Variantie van gegroepeerde gegevens vinden (met voorbeeld)
Vaak willen we de variantie van een gegroepeerde frequentieverdeling berekenen.
Stel dat we bijvoorbeeld de volgende gegroepeerde frequentieverdeling hebben:
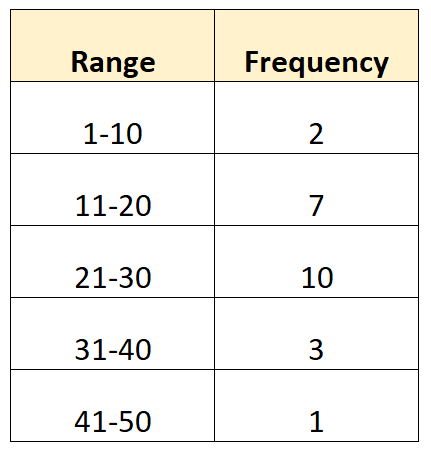
Hoewel het niet mogelijk is om de exacte variantie te berekenen, omdat we de ruwe gegevenswaarden niet kennen, is het mogelijk om de variantie te schatten met behulp van de volgende formule:
Variantie: Σn ik ( mi -μ) 2 / (N-1)
Goud:
- n i : De frequentie van de i- de groep
- mi : Het midden van de i- de groep
- µ : Het gemiddelde
- N: De totale steekproefomvang
Opmerking: het middelpunt van elke groep kan worden gevonden door het gemiddelde te nemen van de onderste en bovenste waarden van het bereik. Het middelpunt van de eerste groep wordt bijvoorbeeld als volgt berekend: (1+10) / 2 = 5,5.
Het volgende voorbeeld laat zien hoe u deze formule in de praktijk kunt gebruiken.
Voorbeeld: Bereken de variantie van gegroepeerde gegevens
Stel dat we de volgende gegroepeerde gegevens hebben:
Zo zouden we de eerder genoemde formule gebruiken om de variantie van deze gegroepeerde gegevens te berekenen:
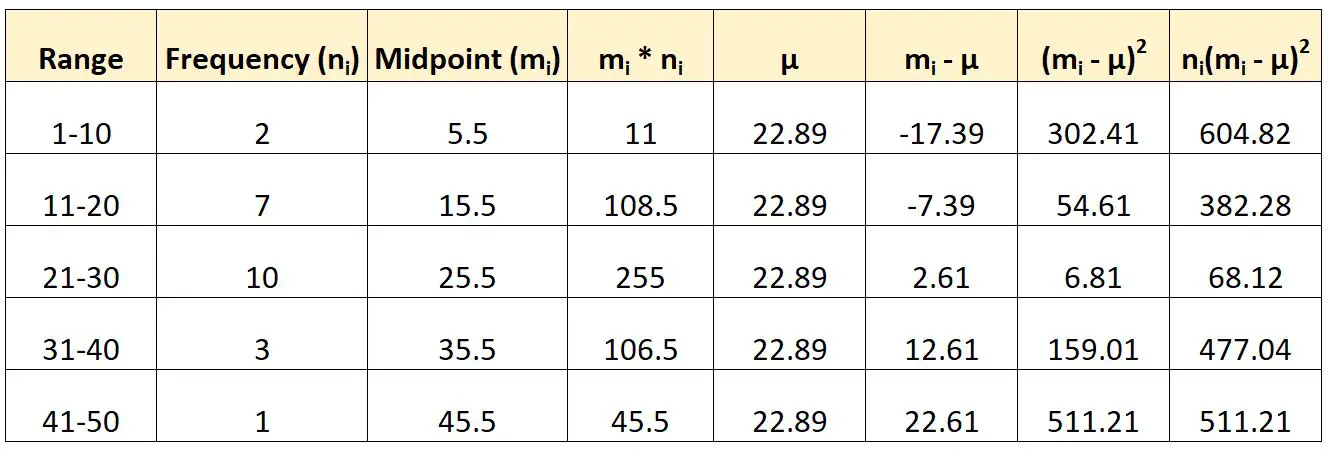
We berekenen de variantie dan als volgt:
- Variantie: Σn ik ( mi -μ) 2 / (N-1)
- Verschil : (604,82 + 382,28 + 68,12 + 477,04 + 511,21) / (23-1)
- Verschil : 92.885
De variantie van de dataset blijkt 92,885 te zijn.
Aanvullende bronnen
In de volgende tutorials wordt uitgelegd hoe u andere statistieken voor gegroepeerde gegevens kunt berekenen:
Hoe u het gemiddelde en de standaardafwijking van gegroepeerde gegevens kunt vinden
Hoe u de percentielrangschikking voor gegroepeerde gegevens kunt berekenen
Hoe u de mediaan van gegroepeerde gegevens kunt vinden
Hoe de gegroepeerde gegevensmodus te vinden
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder