Wat is de standaardfout van de schatting? (definitie & #038; voorbeeld)
De standaardfout van de schatting is een manier om de nauwkeurigheid van voorspellingen van een regressiemodel te meten.
Vaak opgemerkt σ est , wordt het als volgt berekend:
σ is = √ Σ(y – ŷ) 2 /n
Goud:
- y: De waargenomen waarde
- ŷ: De voorspelde waarde
- n: Het totale aantal waarnemingen
De standaardfout van de schatting geeft ons een idee van hoe goed een regressiemodel bij een dataset past. Speciaal:
- Hoe kleiner de waarde, hoe beter de pasvorm.
- Hoe groter de waarde, hoe slechter de pasvorm.
Voor een regressiemodel met een kleine standaardfout van de schatting worden de gegevenspunten strak geclusterd rond de geschatte regressielijn:
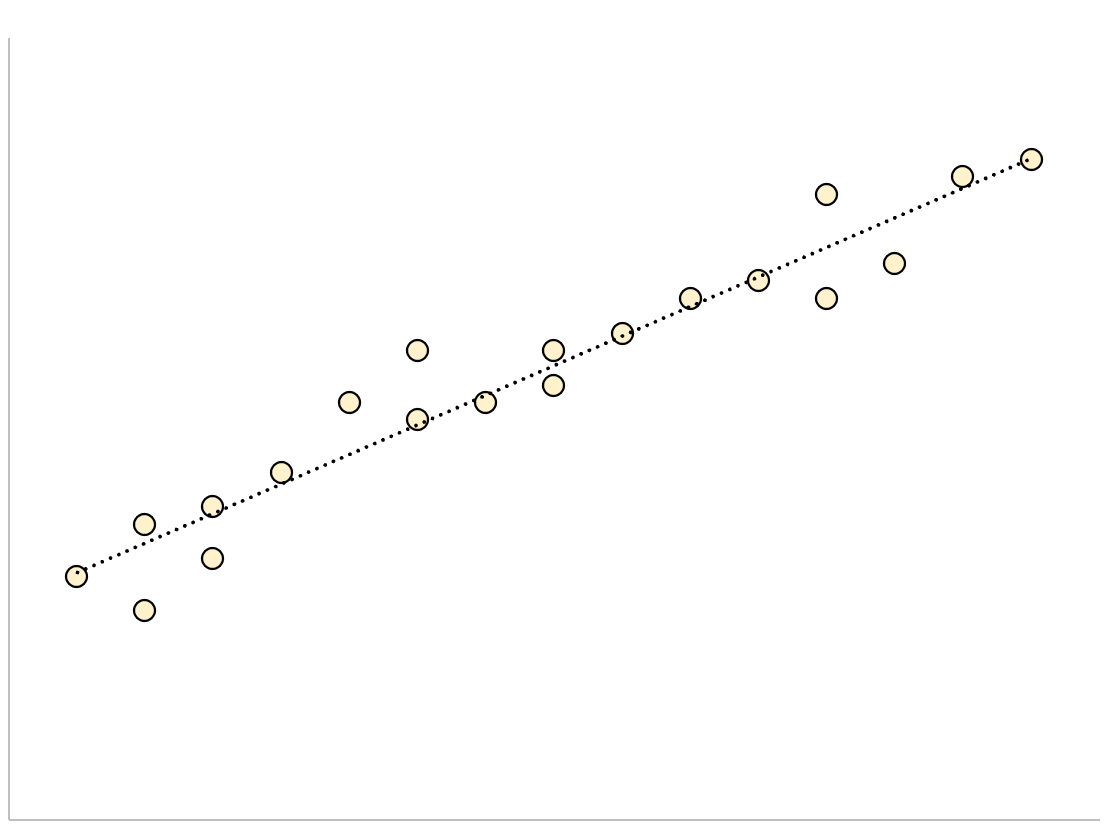
Omgekeerd zullen voor een regressiemodel met een grote standaardschattingsfout de gegevenspunten losser verspreid zijn rond de regressielijn:
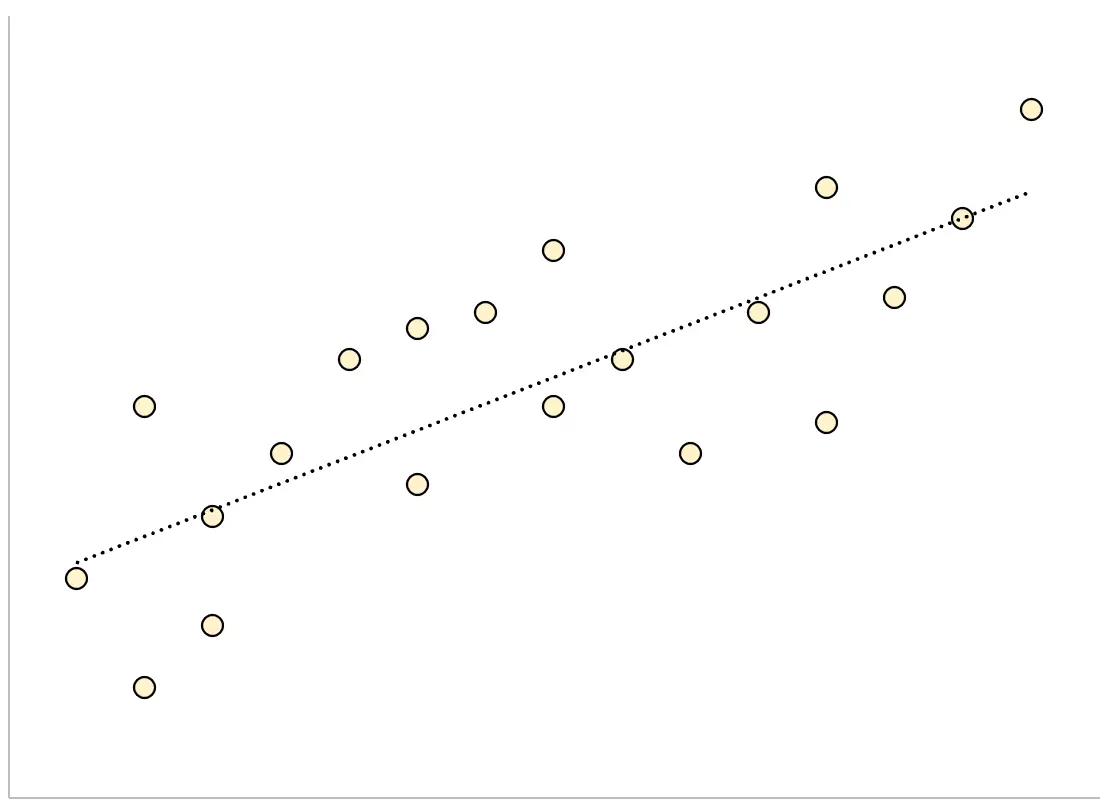
In het volgende voorbeeld ziet u hoe u de standaardfout van de schatting voor een regressiemodel in Excel berekent en interpreteert.
Voorbeeld: standaardschattingsfout in Excel
Gebruik de volgende stappen om de standaardfout van de schatting voor een regressiemodel in Excel te berekenen.
Stap 1: Voer de gegevens in
Voer eerst de gegevenssetwaarden in:
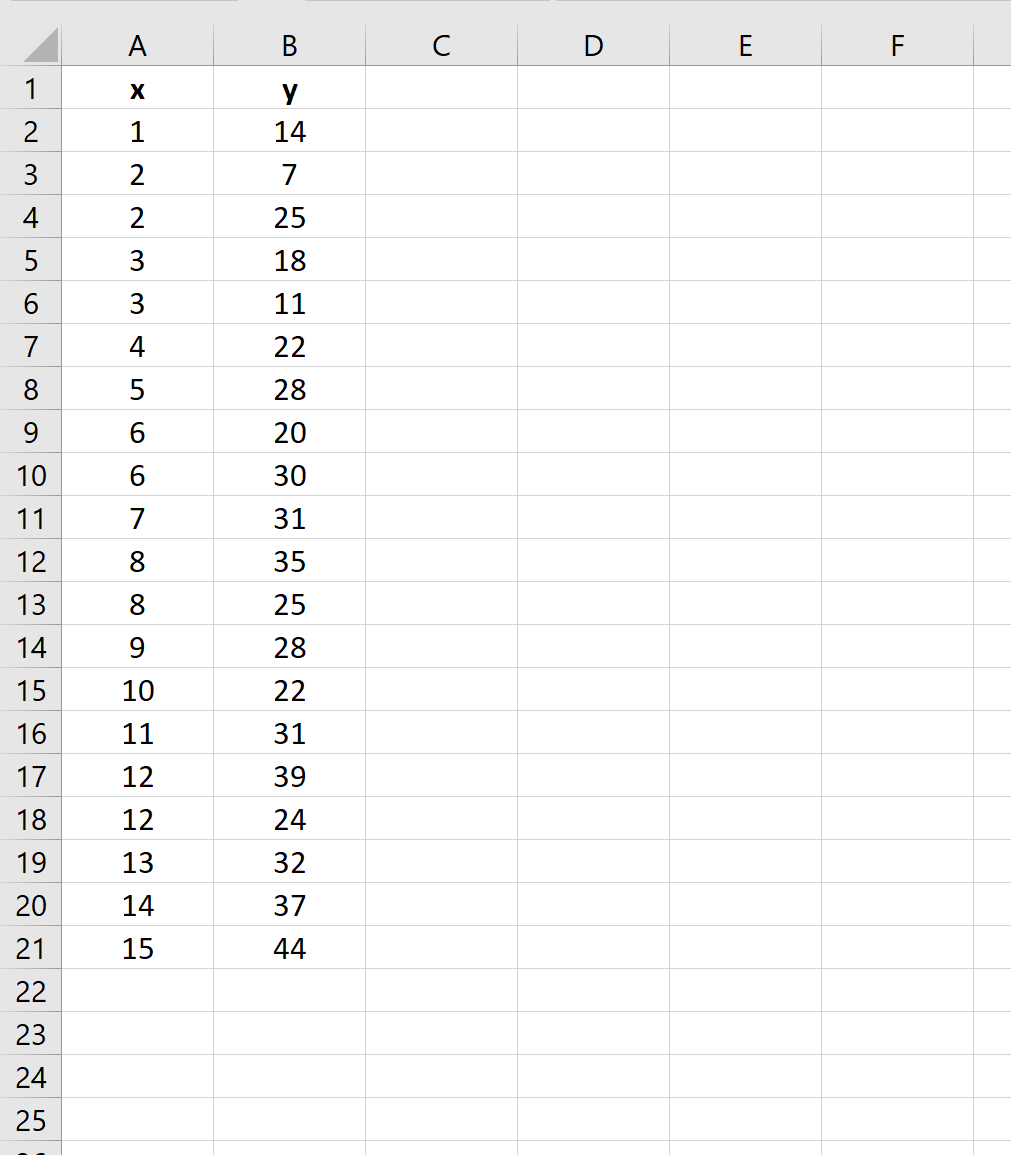
Stap 2: Voer lineaire regressie uit
Klik vervolgens op het tabblad Gegevens op het bovenste lint. Klik vervolgens op de optie Gegevensanalyse in de groep Analyseren .
Als u deze optie niet ziet, moet u eerst Analysis ToolPak laden .
In het nieuwe venster dat verschijnt, klikt u op Regressie en vervolgens op OK .
Geef in het nieuwe venster dat verschijnt de volgende informatie op:
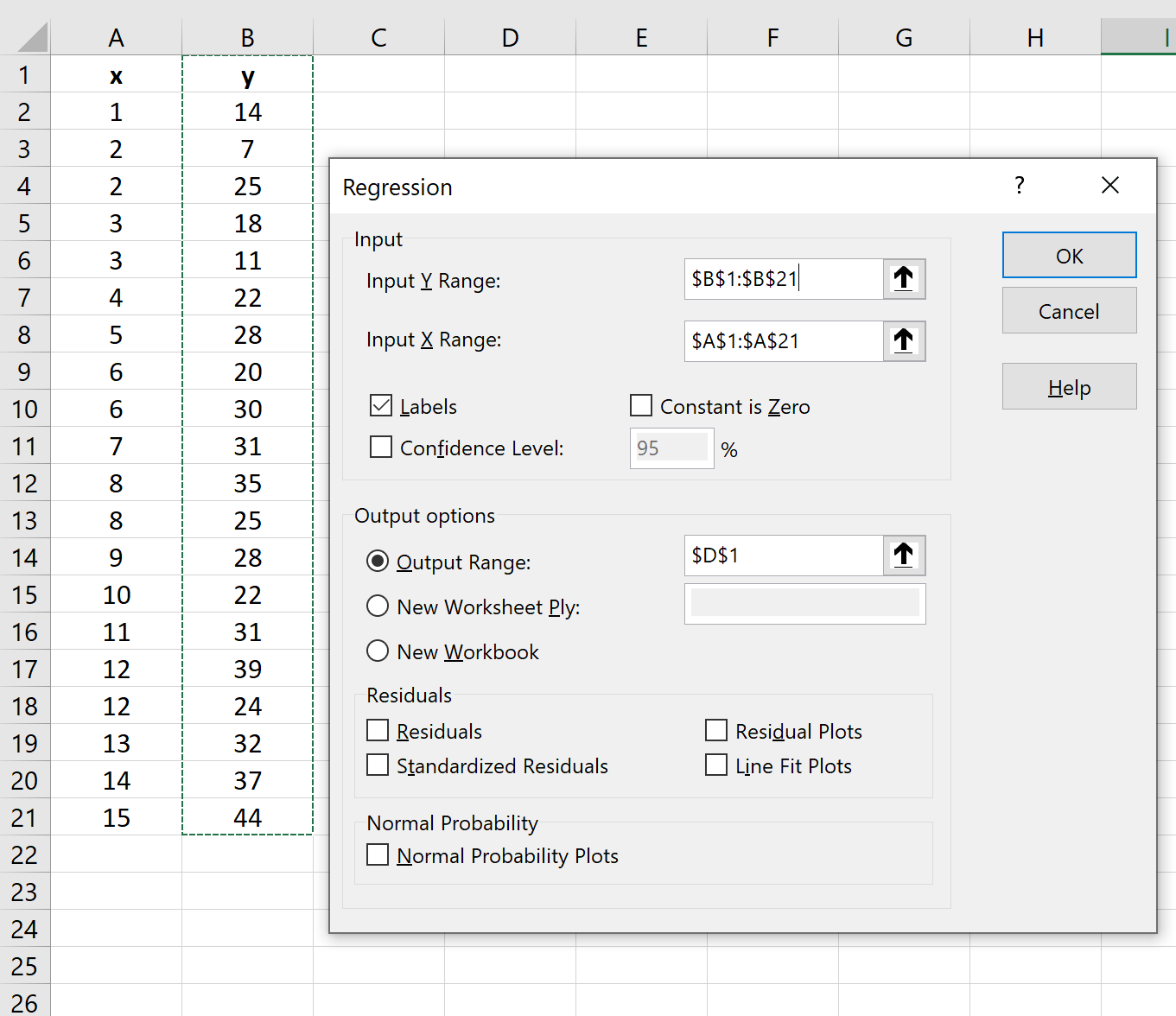
Zodra u op OK klikt, verschijnt het regressieresultaat:
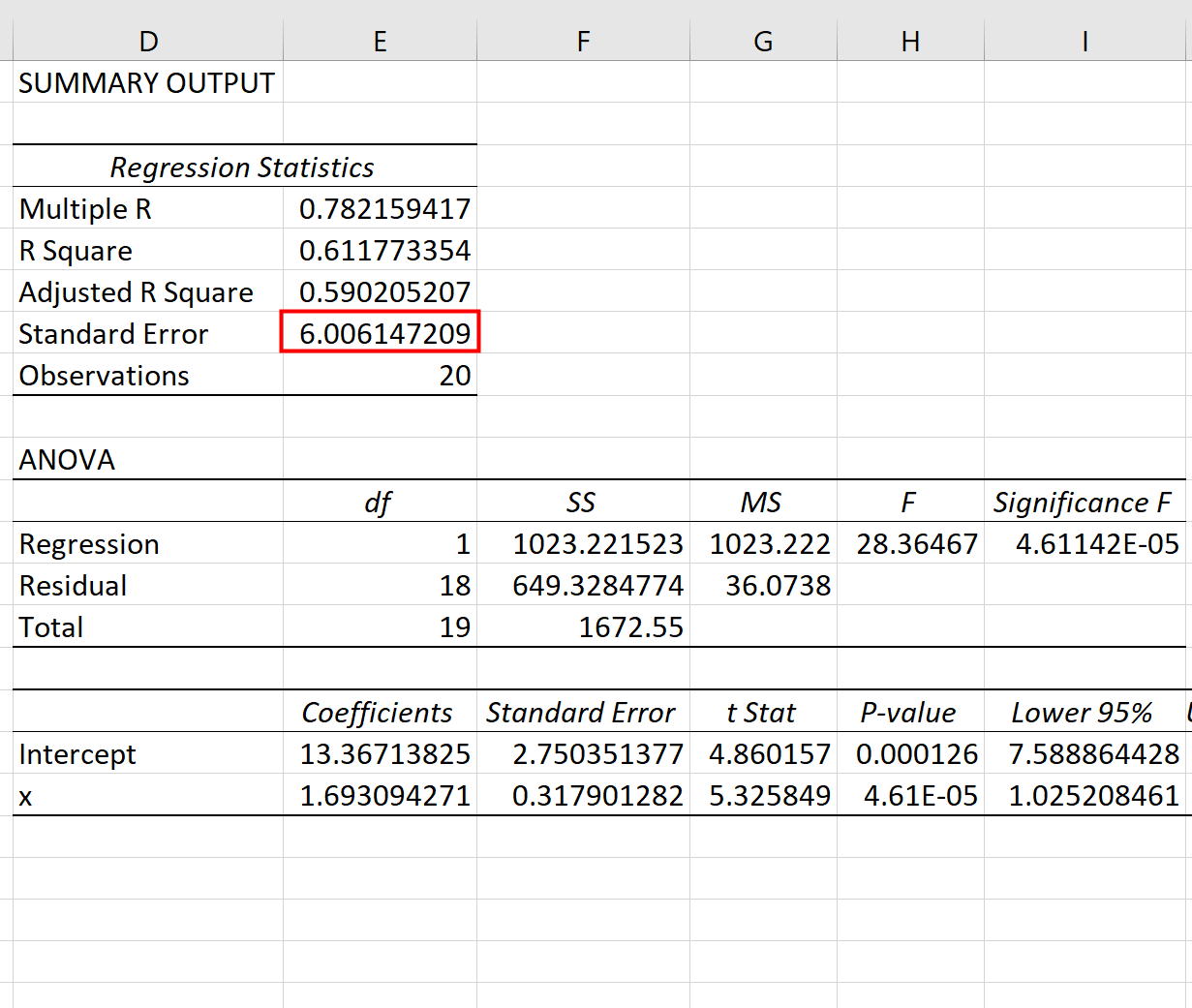
We kunnen de coëfficiënten uit de regressietabel gebruiken om de geschatte regressievergelijking samen te stellen:
ŷ = 13,367 + 1,693(x)
En we kunnen zien dat de standaardfout van de schatting voor dit regressiemodel 6,006 blijkt te zijn. In eenvoudige bewoordingen vertelt dit ons dat het gemiddelde datapunt 6,006 eenheden verwijderd is van de regressielijn.
We kunnen de geschatte regressievergelijking en de standaardfout van de schatting gebruiken om een betrouwbaarheidsinterval van 95% te construeren voor de voorspelde waarde van een bepaald gegevenspunt.
Stel bijvoorbeeld dat x gelijk is aan 10. Met behulp van de geschatte regressievergelijking voorspellen we dat y gelijk zou zijn aan:
ŷ = 13,367 + 1,693*(10) = 30,297
En we kunnen het 95% betrouwbaarheidsinterval voor deze schatting verkrijgen met behulp van de volgende formule:
- 95% BI = [ŷ – 1,96*σ is , ŷ + 1,96*σ is ]
Voor ons voorbeeld zou het 95%-betrouwbaarheidsinterval als volgt worden berekend:
- 95% BI = [ŷ – 1,96*σ is , ŷ + 1,96*σ is ]
- 95% BI = [30,297 – 1,96*6,006, 30,297 + 1,96*6,006]
- 95% BI = [18.525, 42.069]
Aanvullende bronnen
Hoe u eenvoudige lineaire regressie uitvoert in Excel
Hoe u meerdere lineaire regressies uitvoert in Excel
Hoe u een restplot in Excel maakt
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder