Univariate analyse uitvoeren in python: met voorbeelden
De term univariate analyse verwijst naar de analyse van één variabele. U kunt dit onthouden omdat het voorvoegsel “uni” “één” betekent.
Er zijn drie veelgebruikte manieren om univariate analyses op een variabele uit te voeren:
1. Samenvattende statistieken – Meet het centrum en de verdeling van waarden.
2. Frequentietabel – Beschrijft hoe vaak verschillende waarden verschijnen.
3. Grafieken – Wordt gebruikt om de verdeling van waarden te visualiseren.
Deze zelfstudie biedt een voorbeeld van hoe u univariate analyses uitvoert met de volgende panda’s DataFrame:
import pandas as pd #createDataFrame df = pd. DataFrame ({' points ': [1, 1, 2, 3.5, 4, 4, 4, 5, 5, 6.5, 7, 7.4, 8, 13, 14.2], ' assists ': [5, 7, 7, 9, 12, 9, 9, 4, 6, 8, 8, 9, 3, 2, 6], ' rebounds ': [11, 8, 10, 6, 6, 5, 9, 12, 6, 6, 7, 8, 7, 9, 15]}) #view first five rows of DataFrame df. head () points assists rebounds 0 1.0 5 11 1 1.0 7 8 2 2.0 7 10 3 3.5 9 6 4 4.0 12 6
1. Bereken samenvattende statistieken
We kunnen de volgende syntaxis gebruiken om verschillende samenvattende statistieken voor de variabele „punten“ in het DataFrame te berekenen:
#calculate mean of 'points' df[' points ']. mean () 5.706666666666667 #calculate median of 'points' df[' points ']. median () 5.0 #calculate standard deviation of 'points' df[' points ']. std () 3.858287308169384
2. Maak een frequentietabel
We kunnen de volgende syntaxis gebruiken om een frequentietabel te maken voor de variabele ‚punten‘:
#create frequency table for 'points' df[' points ']. value_counts () 4.0 3 1.0 2 5.0 2 2.0 1 3.5 1 6.5 1 7.0 1 7.4 1 8.0 1 13.0 1 14.2 1 Name: points, dtype: int64
Dit vertelt ons dat:
- De waarde 4 verschijnt 3 keer
- De waarde 1 verschijnt tweemaal
- De waarde 5 verschijnt tweemaal
- De waarde 2 verschijnt 1 keer
Enzovoort.
Gerelateerd: Frequentietabellen maken in Python
3. Maak grafieken
We kunnen de volgende syntaxis gebruiken om een boxplot te maken voor de variabele ‚points‘:
import matplotlib. pyplot as plt df. boxplot (column=[' points '], grid= False , color=' black ')
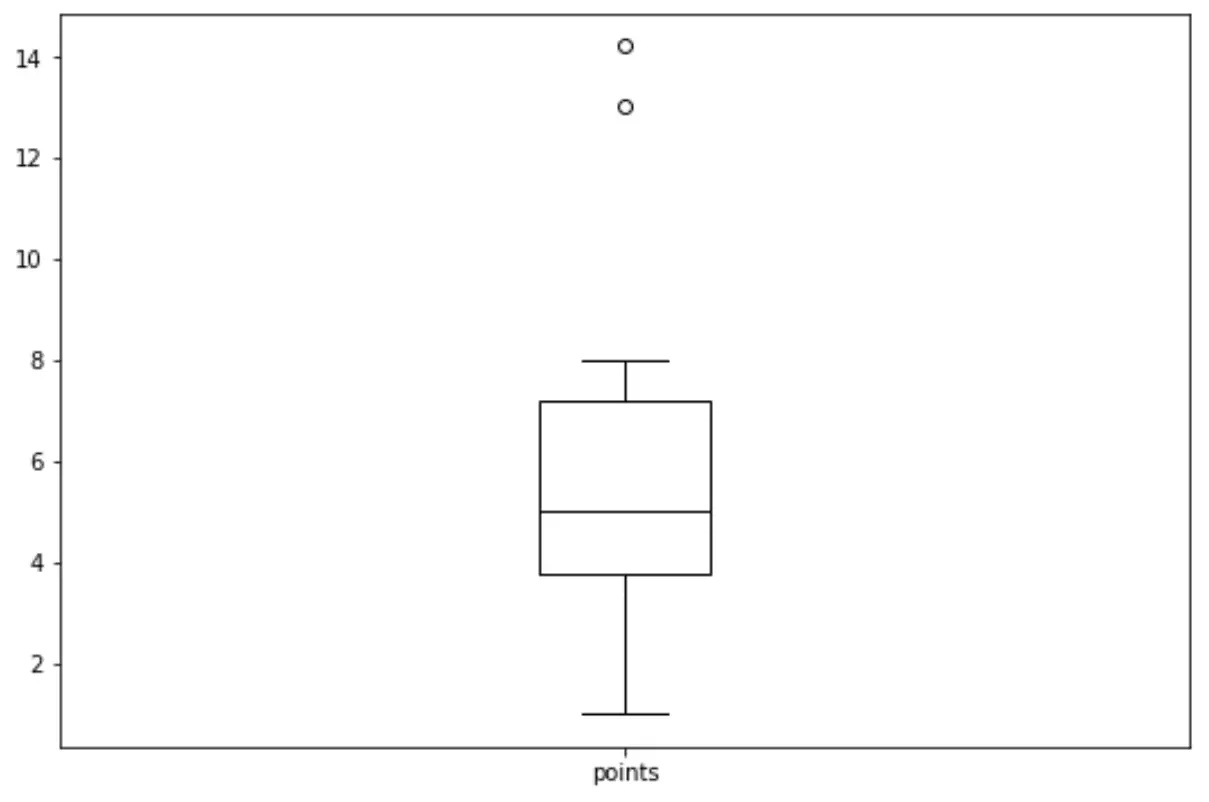
Gerelateerd: Een boxplot maken vanuit Pandas DataFrame
We kunnen de volgende syntaxis gebruiken om een histogram te maken voor de variabele ‚punten‘:
import matplotlib. pyplot as plt df. hist (column=' points ', grid= False , edgecolor=' black ')
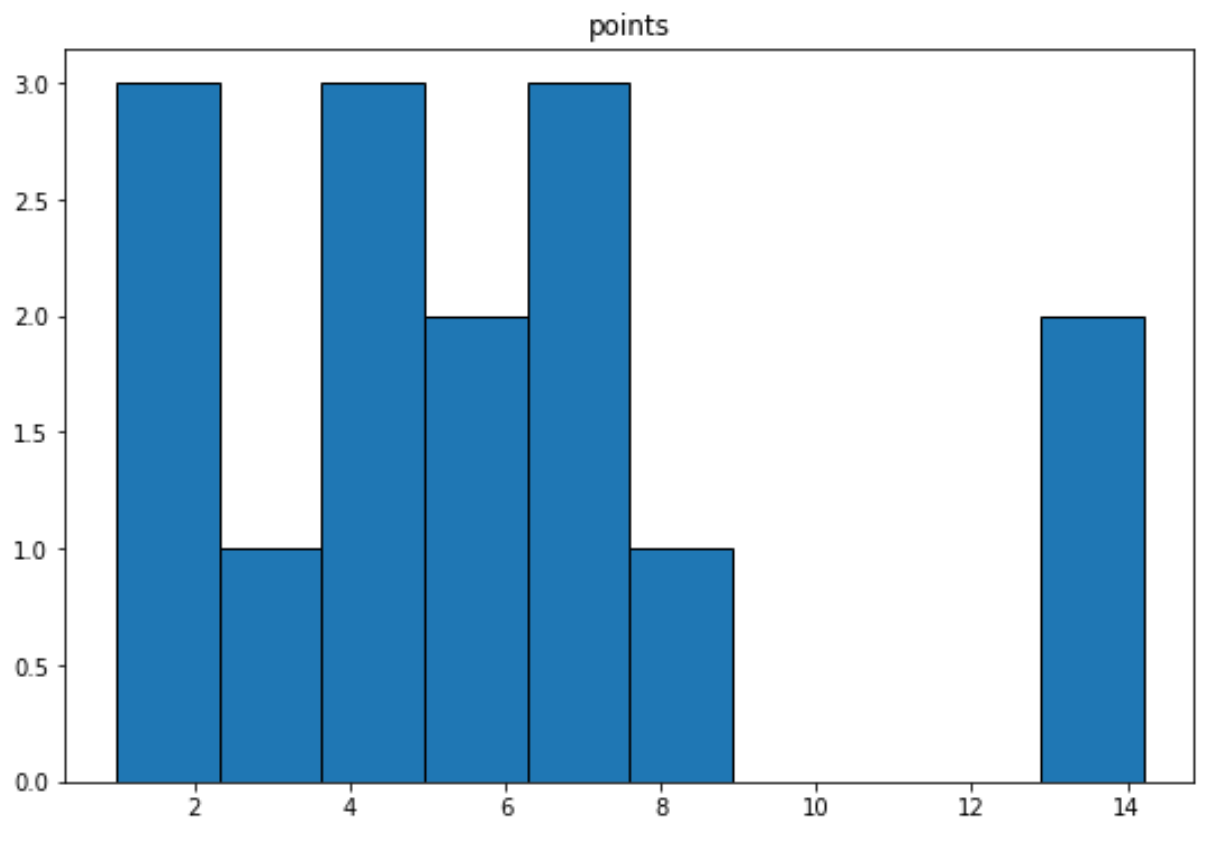
Gerelateerd: Een histogram maken van Pandas DataFrame
We kunnen de volgende syntaxis gebruiken om een dichtheidscurve te maken voor de variabele “punten”:
import seaborn as sns sns. kdeplot (df[' points '])
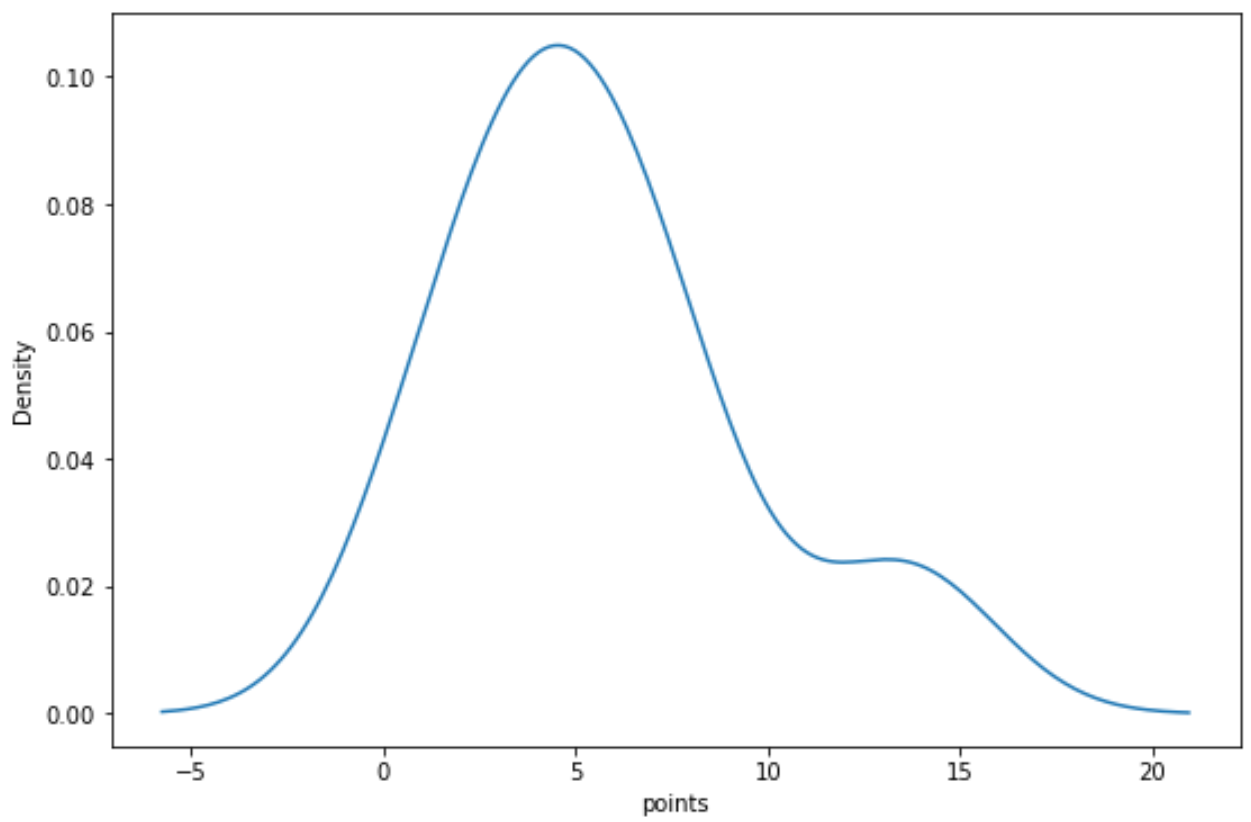
Gerelateerd: Hoe u een dichtheidsplot maakt in Matplotlib
Elk van deze grafieken biedt ons een unieke manier om de verdeling van de waarden van de variabele “punten” te visualiseren.
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder