Hoe de variatiecoëfficiënt in spss te berekenen
De variatiecoëfficiënt is een manier om de spreiding van waarden in een dataset ten opzichte van het gemiddelde te meten. Het wordt als volgt berekend:
Variatiecoëfficiënt = σ / μ
Goud:
σ = standaardafwijking van de dataset
μ = gemiddelde van de dataset
In deze tutorial wordt uitgelegd hoe je de variatiecoëfficiënt van een dataset in SPSS kunt berekenen.
Voorbeeld: variatiecoëfficiënt in SPSS
Stel dat we de volgende dataset hebben die het jaarinkomen (in duizenden) van 15 mensen weergeeft:
Gebruik de volgende stappen om de variatiecoëfficiënt voor deze dataset in SPSS te berekenen:
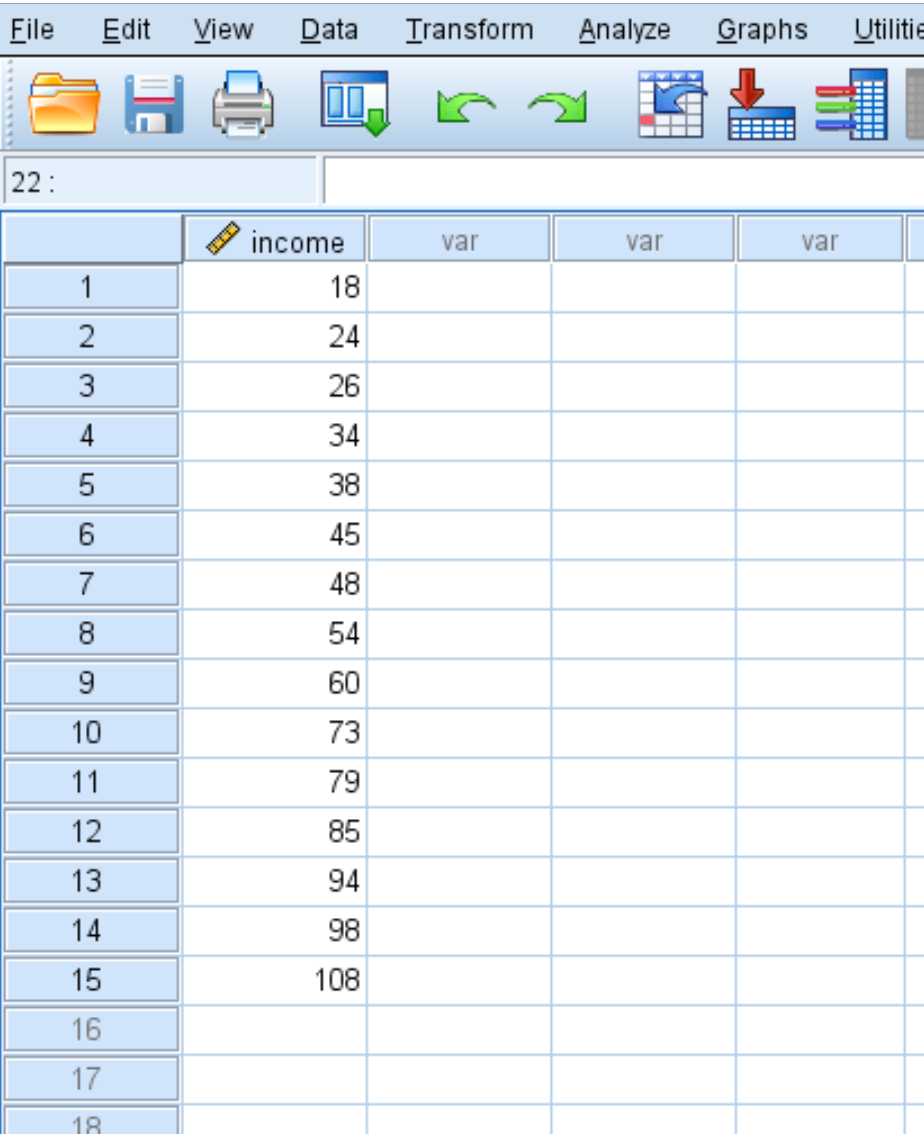
Stap 1: Maak een kolom van 1.
Eerst moeten we een alles-1-kolom maken naast de oorspronkelijke gegevensset:
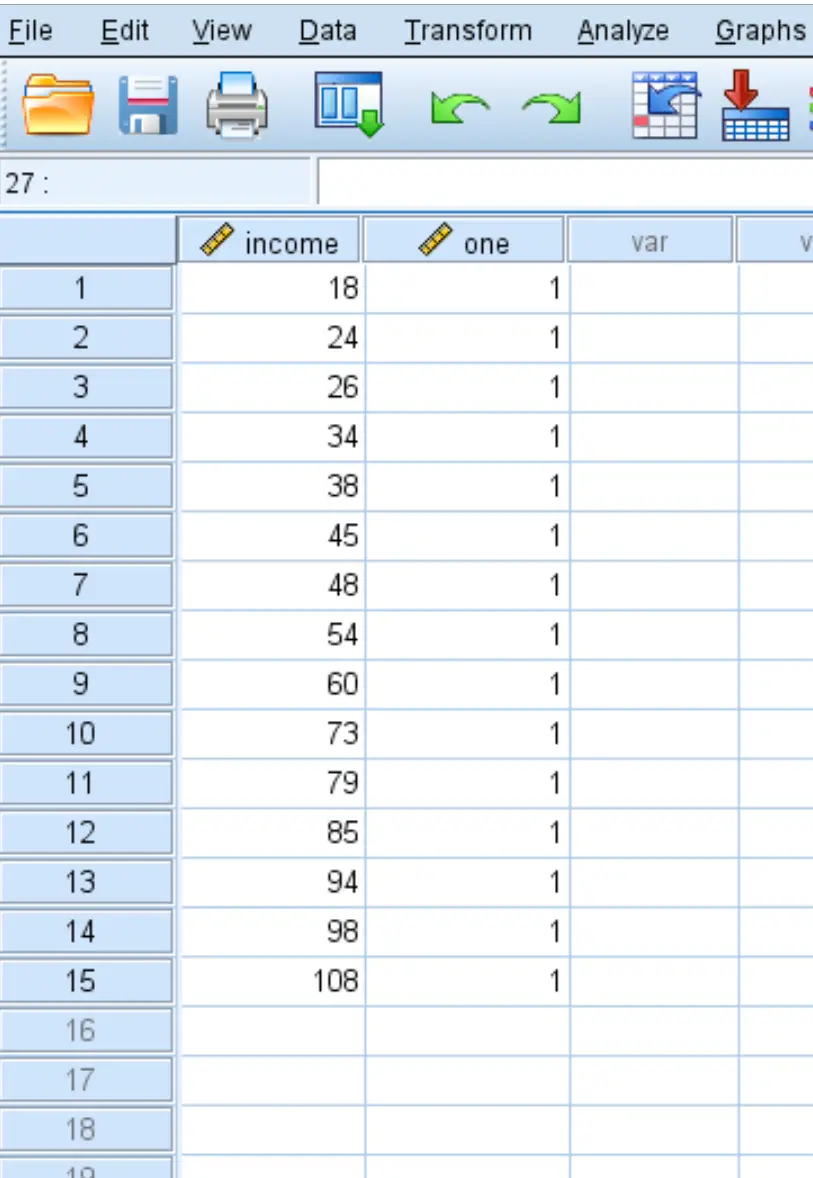
Stap 2: Bereken de variatiecoëfficiënt.
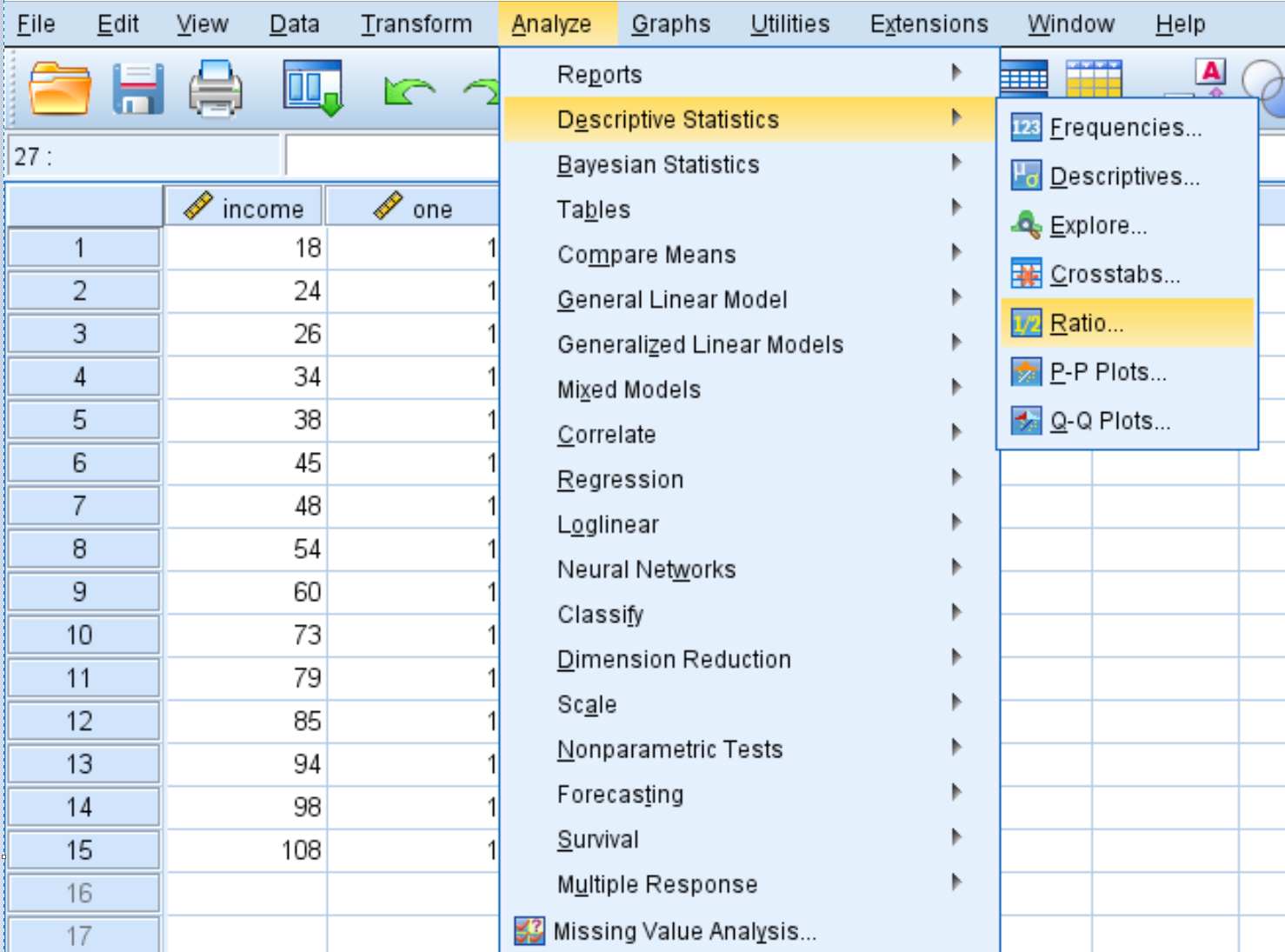
Klik vervolgens op het tabblad Analyseren , vervolgens op Beschrijvende statistieken en vervolgens op Ratio :
In het nieuwe venster dat verschijnt, sleept u de inkomensvariabele naar het vak met de naam Teller en sleept u de variabele naar het vak met de naam Noemer:
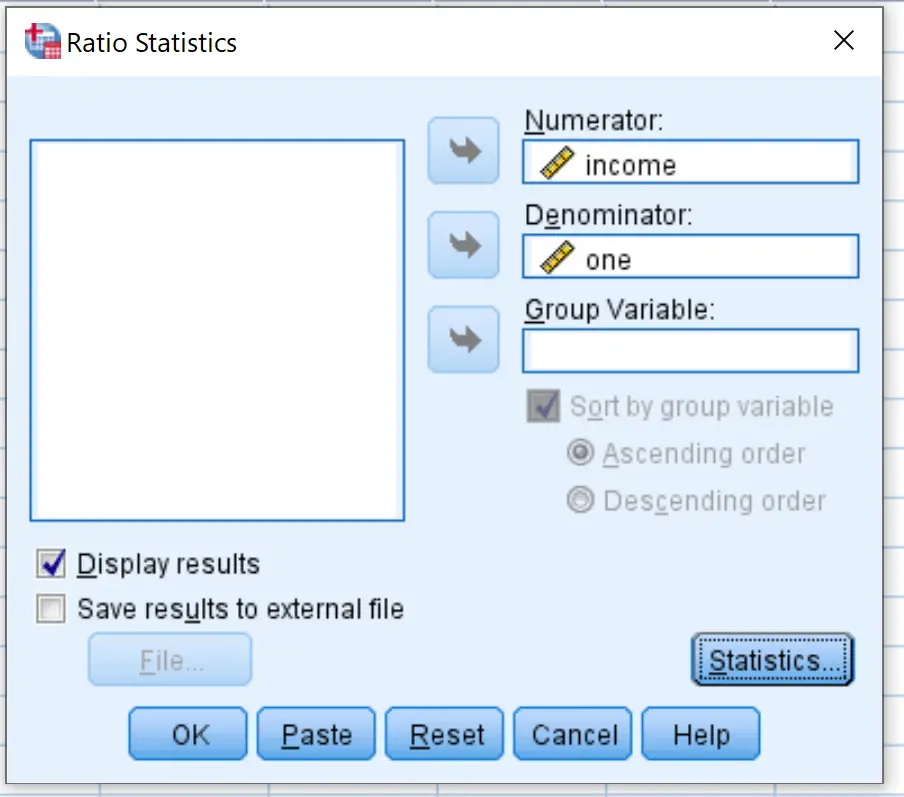
Klik vervolgens op Statistieken . Zorg ervoor dat de vakjes naast Gemiddeld , Standaardafwijking en Gecentreerd VOC-gemiddelde zijn aangevinkt. Klik vervolgens op Doorgaan .
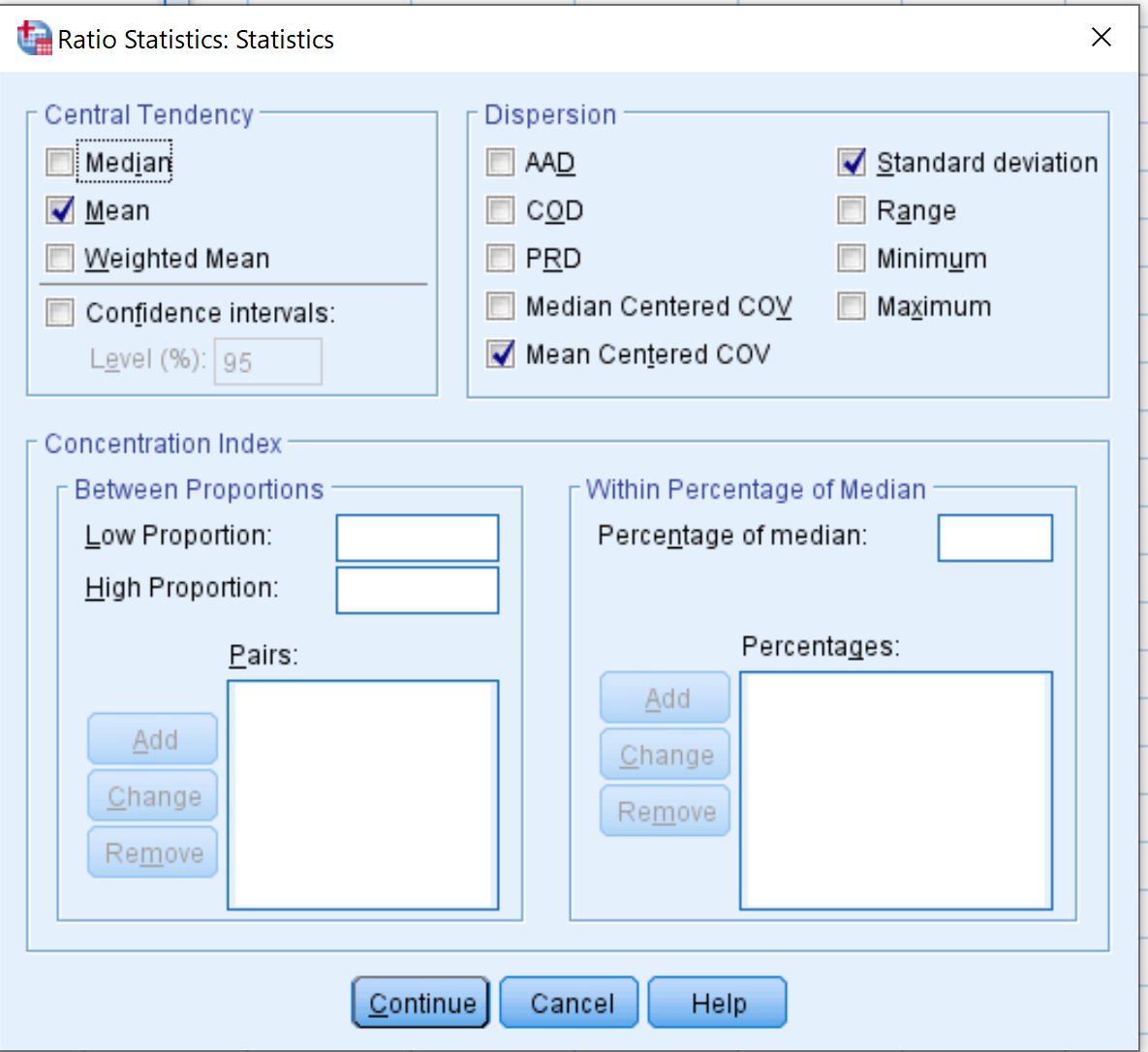
Klik ten slotte op OK .
Stap 3: Interpreteer de variatiecoëfficiënt.
Zodra u op OK klikt, wordt de variatiecoëfficiënt voor deze dataset weergegeven:
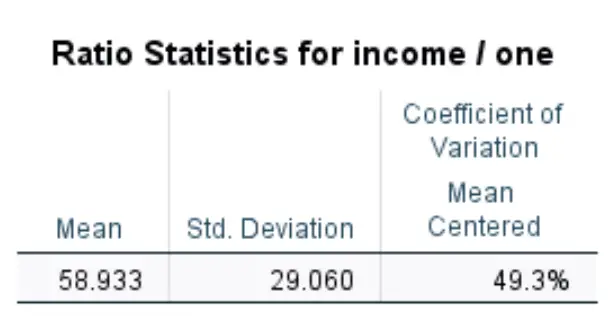
We kunnen zien dat de variatiecoëfficiënt voor deze dataset 49,3% bedraagt. Dit werd berekend met behulp van de volgende formule:
CV = σ / μ * 100 = (29.060/58.933) * 100 = 49,3% .
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder