Statistische formules
Hier vindt u de belangrijkste statistische formules. We laten u ook gekoppeld aan onze artikelen waarin u voorbeelden van de toepassing van elke statistische formule kunt zien en bovendien kunt u een online rekenmachine gebruiken, zodat u de berekeningen niet hoeft uit te voeren en het resultaat van de formule direct kent.
Formules voor statistische metingen van centrale tendens
Half
Om het gemiddelde te berekenen, telt u alle waarden bij elkaar op en deelt u deze door het totale aantal gegevens. De formule voor het gemiddelde is daarom als volgt:

In de statistiek wordt het gemiddelde ook wel het rekenkundig gemiddelde of gemiddelde genoemd.
Mediaan
De mediaan is de middelste waarde van alle gegevens, gerangschikt van klein naar groot. Met andere woorden: de mediaan verdeelt de geordende dataset in twee gelijke delen.
De berekening van de mediaan hangt af van het feit of het totale aantal gegevens even of oneven is:
- Als het totale aantal gegevens oneven is, is de mediaan de waarde die precies in het midden van de gegevens valt. Dat wil zeggen de waarde die zich op positie (n+1)/2 van de gesorteerde gegevens bevindt.
- Als het totale aantal gegevenspunten even is, is de mediaan het gemiddelde van de twee gegevenspunten in het midden. Dat wil zeggen het rekenkundig gemiddelde van de waarden die gevonden worden op posities n/2 en n/2+1 van de geordende data.


Goud

is het totale aantal gegevens in de steekproef en het symbool Me geeft de mediaan aan.
Mode
In de statistiek is de modus de waarde in de dataset die de hoogste absolute frequentie heeft, dat wil zeggen dat de modus de meest herhaalde waarde in een dataset is.
Daarom is er geen specifieke formule voor de modus, maar om de modus van een statistische gegevensset te berekenen, telt u eenvoudigweg het aantal keren dat elk gegevenselement in de steekproef voorkomt, en de gegevens die het meest worden herhaald, zullen de modus zijn.
Er kan ook worden gezegd dat de modus een statistische modus of modale waarde is.
Formules voor statistische metingen van spreiding
Standaardafwijking
De standaarddeviatie, ook wel de standaarddeviatie genoemd, is gelijk aan de vierkantswortel van de som van de kwadraten van de afwijkingen van de gegevensreeks gedeeld door het totale aantal waarnemingen.
Daarom is de formule voor standaarddeviatie :

Variantie
De variantie is gelijk aan de som van de kwadraten van de residuen over het totale aantal waarnemingen. De formule voor deze statistische metriek is daarom als volgt:

Goud:
-

is de willekeurige variabele waarvoor u de variantie wilt berekenen.
-

is de gegevenswaarde

.
-
is het totale aantal waarnemingen.
-

is het gemiddelde van de willekeurige variabele
.
Variatiecoëfficiënt
In de statistiek is de variatiecoëfficiënt een maatstaf voor de spreiding die wordt gebruikt om de spreiding van een gegevensset ten opzichte van het gemiddelde te bepalen. De variatiecoëfficiënt wordt berekend door de standaarddeviatie van de gegevens te delen door het gemiddelde en vervolgens te vermenigvuldigen met 100 om de waarde als een percentage uit te drukken.

Netjes
Statistisch bereik is een spreidingsmaatstaf die het verschil aangeeft tussen de maximale waarde en de minimale waarde van gegevens in een steekproef. Om de omvang van een populatie of statistische steekproef te berekenen, moet daarom de maximale waarde worden afgetrokken van de minimumwaarde.

Interkwartielbereik
Het interkwartielbereik , ook wel interkwartielbereik genoemd, is een maatstaf voor de statistische spreiding die het verschil tussen het derde en eerste kwartiel aangeeft.
Om het interkwartielbereik van een statistische dataset te berekenen, moet u daarom eerst het derde en eerste kwartiel vinden en deze vervolgens aftrekken.

gemiddeld verschil
De gemiddelde afwijking , ook wel de gemiddelde absolute afwijking genoemd, is het gemiddelde van de absolute afwijkingen. De gemiddelde afwijking is daarom gelijk aan de som van de afwijkingen van elk gegevensitem van het rekenkundig gemiddelde gedeeld door het totale aantal gegevensitems.

Formules voor statistische positiemetingen
kwartielen
In de statistieken zijn kwartielen de drie waarden die een reeks geordende gegevens in vier gelijke delen verdelen. Het eerste, tweede en derde kwartiel vertegenwoordigen dus respectievelijk 25%, 50% en 75% van alle statistische gegevens.
Kwartielen worden weergegeven door een hoofdletter Q en de kwartielindex, dus het eerste kwartiel is Q 1 , het tweede kwartiel is Q 2 en het derde kwartiel is Q 3 .
De kwartielformule is:

Let op: deze formule vertelt ons de positie van het kwartiel, niet de waarde van het kwartiel. Het kwartiel zijn de gegevens die zich bevinden op de positie die door de formule wordt verkregen.
Soms geeft het resultaat van deze formule ons echter een decimaal getal. We moeten daarom twee gevallen onderscheiden, afhankelijk van of het resultaat een decimaal getal is of niet:
- Als het resultaat van de formule een getal zonder decimaal deel is, zijn het kwartiel de gegevens die zich op de positie bevinden die door de bovenstaande formule wordt aangegeven.
- Als het resultaat van de formule een getal met een decimaal deel is, wordt de kwartielwaarde berekend met behulp van de volgende formule:

Waar x i en x i+1 de getallen zijn van de posities waartussen het getal verkregen door de eerste formule zich bevindt, en d het decimale deel is van het getal verkregen door de eerste formule.
decielen
In de statistieken zijn decielen de negen waarden die een reeks geordende gegevens in tien gelijke delen verdelen. Zodat het eerste, tweede, derde,… deciel 10%, 20%, 30%,… van de steekproef of populatie vertegenwoordigt.
Decielen worden weergegeven door de hoofdletter D en de decielindex, dat wil zeggen, het eerste deciel is D 1 , het tweede deciel is D 2 , het derde deciel is D 3 , enz.
De decielformule is als volgt:

Let op: deze formule vertelt ons de positie van het deciel, niet de waarde van het deciel. Het deciel bestaat uit de gegevens die zich bevinden op de positie die door de formule wordt verkregen.
Soms geeft het resultaat van deze formule ons echter een decimaal getal. We moeten daarom twee gevallen onderscheiden, afhankelijk van of het resultaat een decimaal getal is of niet:
- Als het resultaat van de formule een getal is zonder een decimaal deel , bestaat het deciel uit de gegevens die zich bevinden op de positie die wordt geboden door de bovenstaande formule.
- Als het resultaat van de formule een getal met een decimaal deel is, wordt de decielwaarde berekend met behulp van de volgende formule:

Waar x i en x i+1 de getallen zijn van de posities waartussen het getal verkregen door de eerste formule zich bevindt, en d het decimale deel is van het getal verkregen door de eerste formule.
percentielen
In de statistieken zijn percentielen de waarden die een reeks geordende gegevens in honderd gelijke delen verdelen. Een percentiel geeft dus de waarde aan waaronder een percentage van de dataset valt.
Percentielen worden weergegeven door de hoofdletter P en de percentielindex, dat wil zeggen dat het eerste percentiel P 1 is, het 40e percentiel P 40 , het 79e percentiel P 79 , enz.
De percentielformule is:

Let op: deze formule vertelt ons de positie van het percentiel, maar niet de waarde ervan. Het percentiel bestaat uit de gegevens die zich bevinden op de positie die door de formule wordt verkregen.
Soms geeft het resultaat van deze formule ons echter een decimaal getal. We moeten daarom twee gevallen onderscheiden, afhankelijk van of het resultaat een decimaal getal is of niet:
- Als het resultaat van de formule een getal zonder decimaal deel is, komt het percentiel overeen met de gegevens die zich in de positie bevinden die door de bovenstaande formule wordt verstrekt.
- Als het resultaat van de formule een getal met een decimaal deel is, wordt de exacte percentielwaarde berekend met behulp van de volgende formule:

Waar x i en x i+1 de getallen zijn van de posities waartussen het getal verkregen door de eerste formule zich bevindt, en d het decimale deel is van het getal verkregen door de eerste formule.
Statistische vormmetingsformules
asymmetriecoëfficiënt
De scheefheidscoëfficiënt, of scheefheidsindex, is een statistische coëfficiënt die wordt gebruikt om de scheefheid van een verdeling te bepalen. Door de asymmetriecoëfficiënt te berekenen, kunt u dus het type asymmetrie van de verdeling kennen zonder dat u er een grafische weergave van hoeft te maken.
De formule voor de asymmetriecoëfficiënt is als volgt:

Op equivalente wijze kan een van de volgende twee formules worden gebruikt om de Fisher-asymmetriecoëfficiënt te berekenen:

![\displaystyle\gamma_1=\frac{\operatorname{E}[X^3] - 3\cdot \overline{x}\cdot \sigma^2 - \overline{x}^3}{\sigma^3}](https://statorials.org/wp-content/ql-cache/quicklatex.com-b58aae86c4d7f8fec18ef689ec08c5db_l3.png "Rendered by QuickLaTeX.com")
Goud

is de wiskundige verwachting,

het rekenkundig gemiddelde,

de standaarddeviatie en
het totale aantal gegevens.
kurtosis-coëfficiënt
Kurtosis, ook wel scherpte genoemd, geeft aan hoe geconcentreerd een verdeling rond het gemiddelde is. Met andere woorden, kurtosis geeft aan of een verdeling steil of vlak is. Concreet geldt: hoe groter de kurtosis van een verdeling, hoe steiler (of scherper) deze is.
De formule voor de kurtosis-coëfficiënt is als volgt:

Goud
is de waarde die overeenkomt met de waarneming
,
het rekenkundig gemiddelde,
de standaarddeviatie en
het totale aantal gegevens.
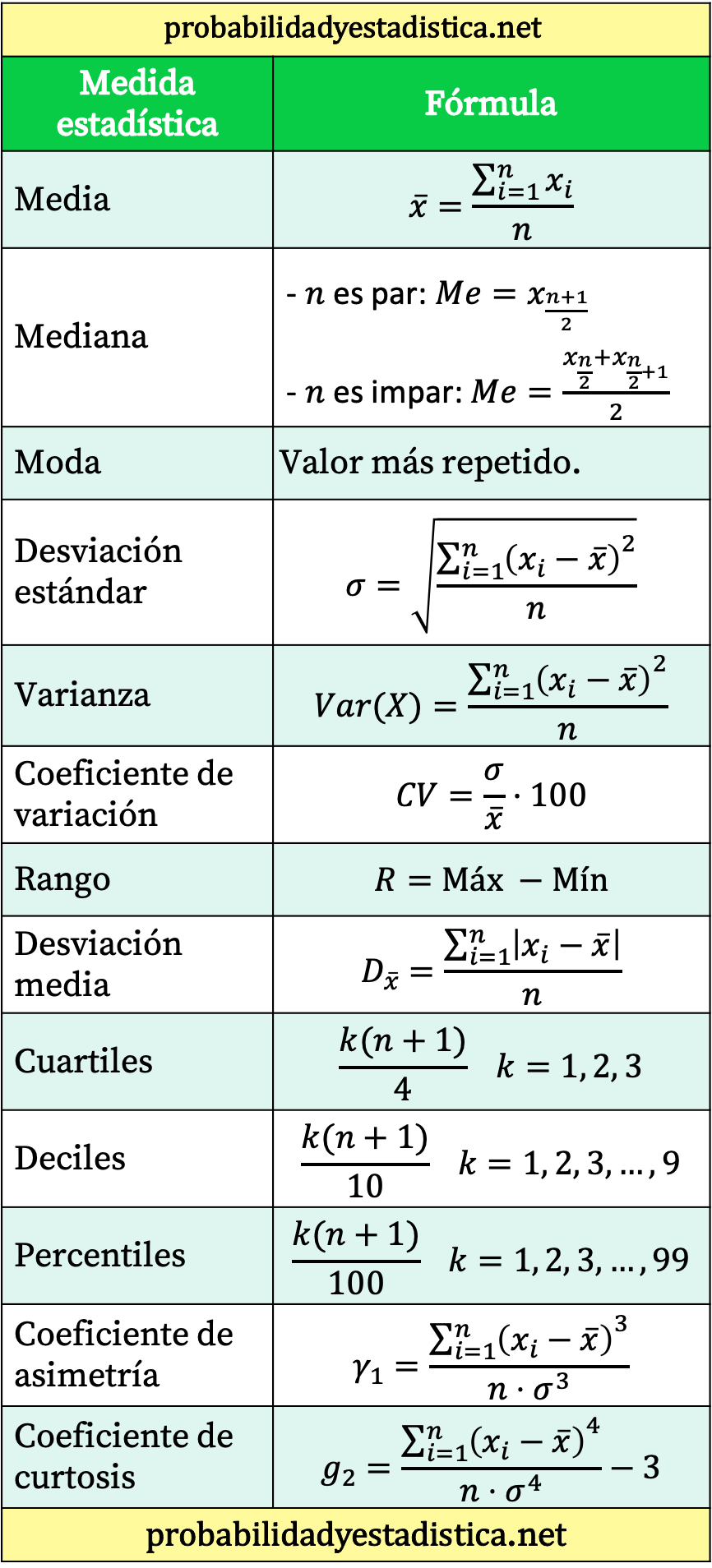
Overzichtstabel van alle statistische formules
Ten slotte laten we u een tabel achter die de belangrijkste statistische formules samenvat.
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder