Standaardisatie of normalisatie: wat is het verschil?
Standaardisatie en normalisatie zijn twee manieren om de grootte van gegevens te wijzigen.
Normalisatie schaalt een dataset op zodat deze een gemiddelde van 0 en een standaarddeviatie van 1 heeft. Om dit te doen, wordt de volgende formule gebruikt:
x nieuw = (x ik – x ) / s
Goud:
- x i : de i- de waarde van de dataset
- x : De steekproefgemiddelden
- s : de standaarddeviatie van het monster
Normalisatie past de grootte van een dataset aan, zodat elke waarde tussen 0 en 1 ligt. Dit gebeurt met behulp van de volgende formule:
x nieuw = (x i – x min ) / (x max – x min )
Goud:
- x i : de i- de waarde van de dataset
- x min : De minimumwaarde in de gegevensset
- x max : De maximale waarde in de gegevensset
De volgende voorbeelden laten zien hoe u een dataset in de praktijk kunt standaardiseren en normaliseren.
Voorbeeld: gegevens standaardiseren
Stel dat we de volgende dataset hebben:
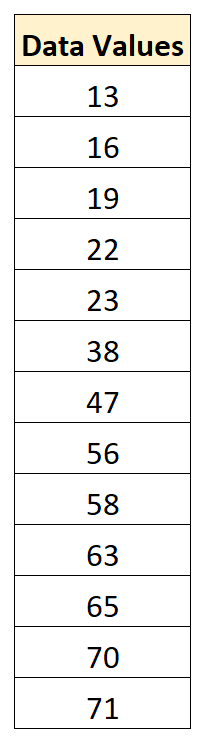
De gemiddelde waarde in de dataset is 43,15 en de standaardafwijking is 22,13.
Om de eerste waarde van 13 te normaliseren, zouden we de eerder gedeelde formule toepassen:
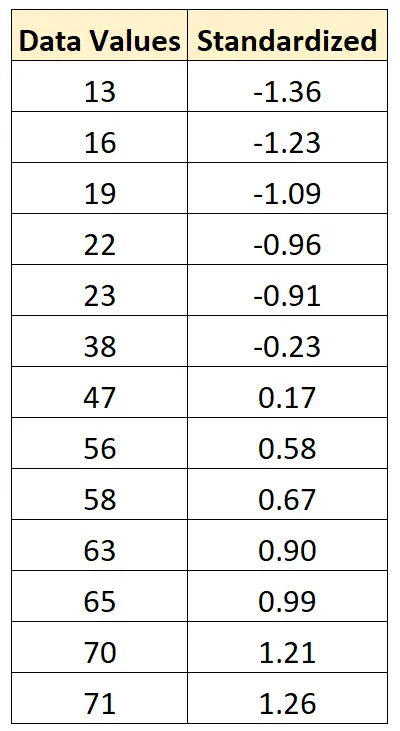
- x nieuw = (x i – x ) / s = (13 – 43,15) / 22,13 = -1,36
Om de tweede waarde van 16 te normaliseren, zouden we dezelfde formule gebruiken:
- x nieuw = (x i – x ) / s = (16 – 43,15) / 22,13 = -1,23
Om de derde waarde van 19 te normaliseren, zouden we dezelfde formule gebruiken:
- x nieuw = (x i – x ) / s = (19 – 43,15) / 22,13 = -1,09
We kunnen exact dezelfde formule gebruiken om elke waarde in de originele dataset te standaardiseren:
Voorbeeld: gegevens normaliseren
Stel opnieuw dat we de volgende gegevensset hebben:
De minimumwaarde in de dataset is 13 en de maximumwaarde is 71.
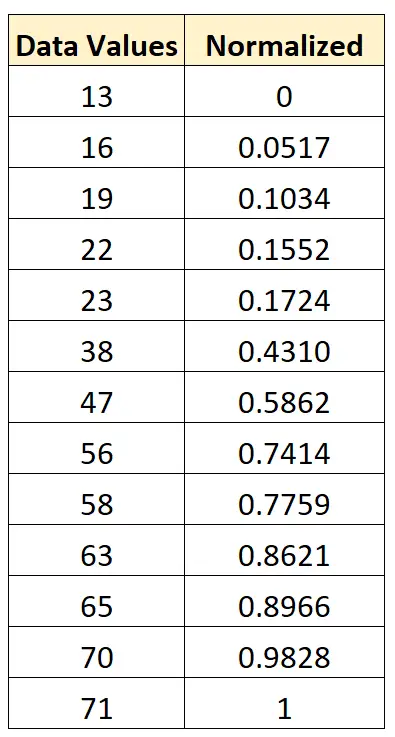
Om de eerste waarde van 13 te normaliseren, zouden we de eerder gedeelde formule toepassen:
- x nieuw = (x ik – x min ) / (x max – x min ) = (13 – 13) / (71 – 13) = 0
Om de tweede waarde van 16 te normaliseren, zouden we dezelfde formule gebruiken:
- x nieuw = (x i – x min ) / (x max – x min ) = (16 – 13) / (71 – 13) = 0,0517
Om de derde waarde van 19 te normaliseren, zouden we dezelfde formule gebruiken:
- x nieuw = (x i – x min ) / (x max – x min ) = (19 – 13) / (71 – 13) = 0,1034
We kunnen exact dezelfde formule gebruiken om elke waarde in de originele dataset tussen 0 en 1 te normaliseren:
Standaardisatie of normalisatie: wanneer moet je ze gebruiken?
Normaal gesproken normaliseren we gegevens wanneer we een soort analyse uitvoeren waarbij we meerdere variabelen op verschillende schalen laten meten en we willen dat elk van de variabelen hetzelfde bereik heeft.
Dit voorkomt dat één variabele ongepaste invloed heeft, vooral als deze in verschillende eenheden wordt gemeten (dat wil zeggen als de ene variabele in inches en de andere in yards wordt gemeten).
Aan de andere kant normaliseren we gegevens doorgaans als we willen weten hoeveel standaardafwijkingen elke waarde in een dataset van het gemiddelde afwijkt.
We hebben bijvoorbeeld een lijst met examenscores voor 500 leerlingen op een bepaalde school en we willen graag weten hoeveel standaardafwijkingen elke examenscore heeft van de gemiddelde score.
In dit geval zouden we de onbewerkte gegevens kunnen normaliseren om deze informatie te kennen. Een gestandaardiseerde score van 1,26 zou ons dan vertellen dat de examenscore van deze specifieke student 1,26 standaardafwijkingen boven de gemiddelde examenscore ligt.
Of u nu besluit uw gegevens te normaliseren of te standaardiseren, houd de volgende punten in gedachten:
- Een genormaliseerde dataset zal altijd waarden tussen 0 en 1 hebben.
- Een gestandaardiseerde dataset heeft een gemiddelde van 0 en een standaardafwijking van 1, maar er is geen specifieke boven- of ondergrens voor de maximale en minimale waarden.
Afhankelijk van uw specifieke scenario kan het zinvoller zijn om de gegevens te normaliseren of te standaardiseren.
Aanvullende bronnen
In de volgende tutorials wordt uitgelegd hoe u gegevens in verschillende statistische software kunt standaardiseren en normaliseren:
Hoe gegevens in R te normaliseren
Hoe gegevens in Excel te normaliseren
Hoe gegevens in Python te normaliseren
Hoe gegevens in R te standaardiseren
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder