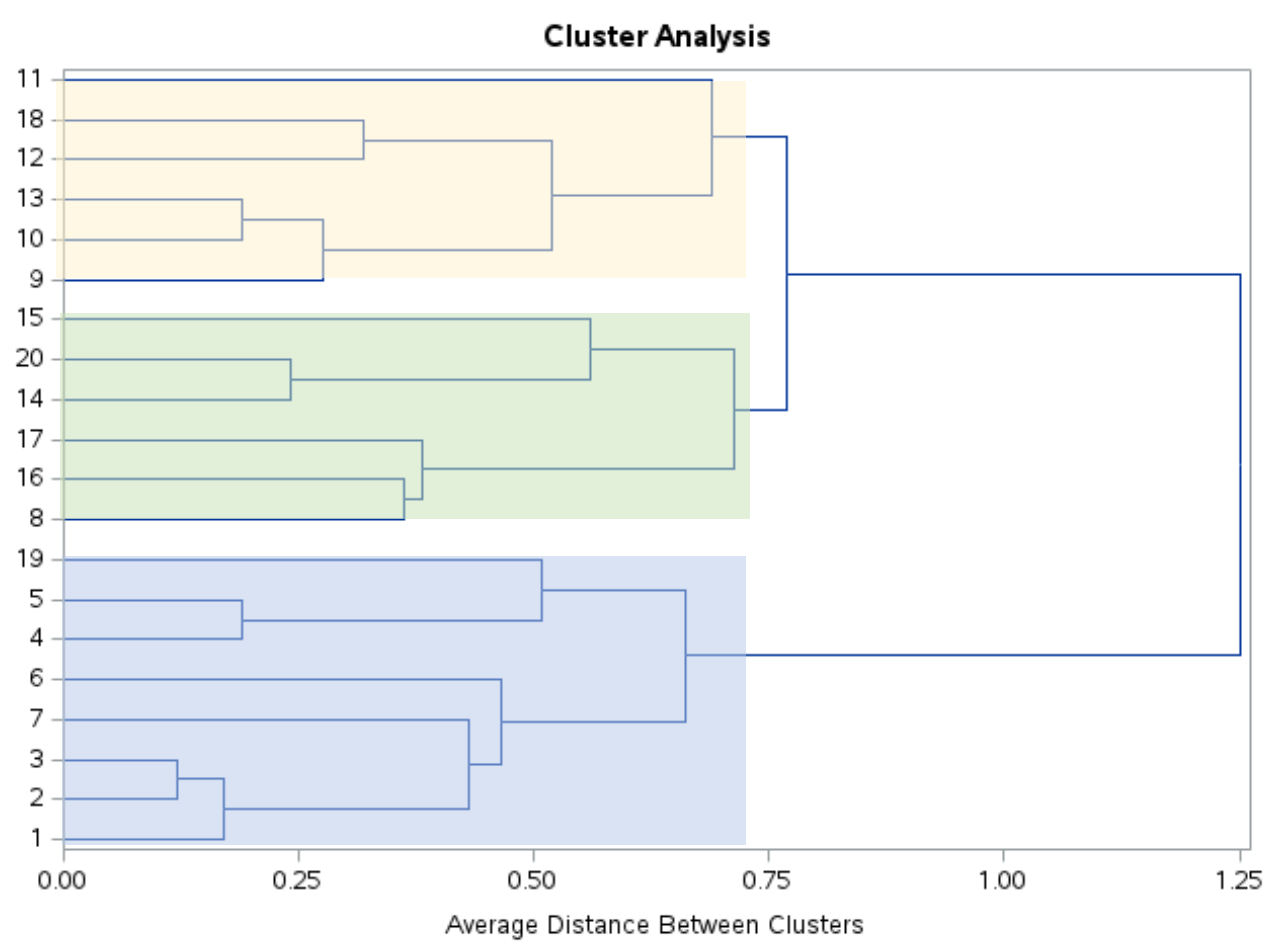
We kunnen vervolgens de PROC TREE -instructie met ncl=3 gebruiken om SAS te vertellen elke waarneming in de oorspronkelijke dataset toe te wijzen aan een van de drie clusters:
/*assign each observation to one of three clusters*/
proc tree data =clustd noprint ncl =3 out =clusts;
copy points assists rebounds;
id player_ID;
run ;
proc sort ;
by cluster;
run ;
/*view cluster assignments*/
proc print data = clusters;
id player_ID;
run ;
De resulterende dataset toont elk van de oorspronkelijke waarnemingen samen met het cluster waartoe ze behoren:
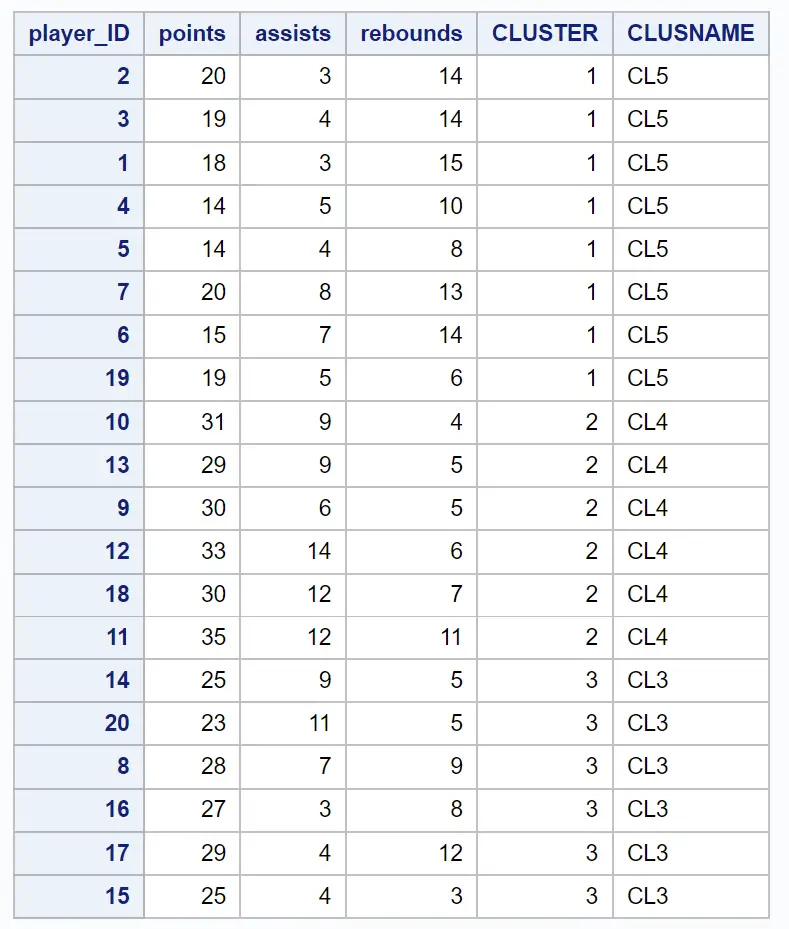
We kunnen bijvoorbeeld zien: dat spelers met ID’s 2, 3, 1, 4, 5, 7, 6 en 19 allemaal tot cluster 1 behoren.
Dit vertelt ons dat deze acht spelers “vergelijkbaar” zijn in termen van punten, assists en rebounds-variabelen.
Opmerking : voor dit voorbeeld hebben we ervoor gekozen om middeling te gebruiken als koppelingsmethode voor clustering. Raadpleeg de SAS-documentatie voor een volledige lijst met andere bindingsmethoden die u kunt gebruiken.
Aanvullende bronnen
In de volgende zelfstudies wordt uitgelegd hoe u andere veelvoorkomende taken in SAS kunt uitvoeren:
Hoofdcomponentanalyse uitvoeren in SAS
Hoe u meerdere lineaire regressie uitvoert in SAS
Hoe logistische regressie uit te voeren in SAS
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder